window10单机安装storm集群
适合范围:storm自由开源的分布式实时计算系统,擅长处理海量数据。适合处理实时数据而不是批处理。
安装前的准备
1.安装zookeeper
①下载zookeeperhttps://zookeeper.apache.org/,点击download进入新页面之后,--->download,选择一个镜像文件下载到本地;
②下面是我选择的文件http://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ ,下载的版本是zookeeper-3.4.14;
③解压后复制D:\******\zookeeper-3.4.14\conf\zoo_sample.cfg,并将其命名为zoo.cfg,打开zoo.cfg,将dataDir=/tmp/zookeeper修改为
dataDir=D:\\***\\zookeeper-3.4.\\data
dataLogDir=D:\\***\\zookeeper-3.4.\\log
其中,***为省略的路径。
④配置环境变量(可省略,在指定目录下⑤,启动即可)
⑤进入D:\******\zookeeper-3.4.14\bin\,启动zookeeper。
zkServer.cmd
2.安装python
①下载https://www.python.org/,选择download,进入新页面--->Files--->Windows x86-64 web-based installer,下载到本地;
②点击安装包,安装到指定目录D:\***\python-3.7.3;
3.安装storm
①点击http://storm.apache.org/downloads.html,点击右上角download,选择apache-storm-1.2.2.tar.gz下载到本地;
②解压
③配置环境变量(可省略,在指定文件夹下启动即可。)
④D:\***\apache-storm-1.2.2\bin\storm-config.cmd
⑤修改配置文件D:\***\apache-storm-1.2.2\conf\storm.yaml
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. ########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- "127.0.0.1"
# - "server2"
#
# nimbus.seeds: ["host1", "host2", "host3"]
nimbus.seeds: ["127.0.0.1"]
#
#
# ##### These may optionally be filled in:
#
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2" ## Metrics Consumers
## max.retain.metric.tuples
## - task queue will be unbounded when max.retain.metric.tuples is equal or less than .
## whitelist / blacklist
## - when none of configuration for metric filter are specified, it'll be treated as 'pass all'.
## - you need to specify either whitelist or blacklist, or none of them. You can't specify both of them.
## - you can specify multiple whitelist / blacklist with regular expression
## expandMapType: expand metric with map type as value to multiple metrics
## - set to true when you would like to apply filter to expanded metrics
## - default value is false which is backward compatible value
## metricNameSeparator: separator between origin metric name and key of entry from map
## - only effective when expandMapType is set to true
# topology.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingMetricsConsumer"
# max.retain.metric.tuples:
# parallelism.hint:
# - class: "org.mycompany.MyMetricsConsumer"
# max.retain.metric.tuples:
# whitelist:
# - "execute.*"
# - "^__complete-latency$"
# parallelism.hint:
# argument:
# - endpoint: "metrics-collector.mycompany.org"
# expandMapType: true
# metricNameSeparator: "." ## Cluster Metrics Consumers
# storm.cluster.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingClusterMetricsConsumer"
# - class: "org.mycompany.MyMetricsConsumer"
# argument:
# - endpoint: "metrics-collector.mycompany.org"
#
# storm.cluster.metrics.consumer.publish.interval.secs: # Event Logger
# topology.event.logger.register:
# - class: "org.apache.storm.metric.FileBasedEventLogger"
# - class: "org.mycompany.MyEventLogger"
# arguments:
# endpoint: "event-logger.mycompany.org" # Metrics v2 configuration (optional)
#storm.metrics.reporters:
# # Graphite Reporter
# - class: "org.apache.storm.metrics2.reporters.GraphiteStormReporter"
# daemons:
# - "supervisor"
# - "nimbus"
# - "worker"
# report.period:
# report.period.units: "SECONDS"
# graphite.host: "localhost"
# graphite.port:
#
supervisor.slots.ports:
-
-
-
-
storm.local.dir: "D:\\****\\storm"
ui.port:
# # Console Reporter
# - class: "org.apache.storm.metrics2.reporters.ConsoleStormReporter"
# daemons:
# - "worker"
# report.period:
# report.period.units: "SECONDS"
# filter:
# class: "org.apache.storm.metrics2.filters.RegexFilter"
# expression: ".*my_component.*emitted.*"
⑥启动storm,分别启动nimbus,supervisor,ui【需要打开三个窗口输入命令】
进入D:\***\apache-storm-1.2.2\bin
storm.py nimbus
storm.py supervisor
storm.py ui
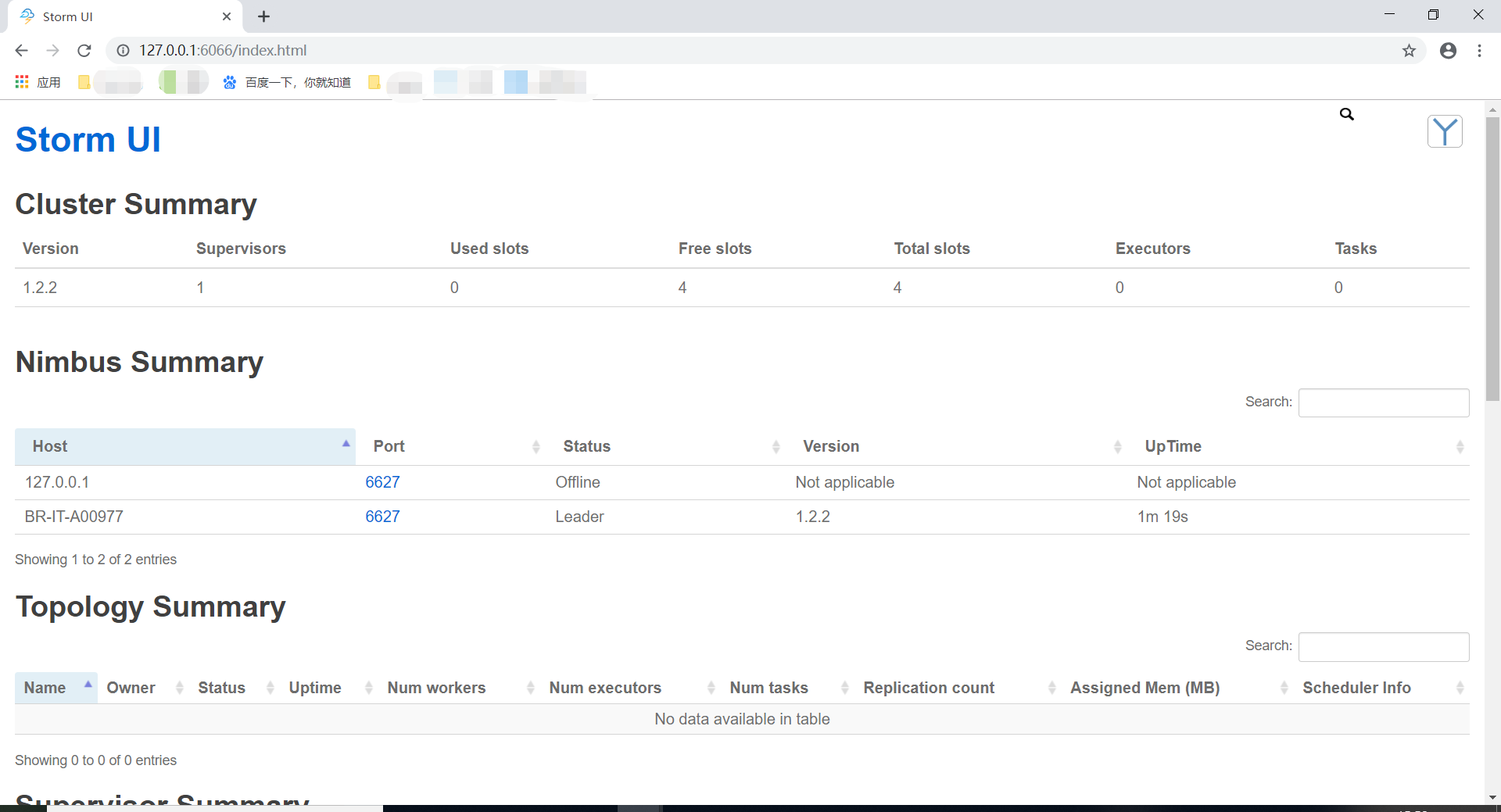
⑦依次启动完毕之后,在浏览器输入http://127.0.0.1:6066/访问【访问UI的端口号可自定义,在上述文件中修改即可】
ui.port:
⑧启动页面
window10单机安装storm集群的更多相关文章
- CentOS6.5 安装Storm集群
1.首先安装依赖包 [root@Hadoop-NN-01 ~]# yum install uuid* [root@Hadoop-NN-01 ~]# yum install libuuid [root@ ...
- Redis单机安装以及集群搭建
今天主要来看一下Redis的安装以及集群搭建(我也是第一次搭建). 环境:CentOS 7.1,redis-5.0.7 一.单机安装 1.将Redis安装包放置服务器并解压 2.进入redis安装目录 ...
- Ubuntu 下 Neo4j单机安装和集群环境安装
1. Neo4j简介 Neo4j是一个用Java实现的.高性能的.NoSQL图形数据库.Neo4j 使用图(graph)相关的概念来描述数据模型,通过图中的节点和节点的关系来建模.Neo4j完全兼容A ...
- redhat6.4安装storm集群-4节点
0.搭建ftp服务器并建立yum源 1.在每个节点上安装java并设置环境变量 2.在三个节点上安装zookeeper 3.安装zeromq 过程中发现运行./configure时出现问题: conf ...
- Elasticsearch单机安装_集群搭建_索引基本操作_Head插件安装与基本操作_ik分词器配置_logstash实现数据同步_教程
一.Elasticsearch单机安装 1.将es安装包传到服务器上 这是安装包 这里我是用的是WinSCP上传工具,上传到/home/plugins文件下. 进入Xshell,验证一下是否上传成功. ...
- 单机安装hadoop集群
一 .安装前准备 1.VMware虚拟内容 2.Linux系统 (CentOS-6.9-min) 镜像文件http://vault.centos.org/ 3.jdk 1.8 rpm或bin文件 ht ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm集群的安装与测试
首先安装zookeeper集群,然后安装storm集群. 我使用的是centos 32bit的三台虚拟机. MachineName ip namenode 192.168.99.110 datanod ...
- Storm集群安装部署步骤
本文以Twitter Storm官方Wiki为基础,详细描述如何快速搭建一个Storm集群,其中,项目实践中遇到的问题及经验总结,在相应章节以"注意事项"的形式给出. 1. Sto ...
随机推荐
- 2、CentOS下编译安装Python2.7.6(转)
CentOS系统下面Python在升级到2.7.6的时候,没有找到安装包直接安装,只能通过源代码编译的方式来安装Python 2.7.6版本.这篇是编译和安装Python2.7.6的过程记录. Cen ...
- rtp传输音视频(纯c代码)
参考链接: 1. PES,TS,PS,RTP等流的打包格式解析之RTP流 https://blog.csdn.net/appledurian/article/details/73135343 2. ...
- centos7初上手3-安装apache服务
前两篇学习安装了mysql服务器,tomcat服务,这篇文章学习安装apache服务 1.执行yum install httpd,安装完成后查看httpd rpm -qa|grep httpd 2.新 ...
- angular $resouse服务
创建服务 var taskInstancesResource = function ($resource) { var resource = $resource('/ssc-cutover/rest/ ...
- maven快速自动更新子模块项目的版本号
当一个版本发布,新起一个版本时,我们需要更改一下项目中的版本号.一个maven工程,如果只是一个单一的主项目,那么只要手动修改一下 pom.xml 就 可以了,耗不了多少时间.但是如果这个maven项 ...
- .NET MVC+angular导入导出
cshtml: <form class="form-horizontal" id="form1" role="form" ng-sub ...
- 常用的数学函数-S
// abs — 获取[数值]的绝对值 $; echo abs($int).'<br>'; $float=-2.34; echo abs($float).'<hr>'; //c ...
- 解决linux root 认证失败的问题
https://jingyan.baidu.com/article/3052f5a1f1b17c97f31f8688.html
- Node.js和html数据交互(一) form表单
一.form表单提交数据 数据流向:前端 - > 后端 1.get方法 (action是提交路径,method是提交方法,get方法可以不写) 前端: <form action=" ...
- SpringCloud----熔断机制 -- 断路器hystrix
参考借鉴:http://www.cnblogs.com/chry/p/7279856.html SpringCloud Netflix实现了断路器库的名字叫Hystrix. 在微服务架构下,通常会有多 ...