Python介绍RabbitMQ使用篇二WorkQueue
1. RabbitMQ WorkQueue基本工作模式介绍
上一篇我们使用C#语言讲解了单个消费者从消息队列中处理消息的模型,这一篇我们使用Python语言来讲解多个消费者同时工作从一个Queue处理消息的模型。

工作队列(又称:任务队列——Task Queues)是为了避免等待一些占用大量资源、时间的操作。当我们把任务(Task)当作消息发送到队列中,一个运行在后台的工作者(worker)进程就会取出任务然后处理。当你运行多个工作者(workers),任务就会在它们之间共享。这个概念在网络应用中是非常有用的,它可以在短暂的HTTP请求中处理一些复杂的任务,我么可以将耗时的请求放在任务队列,然后立马返回响应,接下来由多个worker去处理复杂的业务操作。(这种架构叫做"分布式异步队列",有时候用来方式D-DOS攻击,12306网站就是采用这种模式)
用Python操作Python模块首先要到如pika这个包,利用pip install pika去安装。
我们首先写一个new_task.py用来向任务队列中写入任务,已备用。
- import pika
- import sys
- with pika.BlockingConnection(pika.connection.ConnectionParameters(host="localhost")) as connection:
- channel = connection.channel()
- channel.queue_declare(queue = "hello")
- for index in range(0,10):
- channel.basic_publish(exchange="",
- routing_key="hello",
- body="["+str(index)+"]" + "Hello World")
- connection.close()
接下来编写works.py程序,我们需要在works.py中创建消费者,让消费者从任务队列中提取任务去执行。
- import pika
- import sys
- import time
- connection = pika.BlockingConnection(pika.connection.ConnectionParameters(host="localhost"))
- channel = connection.channel()
- channel.queue_declare(queue = "hello")
- channel.basic_ack()
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % (body.decode('utf-8'),))
- time.sleep(3) # 我们在这里利用线程休息来模拟一个比较耗时的任务处理
- print(" [x] Done")
- channel.basic_consume(callback,
- queue='hello',
- no_ack= True) # 我们把no_ack标记为true用来屏蔽消息确认
- channel.start_consuming()
- connection.close()
在callback函数中让当前线程休息5秒用来模拟一个耗时的任务。
接下来首先打开两个Terminal窗口同时去运行works.py程序,然后运行new_task.py程序来查看效果。注意:在这里为了说明多个work能够同时分享任务队列中的队列,我们一定要先运行works.py,后运行new_task.py程序。具体原因后面在说明。
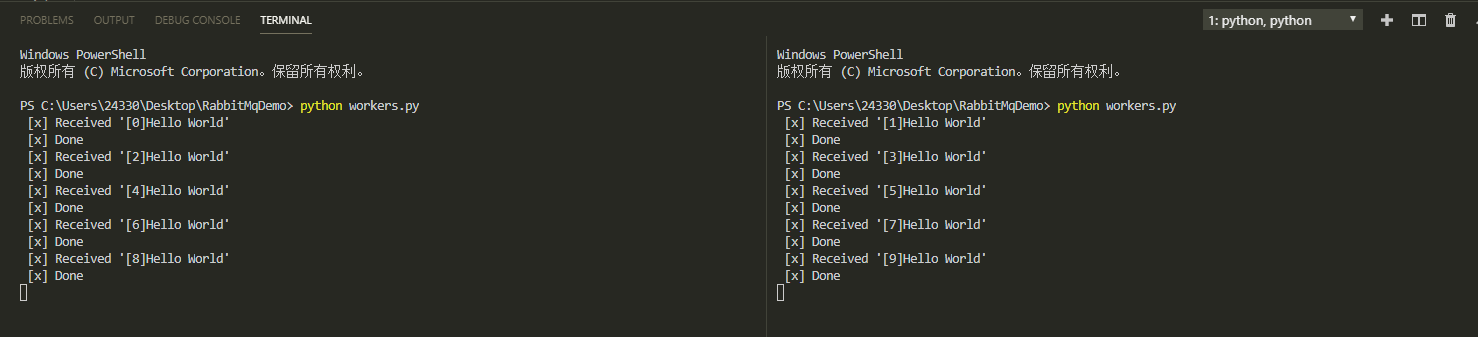
默认来说,RabbitMQ会按顺序得把消息发送给两个消费者(consumer),平均每个消费者都会收到同等数量得消息,这种发送消息的方式叫做——轮询(round-robin)。这样做的好处就是我们在处理相同数量的task所用的时间成倍的减少了。work越多,我们处理任务队列所用的时间就越少,这在高并发系统中会非常有用。
2.消息确认
当前的代码中,当消息被RabbitMQ发送给消费者(consumers)之后,马上就会在内存中移除。这种情况之下,假如其中一个工作者挂掉了,那么它正在处理的消息就会丢失,并且与此同时,后面所有发送到这个工作者的还没来得及处理的消息也都会丢失。这显然不是我们想看到的结果。我们不想丢失任何消息,如果一个工作者(worker)挂掉了,我们希望任务会重新发送给其他的工作者(worker)。
为了防止消息丢失,RabbitMQ提供了消息响应(acknowledgments)。消费者会通过一个ack(响应),告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ才会释放并删除这条消息,而不是这条消息一发送出去马上就从内存中删除。
如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,及时工作者(workers)偶尔的挂掉,也不会丢失消息。消息是没有超时这个概念的;当工作者与它断开连的时候,RabbitMQ会重新发送消息。这样在处理一个耗时非常长的消息任务的时候就不会出问题了。消息响应默认是开启的。之前的例子中我们可以使用no_ack=True标识把它关闭。接下来我们移除这个标识,当工作者(worker)完成了任务,就发送一个响应。
对我们的workers.py稍微进行一下改动:
- import pika
- import sys
- import time
- connection = pika.BlockingConnection(pika.connection.ConnectionParameters(host="localhost"))
- channel = connection.channel()
- channel.queue_declare(queue = "hello")
- channel.basic_ack()
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % (body.decode('utf-8'),))
- time.sleep(3)
- print(" [x] Done")
- ch.basic_ack(delivery_tag = method.delivery_tag) # 2. channel.basic_ack()方法用来执行消息确认操作
- channel.basic_consume(callback,
- queue='hello',
- no_ack= False) # 1. no_ack告诉RabbitMQ开启消息确认机制,也就是说消息需要被确认
- channel.start_consuming()
- connection.close()
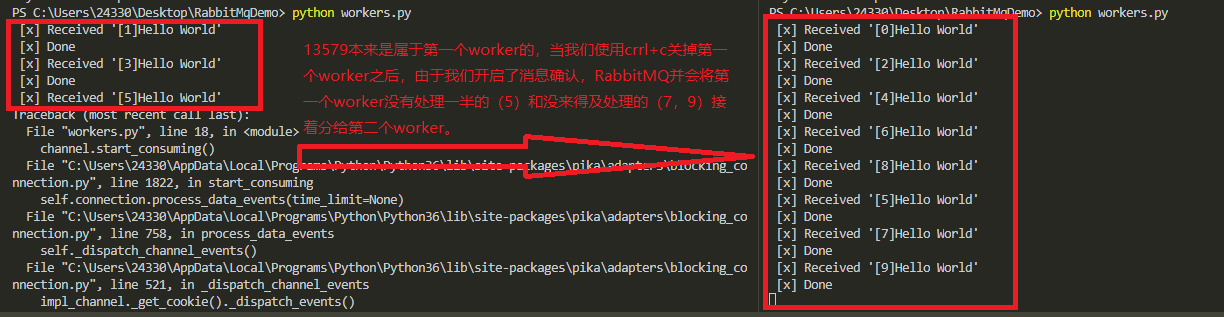
先开启两个Terinmal窗口执行workers.py然后执行new_task.py,当执行一半是利用ctrl+c关掉其中一个worker。可以看到RabbitMQ将已经关掉的worker的没来得及处理的消息,再一次发给worker2。以此保证消息不会丢失。
一定一定不要忘记消息确认
在回调方法中一定要记得调用channel.basic_ack()方法用来确认消息。原因很容易理解,消息如果不确认,任务就算是被callback函数处理成功了,RabbitMQ在内存中也不会删除这条任务,这条任务还会停留在内存中。这样无疑会带来一个比较大的bug。
3.消息持久化
RabbittMQ如果意外崩溃的话,就会丢失所有的“队列”和“消息”。因此为了确保信息不会丢失,有两个事情是需要注意的:我们必须把“队列”和“消息”设为持久化。下面的代码分别演示了如何进行队列持久化和消息持久化。
- import pika
- import sys
- with pika.BlockingConnection(pika.connection.ConnectionParameters(host="localhost")) as connection:
- channel = connection.channel()
- channel.queue_declare(queue = "hello",durable=True) # 1.Queue持久化
- for index in range(0,10):
- channel.basic_publish(exchange="",
- routing_key="hello",
- body="["+str(index)+"]" + "Hello World",
- properties= pika.BasicProperties( # 2.消息持久化
- delivery_mode= 2
- ))
- connection.close()
4.公平调度/多劳多得
在实际生产中我们不一定所有的任务处理时都消耗同样多的时间,有的任务需要更长的时间,有的任务需要比较少的时间。这样就造成有的工作者比较繁忙,有的工作者比较轻松。然而RabbitMQ并不知道这些,它仍然一如既往的派发消息。这样无疑会造成资源的浪费。
这时因为RabbitMQ只管分发进入队列的消息,不会关心有多少消费者(consumer)没有作出响应。它盲目的把第n-th条消息发给第n-th个消费者。

我们可以使用basic.qos方法,并设置prefetch_count=1。这样是告诉RabbitMQ,再同一时刻,不要发送超过1条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。这样能保证消息是一个一个发出去的,并且是一个处理完成了再发另一个,而不是一次性全部发分出去了。这样尽可能的保证了每个worker的工作时间相同(公平调度),并且在相同时间执行效率高的worker会分享到更多的消息(多劳多得)。
channe.basic_qos(prefetch_count=1)
当然,如果所有的worker都长时间处于繁忙状态,没有时间接收下一条消息,那么任务队列就有可能满了。我们可以增加worker的数量,或者想其他办法。
代码整合
- import pika
- import sys
- with pika.BlockingConnection(pika.connection.ConnectionParameters(host="localhost")) as connection:
- channel = connection.channel()
- channel.queue_declare(queue = "hello",durable = True) # 1.Queue持久化
- for index in range(0,10):
- channel.basic_publish(exchange="",
- routing_key="hello",
- body="["+str(index)+"]" + "Hello World",
- properties= pika.BasicProperties( # 2.消息持久化
- delivery_mode= 2
- ))
- connection.close()
new_task.py
- import pika
- import sys
- import time
- connection = pika.BlockingConnection(pika.connection.ConnectionParameters(host="localhost"))
- channel = connection.channel()
- channel.queue_declare(queue = "hello",durable = True) # 队列持久化
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % (body.decode('utf-8'),))
- time.sleep(5)
- print(" [x] Done----%r" % time.strftime("%Y-%m-%d %X",time.localtime()))
- ch.basic_ack(delivery_tag = method.delivery_tag)
- channel.basic_qos(prefetch_count = 1) # 用来告诉每个worker一次只能接受一条消息
- channel.basic_consume(callback,
- queue='hello',
- no_ack = False)
- channel.start_consuming()
- connection.close()
workers_busy
- import pika
- import sys
- import time
- connection = pika.BlockingConnection(pika.connection.ConnectionParameters(host="localhost"))
- channel = connection.channel()
- channel.queue_declare(queue = "hello")
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % (body.decode('utf-8'),))
- time.sleep(1)
- print(" [x] Done----%r" % time.strftime("%Y-%m-%d %X",time.localtime()))
- ch.basic_ack(delivery_tag = method.delivery_tag)
- channel.basic_qos(prefetch_count = 1)
- channel.basic_consume(callback,
- queue='hello',
- no_ack = False)
- channel.start_consuming()
- connection.close()
workers_relax.py
Python介绍RabbitMQ使用篇二WorkQueue的更多相关文章
- C#介绍RabbitMQ使用篇一HelloWorld
RabbitMQ官网官方介绍: 译文: RabbitMQ是目前部署最广泛的开源消息代理(何为代理?可以理解为一个提供功能服务的中间件). 在全球范围内的大小企业中的生产环境中,RabbitMQ的部署两 ...
- python 学习之 基础篇二 字符编码
声明: 博文参考1:字符编码发展历程(ASCII,Unicode,UTF-8) 博文参考2:Python常见字符编码间的转换 (1)为什么要用字符编码 早期的计算机使用的是通电与否的特性的真空管,如果 ...
- Python操作rabbitmq系列(二):多个接收端消费消息
今天,我们要逐步开始讨论rabbitmq稍微高级点的耍法了.了解这一步,对我们设计高并发的系统非常有用.当然,还可以使用kafka.不过还是算了,有几个硬性条件不支持,还是用rabbitmq吧. 循环 ...
- python剑指网络篇二
在socket编程中 AF_INET 对应 IPv4 SOCK_STREAM 对应 TCP SOCK_DGRAM 对应 UDP
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- Python全栈开发之路 【第一篇】:Python 介绍
本节内容 一.Python介绍 python的创始人为荷兰人——吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本 ...
- 二、python介绍
python第一篇-------python介绍 一.python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,Guido开始写Python语 ...
- 【python自动化第一篇:python介绍与入门】
一.python介绍以及发展史 1.1 python的介绍: 简单点来说吧,python这玩意儿是一个叫做Guido van Rossum的程序猿在1989年的圣诞打发时间而决心去开发的一个脚本编程 ...
- python【第十一篇】消息队列RabbitMQ、缓存数据库Redis
大纲 1.RabbitMQ 2.Redis 1.RabbitMQ消息队列 1.1 RabbitMQ简介 AMQP,即Advanced Message Queuing Protocol,高级消息队列协议 ...
随机推荐
- macOS 上编译 Dynamips
Dynamips 是一个Cisco 路由器模拟软件. 安装过程: git clone git://github.com/GNS3/dynamips.git cd dynamips mkdir buil ...
- Stacking:Catboost、Xgboost、LightGBM、Adaboost、RF etc
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- maven 构建参数和命令
mvn常用参数 mvn -e 显示详细错误 mvn -U 强制更新snapshot类型的插件或依赖库(否则maven一天只会更新一次snapshot依赖) mvn -o 运行offline模式,不联网 ...
- (转)如何阅读OpenStack源码
1 关于该项目 本项目使用在线绘图工具web sequencediagrams完成,目标是图形化OpenStack的所有操作流程,通过操作序列图能快速学习Openstack的工作原理,理清各个组件的关 ...
- end to end testing
概念 https://www.softwaretestinghelp.com/what-is-end-to-end-testing/ What is “End to End Testing”? Ter ...
- C++中数组作为形参进行传递(转)
有两种传递方法,一种是function(int a[]); 另一种是function(int *a) 这两种两种方法在函数中对数组参数的修改都会影响到实参本身的值! 对于第一种,根据之前所学,形参是实 ...
- 入门嵌入式选择2440?树莓派?STM32?4412开发板?
如果了解一下当前IT和物联网发展的形势,就会发现Android工程师越来越受欢迎,相比之下单纯的Linux工程师却逊色不少,当然,Android系统的内核也是Linux的,Linux和Android作 ...
- Sublime text3 连接sftp/ftp(远程服务器)
1.按下Ctrl + Shift + P调出命令面板2.在输入框中输入Sftp,按回车下载3.建一个新的文件夹放到左边的项目栏中4.右击文件夹,选中SFTP/FTP,点击Map to Remote5. ...
- Windows下的wget,命令行下载url
1.进命令行(Win + R,输入"cmd") 2.输入:start powershell 3.等待PowerShell窗口启动 4.PowerShell窗口依次输入: $clie ...
- 求逆序对常用的两种算法 ----归并排 & 树状数组
网上看了一些归并排求逆序对的文章,又看了一些树状数组的,觉得自己也写一篇试试看吧,然后本文大体也就讲个思路(没有例题),但是还是会有个程序框架的 好了下面是正文 归并排求逆序对 树状数组求逆序对 一. ...