第四章:4.0 python常用的模块
1.模块、包和相关语法
使用模块好处:
- 最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
- 使用模块还可以避免函数名和变量名冲突。每个模块有独立的命名空间,因此相同名字的函数和变量完全可以分别存在不同的模块中,所以,我们自己在编写模块时,不必考虑名字会与其他模块冲突。
- 可重用。
模块分为三种:
- 内置标准模块(又称标准库)执行help('modules')查看所有python自带模块列表
- 第三方开源模块,可通过pip install 模块名 联网安装
- 自定义模块(创建一个.py文件,就可以称之为模块,就可以在另外一个程序里导入)
模块的调用

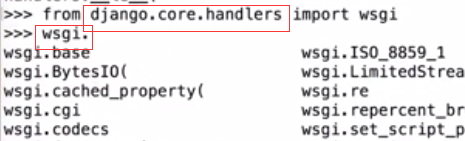
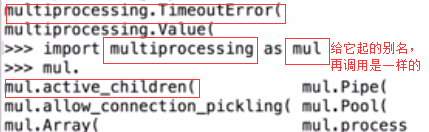
import module
from module import xx ##例如 from os import rmdir,rename
from module.xx.xx import xx as rename
from module.xx.xx import *
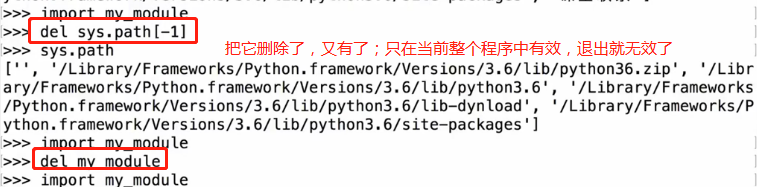
模块一旦被调用,即相当于执行了另外一个py文件里的代码 模块的导入和查找路径
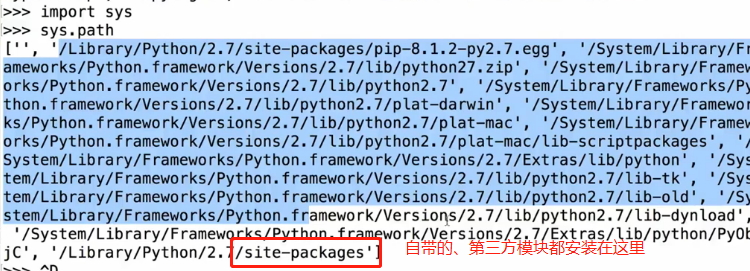
import sys print(sys.path) ['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload',
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
python解释器会按照列表顺序去依次到每个目录下去匹配你要导入的模块名,只要在一个目录下匹配到了该模块名,就立刻导入,不再继续往后找。
注意列表第一个元素为空,即代表当前目录,所以你自己定义的模块在当前目录会被优先导入。


# 本地文件的界定:指向一个本地存储的文件,是一个链接或者一个映射 path1 = 'C:/Users/Hjx/Desktop/text.txt' # 单个反斜杠:/
path2 = 'C:\\Users\\Hjx\\Desktop\\text.txt' # 两个斜杠:\\(第一个\是转义符)
path3 = r'C:\Users\Hjx\Desktop\text.txt' # r用于防止字符转义
# 路径书写格式
print(path1)
print(path2)
print(path3)
打印:
C:/Users/Hjx/Desktop/text.txt
C:\Users\Hjx\Desktop\text.txt
C:\Users\Hjx\Desktop\text.txt
开源模块的安装和使用
https://pypi.python.org/pypi 是python的开源模块库
1.直接在上面这个页面上点download,下载后,解压并进入目录,执行以下命令完成安装
编译源码 python setup.py build
安装源码 python setup.py install
- 直接通过pip安装
pip3 install paramiko #paramiko 是模块名
pip命令会自动下载模块包并完成安装。
软件一般会被自动安装你python安装目录的这个子目录里
/your_python_install_path/3.6/lib/python3.6/site-packages
pip命令默认会连接在国外的python官方服务器下载,速度比较慢,你还可以使用国内的豆瓣源,数据会定期同步国外官网,速度快好多
sudo: pip install -i http://pypi.douban.com/simple/ alex_sayhi --trusted-host pypi.douban.com #alex_sayhi是模块名
2.包(Package)
当你的模块文件越来越多,就需要对模块文件进行划分,比如把负责跟数据库交互的都放一个文件夹,把与页面交互相关的放一个文件夹,
└── my_proj
├── crm #代码目录
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
└── my_proj #配置文件目录
├── settings.py
├── urls.py
└── wsgi.py
像上面这样,一个文件夹管理多个模块文件,这个文件夹就被称为包。 __init__ 把目录初始化成一个包。
my_proj
├── __init__.py
├── crm
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── views.py
├── manage.py
└── proj
├── __init__.py
├── settings.py
├── urls.py
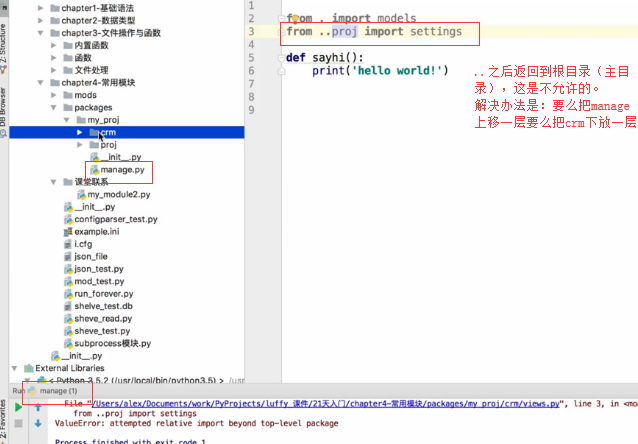
└── wsgi.py##views.py from proj import settings
#我们执行manage.py的时候,它所在的目录已经加到 site-packages这个所谓
#的环境变量里边了,在views里边再去调用的时候,其实我们写的是from proj import settings,
#其实这个proj是在它的上级环境变量里边找到之后再回去找的。sys.path打印列表第一个值是空,程序的那个入口文件的路径是哪个它那个空就是那个
#manage.py就是那个空
#如果先执行views.py,那个空就是views所在的路径,sis.path环境变量里边也没有proj,它再去from proj import settings,会报错说没有这个proj模块。
如果非要先执行views.py,就要进行跨模块导入了。
def sayhi():
print('Hello world!')
跨模块导入
import sys
sys.path.append("C:\\Users\Administrator\PycharmProjects\myFirstpro\chapter4模块的学习\my_proj")#这个是静态路径,右键path它的路径。注意是找my_proj这个路径这样才能from..
##如果加了proj这个路径,它就会自动往里边去找,直接import settings就可以了
#sys.path.append(r"C:\Users\Administrator\PycharmProjects\myFirstpro\chapter4模块的学习\my_proj") ##加r
print(sys.path)
from proj import settings
def sayhi():
print('Hello World!')
import sys,os
print(dir())
print(‘file’,_file_)
BASE_DIR = os.path.dirname(os.path.dirname(_file_))
print(BASE_DIR)
sys.path.append(BASE_DIR) #这个是动态路径 from proj import settings
def sayhi():
print('Hello world!') 打印:
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'os', 'sys']
C:/Users/Administrator/PycharmProjects/myFirstpro/chapter4模块的学习/my_proj/crm/views.py
C:/Users/Administrator/PycharmProjects/myFirstpro/chapter4模块的学习/my_proj
in proj/settings.py
import sys,os
print(dir())
print(‘file’,_file_)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(_file_))) #这是绝对路径,这样在哪里执行都没有问题了
print(BASE_DIR)
sys.path.append(BASE_DIR)
from proj import settings def sayhi():
print('Hello world!')
程序在哪执行,当前路径就是那个,要想导入其他模块就要找到它的路径。
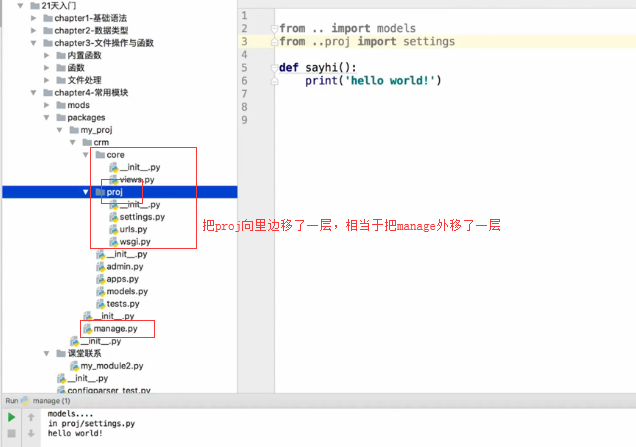
相对导入
├── __init__.py
├── crm
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── views.py
├── manage.py
└── proj
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py #from crm import models
from . import models #from crm import models 这两个是一样的 #. 就叫相对导入,因为它俩在同一级目录 def sayhi():
print('Hello world!')
#执行manage
3.time模块
在python里通常有下面几种表示时间的方式:
- 时间戳:时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串
- 元组(struct_time)共九个元素。返回struct_time的函数主要有gmtime(),localtime(),strptime()。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。这种方式元组中的几种元素:
索引(Index) 属性(Attribute) 值(Values)
tm_year(年) 比如2011
tm_mon(月) -
tm_mday(日) -
tm_hour(时) -
tm_min(分) -
tm_sec(秒) -
tm_wday(weekday) - (0表示周日)
tm_yday(一年中的第几天) -
tm_isdst(是否是夏令时) 默认为-
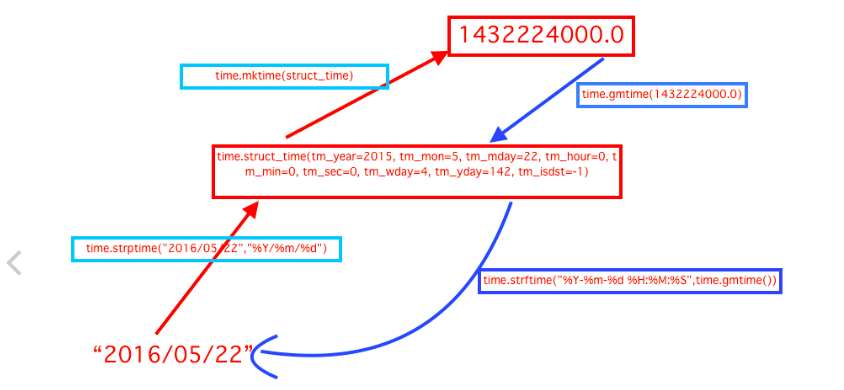
time.localtime()将当前时间转为当前时区的struct_time;wday 0-6表示周日到周六;ydat 1-366 一年中的第几天; isdst 是否为夏令时,默认为-1;
time.gmtime() 、
>>>import time
>>>time.time() #返回当前的时间戳
1507808689.675603 >>>time.localtime() #将一个时间戳转换为当前时区的struct_time
time.struct_time( tm_year=2017, tm_mon=10, tm_mday=12, tm_hour=19, tm_min=45, tm_sec=61, tm_wday=3, tm_yday=285, tm_isdst=0) #打印本地时间 >>>time.gmtime() #将一个时间戳转换为UTC英国时间,比我们晚8个小时
time.struct_time( tm_year=, tm_mon=, tm_mday=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=)
>>>a = time.localtime()
>>>a
time.struct_time( tm_year=, tm_mon=, tm_mday=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=)
字符串的拼接 、 time.mktime()
>>>'%s-%s-%s'%(a.tm_year, a.tm_mon, a.tm_mday) #可以进行拼接
‘--’ >>>time.mktime(a) #将一个struct_time转化为时间戳。
140323242.0
time.asctime() (外国人常使用的时间形式) 、time.ctime()将当前时间转换为一个字符串str
>>>time.asctime() #把一个表示时间的元组或者struct_time表示为这种形式:'Sun Oct 1 12:04:38 2017'。
'Thu Oct 12 19:52:10 2017' >>>time.ctime() #把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。相当于time.asctime(time.localtime(secs))
'Thu Oct 12 19:52:36 2017'
>>>time.ctime()
'Fri Jan 2 18:13:52 1970'
>>>time.ctime()
'Thu Jan 1 08:00:00 1970'
time.sleep(secs):线程推迟指定的时间运行。单位为秒。
time.strftime( ‘%Y-%m-%d %H:%M:%S %A %P %U’ ) 转化为格式化的字符串 time.strptime(s, ‘%Y-%m-%d %H:%M:%S ’ ) 把格式化字符串进行反转为struct_time
time.strftime(a,b) , a为格式化字符串格式 , b为时间戳,一般用localtime()
>>>a
time.struct_time(tm_year=, tm_mon=, tm_day=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=)
>>>time.strftime('%Y-%m-%d %H:%M:%S',a) #把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串
'1974-06-13 10:40:42'
>>>time.strftime('%Y-%m-%d %H:%M:%S',) #不加就默认当前时间
'2017-10-12 19:56:31'
>>>time.strftime('%Y-%m-%d %H:%M:%S %A',a) # %A 星期几
'1974-06-13 10:40:42 Thursday'
>>>time.strftime('%Y-%m-%d %H:%M:%S %p',a) #%p AM or PM
'1974-06-13 10:40:42 AM'
>>>time.strftime('%Y-%m-%d %H:%M:%S %U',a) #%U一年的第几周
'1974-06-13 10:40:42 23'
>>> import time
>>> print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
2018-07-28 14:12:17
>>>s=time.strftime('%Y-%m-%d %H:%M:%S')
>>>s
'2017 10-12 20:00:56'
time.strptime(s, '%Y %m-%d %H:%M:%S') #反转 #把一个格式化时间字符串转化为struct_time
time.struct_time(tm_year=, tm_mon=,, tm_day=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=-)
>>>time.mktime(s) #把时间对象又变成时间戳
1507809686.0
datatime模块
datetime.datetime.now() 返回当前的datetime日期类型,d.timestamp(),d.today(), d.year,d.timetuple()等方法可以调用
>>>import datetime
>>>datetime.datetime.now() #a.timestamp(),a.today(), a.year,a.timetuple()等方法可以调用;打印出下面的时间
datetime.datetime(, , , , , , )

datetime.date.fromtimestamp() #把时间戳转化为datetime类型
>>>d2= datetime.date.fromtimestamp(time.time()) #快速的把时间戳拿到它的年月日
>>>d2
datetime.date(, , )
>>>d2.timetuple()
time.struct_time(tm_year=, tm_mon=, tm_mday=, tm_hour=, tm_min=, tm_sec=, tm_wday=, tm_yday=, tm_isdst=-) #其中三个为0,显示不了
重点是进行时间的运算
datetime.datetime.now() +(-) datetime.timedelta()
>>>t = datetime.timedelta()
>>>datetime.datetime.now() - t
datetime.datetime(, , , , , , )
>>>datetime.datetime.now() - datetime.timedelta(days=)
datetime.datetime(, , , , , , ) >>>datetime.datetime.now() - datetime.timedelta(hours=)
datetime.datetime(, , , , , , ) >>>datetime.datetime.now() + datetime.timedelta(minutes=)
datetime.datetime(, , , , , , ) >>>datetime.datetime.now() + datetime.timedelta(seconds=)
datetime.datetime(, , , , , , )
时间的替换
>>>d.replace()
datetime.datetime(, , , , , ,)
>>>d.replace(year=)
datetime.datetime(, , , , , ,)
>>>d.replace(year=,month=)
datetime.datetime(, , , , , ,)
4.random模块
通过random模块可以很容易生成随机字符串.
random.randint() random.randrange() random.random()随机生成一个[0:1)的随机数
>>>random.randint(,) >>>random.randint(,) >>>random.randint(,) #返回1-3直接的随机数,包含3 [1,3]
>>>random.randrange(,) #不包含3 >>>random.randrange(,)
###############random.random() random.choice() random.sample() #####################
>>>random.random() #返回一个随机浮点数 [0,1)之间的随机数
0.11639912374705497 >>>random.choice('adjs32@45!#2') #返回一个给定集合中的随机字符
‘!’
>>>random.choice('adjs32@45!#2')
‘’ >>>random.sample('adjs32@45!#2',) #从多个字符中选取特定数量的字符
[‘’, '', '@']
>>>random.sample('adjs32@45!#2',)
[‘!’, '@', '']
#############生成随机字符串
>>> import string
>>> ''.join(random.sample(string.ascii_lowercase + string.digits, ))
'4fvda1'

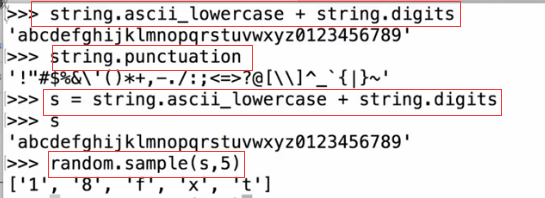

洗牌 random.shuffle(list)将一个列表内的元素打乱

5.os模块
os 模块提供了很多允许你的程序与操作系统直接交互的功能。
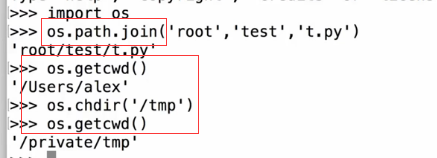
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() e.g os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext() e.g os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py')
获取路径名:os.path.dirname()
获得绝对路径: os.path.abspath()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取操作系统环境变量HOME的值:os.getenv("HOME")
返回操作系统所有的环境变量: os.environ
设置系统环境变量,仅程序运行时有效:os.environ.setdefault('HOME','/home/alex')
给出当前平台使用的行终止符:os.linesep Windows使用'\r\n',Linux and MAC使用'\n'
指示你正在使用的平台:os.name 对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
获取文件大小:os.path.getsize(filename)
结合目录名与文件名:os.path.join(dir,filename)
改变工作目录到dirname: os.chdir(dirname)
获取当前终端的大小: os.get_terminal_size()
杀死进程: os.kill(,signal.SIGKILL)

6.sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit()
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
val = sys.stdin.readline()[:-] #标准输入
sys.getrecursionlimit() #获取最大递归层数
sys.setrecursionlimit() #设置最大递归层数
sys.getdefaultencoding() #获取解释器默认编码
sys.getfilesystemencoding #获取内存数据存到文件里的默认编码
7.shutil模块
http://www.cnblogs.com/wupeiqi/articles/4963027.html
copy文件还有带权限的、copy目录,删除目录,归档移动压缩
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy(src, dst)
拷贝文件和权限
import shutil
shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
import shutil
shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
import shutil
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutil
shutil.rmtree('folder1')
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
import shutil
shutil.move('folder1', 'folder3')
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
- format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /data 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data') #将 /data下的文件打包放置 /tmp/目录
import shutil
ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile压缩&解压缩
import zipfile # 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close() # 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
tarfile压缩&解压缩
import tarfile # 压缩
>>> t=tarfile.open('/tmp/egon.tar','w')
>>> t.add('/test1/a.py',arcname='a.bak')
>>> t.add('/test1/b.py',arcname='b.bak')
>>> t.close() # 解压
>>> t=tarfile.open('/tmp/egon.tar','r')
>>> t.extractall('/egon')
>>> t.close()
8.序列化模块
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
把内存数据转成字符叫序列化;把字符转成内存数据类型叫反序列化。 pickle json
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
import pickle
data = {'k1':123,'k2':'Hello'} # pickle.dumps 将数据通过特殊的形式转换位只有python语言认识的字符串
p_str = pickle.dumps(data)
print(p_str) #pickle.dump 将数据通过特殊的形式转换位只有python语言认识的字符串,并写入文件
with open('D:/result.pk','wb',encoding='utf8') as fp:
pickle.dump(data,fp) import json
# json.dumps 将数据通过特殊的形式转换位所有程序语言都认识的字符串
j_str = json.dumps(data)
print(j_str) #pickle.dump 将数据通过特殊的形式转换位只有python语言认识的字符串,并写入文件
with open('D:/result.json','wb',encoding='utf8') as fp:
json.dump(data,fp)
#序列化
data = {
'roles' : [
{'role':'monster','type':'pig','life':},
{'role':'hero','type':'关羽','life':},
]
}
f = open('game_status','w')
f.write(str(data)) #str把字典转换成字符串
#反序列 把字符转成内存数据类型
data = {
'roles' : [
{'role':'monster','type':'pig','life':},
{'role':'hero','type':'关羽','life':},
]
}
# f = open('game_status','w')
# f.write(str(data))
f = open('game_status','r')
d = f.read()
d = eval(d) #字符串转成字典
print(d['roles'])
序列化json模块
import json
data = {
'roles' : [
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
}
d = json.dumps(data) #仅换成字符串
print(d,type(d)) #str d2 = json.loads(d) #把字符串转成相应的数据类型
print(d2,type(d2)) #dict print(d2['roles'])
打印:
{"roles": [{"role": "monster", "type": "pig", "life": 50}, {"role": "hero", "type": "\u5173\u7fbd", "life": 80}]} <class 'str'>
{'roles': [{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': '关羽', 'life': 80}]} <class 'dict'>
[{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': '关羽', 'life': 80}]
注意loads和load、 dumps和dump的用法和区别:
dumps是将dict转化成str格式,loads是将str转化成dict格式。dump和load也是类似的功能,只是与文件操作结合起来了。
import json
data = {
'roles' : [
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
} f = open("test.json", "w")
json.dump(data, f) #转成字符串并写入文件 f = open("test.json","r")
data = json.load(f) #
print(data['roles'])
自动生成一个test.json文件夹
{"roles": [{"role": "monster", "type": "pig", "life": 50}, {"role": "hero", "type": "\u5173\u7fbd", "life": 80}]} 打印出:
[{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': '关羽', 'life': 80}]
只把数据类型转换成字符串存到内存里的意义? json.dumps json.loads
1.把你的内存数据,通过网络,共享给远程其他人;
2.定义了不同语言的之前的交互规则。
1.纯文本, 坏处, 不能共享复杂的数据类型;2.xml, 坏处 , 占空间大;3.json, 简单, 可读性好。
import json
f = open('json_file', 'w', encoding='utf-8')
d = {'name':'alex', 'age':''} #字典
l = [1,2,3,5,9,'rain'] #列表
json.dump(d,f) #可以dump多次
json.dump(l,f)
自动创建json_file的文件:
{"name": "alex", "age": ""}[1, 2, 3, 5, 9, "rain"]
import json
f = open("json_file", 'r', encoding"utf-8")
print(json.load(f)) #反序列化不能load多次,不要dump多次,load多次。只一次,为了避免问题。 json_load文件里边字典和列表都在里边不能load,会报错。
pickle(用法完全一样)
import pickle
d = {'name' : 'alex' , 'age' : }
l = [,,,,'rain' ]
pk = open("data.pkl", "w")
print(pickle.dumps(d)) ##打印bytes类型 b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00alexq\x02X\x03\x00\x00\x00ageq\x03K\x16u.'
以wb模式存储数据到硬盘
import pickle
d = {'name' : 'alex' , 'age' : 22 }
l = [1,2,3,4,'rain' ]
pk = open("data.pkl", "wb")
print(pickle.dump(d,pk)) #二进制的bytes类型的文本格式,存到了硬盘上。
print(pickle.dump(l,pk)
自动创建data.pkl文件夹:
�}q (X nameq X alexq X ageq K u. �]q (K K K K X rainq e.
从硬盘上读取数据
import pickle
f = open("data.pkl", "rb")
d = pickle.load(f)
print(d) #{'name': 'alex', 'age': 22}
l = pickle.load(f)
print(l) #[1, 2, 3, 4, 'rain']
它俩功能一样。区别:
json:只支持str、int、tuple、list、dict
pickle:支持python里的所有的数据类型;只能在python里使用。
序列化shelve模块
什么是持久化?
狭义的理解: “持久化”仅仅指把域对象永久保存到数据库中;广义的理解,“持久化”包括和数据库相关的各种操作(持久化就是将有用的数据以某种技术保存起来,将来可以再次取出来应用,数据库技术,将内存数据以文件的形式保存在永久介质中(磁盘等)都是持久化的例子.)。
为什么要持久化?
持久化技术封装了数据访问细节,为大部分业务逻辑提供面向对象的API。
● 通过持久化技术可以减少访问数据库数据次数,增加应用程序执行速度;
● 代码重用性高,能够完成大部分数据库操作;
● 松散耦合,使持久化不依赖于底层数据库和上层业务逻辑实现,更换数据库时只需修改配置文件而不用修改代码。
通俗的讲,持久化对象可以理解成这个对象可以被“保存”,类比Java序列化技术,意思就是这个对象的当前状态(它现在的属性的值)可以被保存到“外存”(指文件,磁盘等)。
Python的数据持久化操作主要是六类:普通文件、DBM文件、Pickled对象存储、shelve对象存储、对象数据库存储、关系数据库存储。:
详细见:https://www.cnblogs.com/huajiezh/p/5470770.html
对pickle进行封装,是一种k v的格式。简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
#序列化
import shelve f = shelve.open('shelve_test') # 打开一个文件 names = ["alex", "rain", "test"]
info = {'name':'alex','age':} f["names"] = names # 持久化列表
f['info_dic'] = info #持久化dict f.close()
#反序列化
import shelve d = shelve.open('shelve_test') # 打开一个文件 print(d['names']) #['alex', 'rain', 'test']
print(d['info_dic']) #{'name': 'alex', 'age': 22} #del d['test'] #还可以删除
>>>f = shelve.open("shelve_test")
>>>f
<shelve.DbfilenameShelf object at 0x101dce9e8>
>>>list(f.keys())
['name', 'info_dic']
>>>list(f.items())
[('name', ['alex', 'rain', 'test']), ('info_dic', {'name': 'alex', 'age':})]
>>>f.get('names')
['alex', 'rain', 'text']
>>>f.get('info_dic')
{'name': 'alex', 'age':}
>>>f['names'][]
'rain'
>>>f['names'][] = "Rain wang" #不能这样修改,修改不了,要直接赋值。
>>>f['names'][1]
None
>>>f.close()
>>>f = shelve.open("shelve_test")


import shelve
f = shelve.open("shelve_test")
f['scores'] = [1,2,3,4,5,6]
print(f.get('scores')) f['scores'] = [1,2,3,'A',4,'B']
print(f.get('scores'))
9、XML模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单。至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的。
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes"></rank>
<year></year>
<gdppc></gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes"></rank>
<year></year>
<gdppc></gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes"></rank>
<year></year>
<gdppc></gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml") #open
root = tree.getroot() #f.seek()
print(root.tag)
#遍历xml文档
for child in root:
print('-------------',child.tag,child.attrib)
#print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text) 打印:
data
------------- country {'name': 'Liechtenstein'}
rank
year
gdppc
neighbor None
neighbor None
------------- country {'name': 'Singapore'}
rank
year
gdppc
neighbor None
------------- country {'name': 'Panama'}
rank
year
gdppc
neighbor None
neighbor None
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml") #open
root = tree.getroot() #f.seek()
print(root.tag) #只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text) 打印:
data
year
year
year
###################自己创建xml文档############################# import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist") #root
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
n = ET.SubElement(name,"name")
n = "alex"
sex.text = 'man' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '' et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式 打印:
<?xml version='1.0' encoding='utf-8'?>
<namelist>
<name enrolled="yes">
<age checked="no" />
<sex>man</sex></name>
<name enrolled="no">
<age></age>
</name></namelist>
10、configparser模块(解析、配置文件)
此模块用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。
好多软件的常见配置文件格式如下:
##conf.ini文件
[DEFAULT]
ServerAliveInterval =
Compression = yes
CompressionLevel =
ForwardX11 = yes [bitbucket.org]
User = hg [topsecret.server.com]
Port =
ForwardX11 = no
解析配置文件
>>> import configparser
>>> config = configparser.ConfigParser() #实例化生成一个对象
>>> config.sections() #调用sections方法;在cmd里边演示
[] >>> config.read('example.ini')
['example.ini']
>>> config.sections() #调用sections方法(默认不会读取default方法)
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config #判断元素是否在sections列表内
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User'] #通过字典的形式取值
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
''
>>> for key in config['bitbucket.org']: print(key) #for循环bitbucket.org 字典的key
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'
import configparser
conf = configparser.ConfigParser() #先生成一个对象
print(conf.sections()) #[]
import configparser
conf = configparser.ConfigParser() #先生成一个对象
#print(conf.sections()) #[]
conf.read('conf.ini')
print(conf.sections())#['bitbucket.org', 'topsecret.server.com']
print(conf.default_section) #DEFAULT
# print(list(conf["bitbucket.org"].keys()))
print(conf["bitbucket.org"]['User']) #hg
#循环
import configparser
conf = configparser.ConfigParser() #先生成一个对象 conf.read('conf.ini') for k,v in conf["bitbucket.org"].items():
print(k,v) #打印:
user hg
serveraliveinterval 45
compression yes
compressionlevel 9
forwardx11 yes
import configparser
conf = configparser.ConfigParser() conf.read('conf.ini') if 'user' in conf["bitbucket.org"]: #判断是否在
print('in')
###con_text.ini文件
[group1]
k1 = v1
k2:v2 [group2]
k1 = v1
import configparser
conf = configparser.ConfigParser() #先生成一个对象
conf.read("conf_text.ini")
print(dir(conf))
print(conf.options("group1"))
打印:
['BOOLEAN_STATES', 'NONSPACECRE', 'OPTCRE', 'OPTCRE_NV', 'SECTCRE', '_DEFAULT_INTERPOLATION', '_MutableMapping__marker', '_OPT_NV_TMPL', '_OPT_TMPL', '_SECT_TMPL', '__abstractmethods__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__setattr__', '__setitem__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '__weakref__', '_abc_cache', '_abc_negative_cache', '_abc_negative_cache_version', '_abc_registry', '_allow_no_value', '_comment_prefixes', '_convert_to_boolean', '_converters', '_defaults', '_delimiters', '_dict', '_empty_lines_in_values', '_get', '_get_conv', '_handle_error', '_inline_comment_prefixes', '_interpolation', '_join_multiline_values', '_optcre', '_proxies', '_read', '_sections', '_strict', '_unify_values', '_validate_value_types', '_write_section', 'add_section', 'clear', 'converters', 'default_section', 'defaults', 'get', 'getboolean', 'getfloat', 'getint', 'has_option', 'has_section', 'items', 'keys', 'options', 'optionxform', 'pop', 'popitem', 'read', 'read_dict', 'read_file', 'read_string', 'readfp', 'remove_option', 'remove_section', 'sections', 'set', 'setdefault', 'update', 'values', 'write']
['k1', 'k2']
import configparser
conf = configparser.ConfigParser() #先生成一个对象
conf.read("conf_text.ini")
#print(dir(conf))
print(conf.options("group1"))
print(conf['group1']["k2"]) 打印:
['k1', 'k2']
v2
##conf_test_mew.ini 文件 [group1]
k1 = v1
k2 = v2 [group2]
k1 = v1 [group3]
name = alex
age =
###conf_test2_mew.ini 文件
[group2]
k1 = v1
import configparser
conf = configparser.ConfigParser() #先生成一个对象
conf.read("conf_text.ini")
conf.add_section("group3")
conf["group3"]['name'] = "alex"
conf["group3"]['age'] = ''
conf.write(open('conf_test_mew.ini','w')) ###改写
import configparser
conf = configparser.ConfigParser() #先生成一个对象
conf.read("conf_text.ini") #conf.remove_option("group1",'k2')
conf.remove_section("group1")
conf.write(open('conf_test2_mew.ini','w'))#删完之后要保存
11、hashlib模块
Hash,一般翻译做“散列”,也有直接音译为”哈希”的,就是把任意长度的输入(又叫做预映射,pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,他把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值.也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
MD5讯息摘要演算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码杂凑函数,可以产生出一个128位的散列值(hash value),用于确保信息传输完整一致。MD5的前身有MD2、MD3和MD4。
MD5功能
输入任意长度的信息,经过处理,输出为128位的信息(数字指纹);
不同的输入得到的不同的结果(唯一性);
MD5算法的特点
- 压缩性:任意长度的数据,算出的MD5值的长度都是固定的
- 容易计算:从原数据计算出MD5值很容易
- 抗修改性:对原数据进行任何改动,修改一个字节生成的MD5值区别也会很大
- 强抗碰撞:已知原数据和MD5,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
MD5算法是否可逆?
MD5不可逆的原因是其是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
MD5用途
防止被篡改:
比如发送一个电子文档,发送前,我先得到MD5的输出结果a。然后在对方收到电子文档后,对方也得到一个MD5的输出结果b。如果a与b一样就代表中途未被篡改。
比如我提供文件下载,为了防止不法分子在安装程序中添加木马,我可以在网站上公布由安装文件得到的MD5输出结果。
SVN在检测文件是否在CheckOut后被修改过,也是用到了MD5.
防止直接看到明文:
- 现在很多网站在数据库存储用户的密码的时候都是存储用户密码的MD5值。这样就算不法分子得到数据库的用户密码的MD5值,也无法知道用户的密码。(比如在UNIX系统中用户的密码就是以MD5(或其它类似的算法)经加密后存储在文件系统中。当用户登录的时候,系统把用户输入的密码计算成MD5值,然后再去和保存在文件系统中的MD5值进行比较,进而确定输入的密码是否正确。通过这样的步骤,系统在并不知道用户密码的明码的情况下就可以确定用户登录系统的合法性。这不但可以避免用户的密码被具有系统管理员权限的用户知道,而且还在一定程度上增加了密码被破解的难度。)
防止抵赖(数字签名):
- 这需要一个第三方认证机构。例如A写了一个文件,认证机构对此文件用MD5算法产生摘要信息并做好记录。若以后A说这文件不是他写的,权威机构只需对此文件重新产生摘要信息,然后跟记录在册的摘要信息进行比对,相同的话,就证明是A写的了。这就是所谓的“数字签名”。
SHA-1
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。
SHA是美国国家安全局设计的,由美国国家标准和技术研究院发布的一系列密码散列函数。
由于MD5和SHA-1于2005年被山东大学的教授王小云破解了,科学家们又推出了SHA224, SHA256, SHA384, SHA512,当然位数越长,破解难度越大,但同时生成加密的消息摘要所耗时间也更长。目前最流行的是加密算法是SHA-256 .
MD5与SHA-1的比较
由于MD5与SHA-1均是从MD4发展而来,它们的结构和强度等特性有很多相似之处,SHA-1与MD5的最大区别在于其摘要比MD5摘要长32 比特。对于强行攻击,产生任何一个报文使之摘要等于给定报文摘要的难度:MD5是2128数量级的操作,SHA-1是2160数量级的操作。产生具有相同摘要的两个报文的难度:MD5是264是数量级的操作,SHA-1 是280数量级的操作。因而,SHA-1对强行攻击的强度更大。但由于SHA-1的循环步骤比MD5多80:64且要处理的缓存大160比特:128比特,SHA-1的运行速度比MD5慢。
>>> hash('alex')
-
>>> hash('kris')
>>> hash('alex')
-

>>> import hashlib
>>> m = hashlib.md5()
>>> m.update(b'kris')
>>> m.hexdigest()
'03e13700e25563c0c0a8ffdb48dbbc19' ##这个值永远不会变,在任何平台上
hashlib md5值的用法
#加入下面这个就可以
password = input('请输入密码:')
m = hashlib.md5()
m.update(password.encode())
if m.hexdigest() == data1['password']:
print('登录成功')
12、subprocess模块
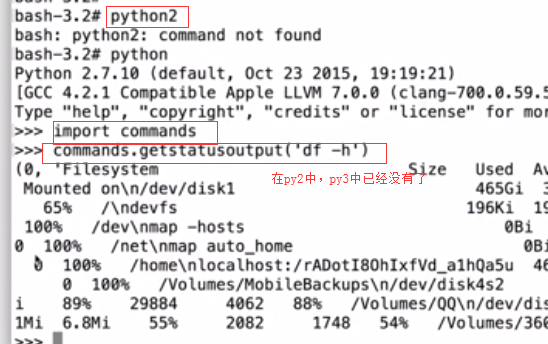
我们经常需要通过Python去执行一条系统命令或脚本,系统的shell命令是独立于你的python进程之外的,每执行一条命令,就是发起一个新进程,通过python调用系统命令或脚本的模块在python2有os.system,
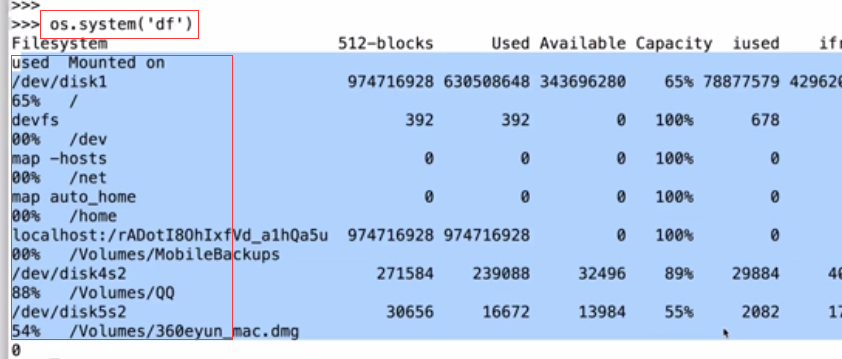
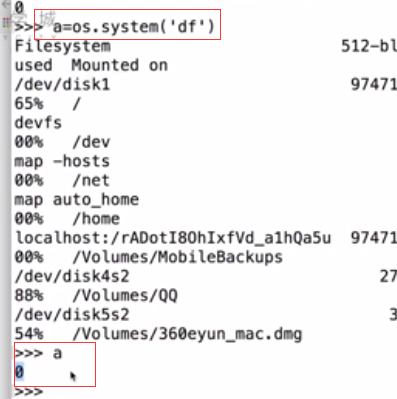
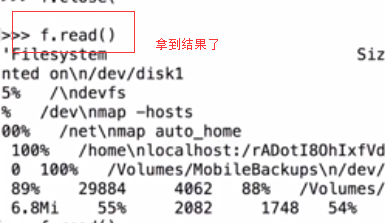
>>> os.system('uname -a')在linux系统中:(无奈电脑是windows系统)
 linux系统里边每条命令都有执行状态。
linux系统里边每条命令都有执行状态。



三种执行命令的方法
subprocess.run(*popenargs, input=None, timeout=None, check=False, **kwargs) #官方推荐
subprocess.call(*popenargs, timeout=None, **kwargs) #跟上面实现的内容差不多,另一种写法
subprocess.Popen() #上面各种方法的底层封装
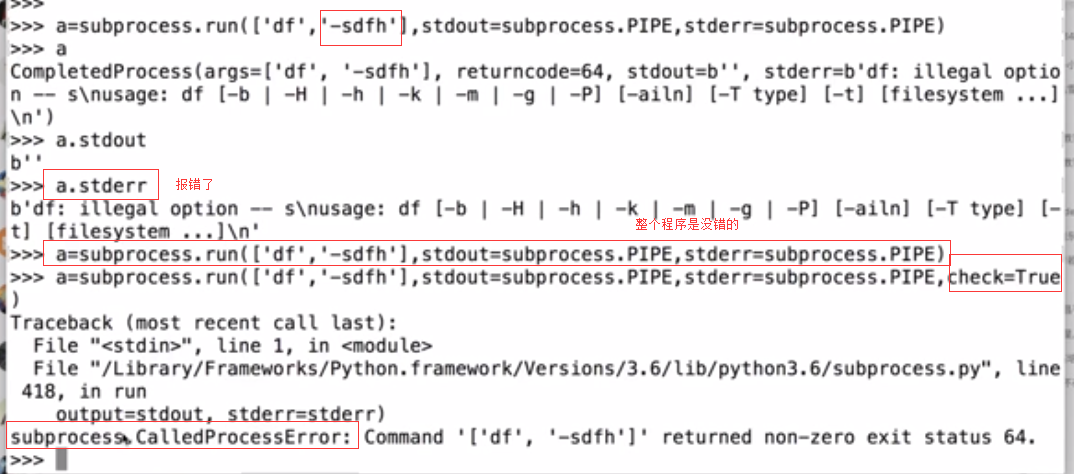
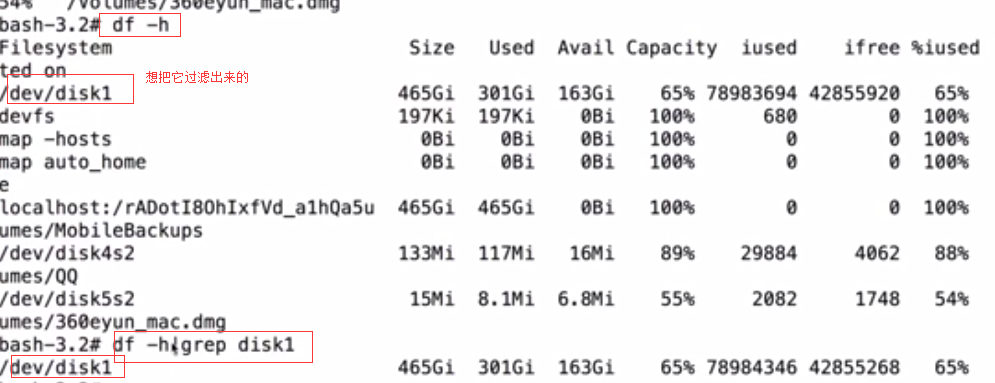
run()方法(主要的)
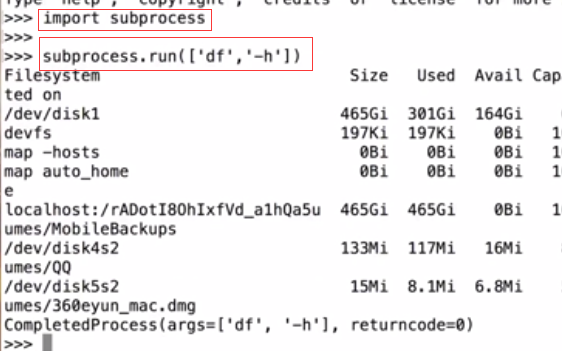


world和QQ通过操作系统这个桥梁来实现互相访问,python和shell的命令也是类似的,每执行一个命令就会打开一个新的窗口(一个独立的程序)。subprocess帮你发起一个进程。




call()方法
#执行命令,返回命令执行状态 , or 非0
>>> retcode = subprocess.call(["ls", "-l"]) #执行命令,如果命令结果为0,就正常返回,否则抛异常
>>> subprocess.check_call(["ls", "-l"]) #接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果
>>> subprocess.getstatusoutput('ls /bin/ls')
(, '/bin/ls') #接收字符串格式命令,并返回结果
>>> subprocess.getoutput('ls /bin/ls')
'/bin/ls' #执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给res
>>> res=subprocess.check_output(['ls','-l'])
>>> res
b'total 0\ndrwxr-xr-x 12 alex staff 408 Nov 2 11:05 OldBoyCRM\n'

Popen()方法


run是这个执行完了才能执行下一个程序,Popen方法是并行的,通过Popen不断拿结果,不影响主程序。
preexec_fn
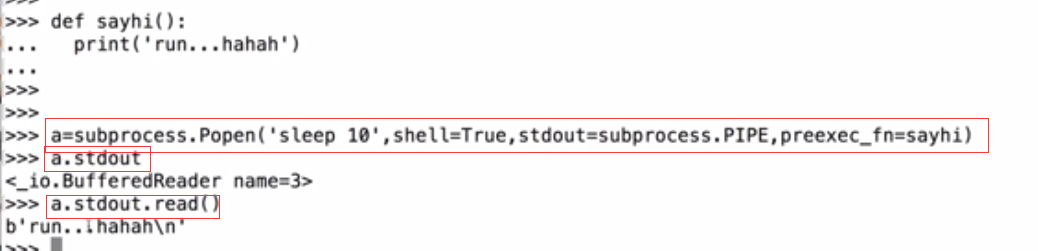
cwd


wait()

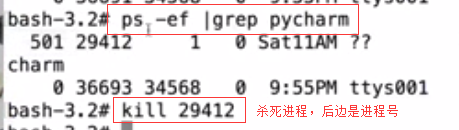
kill()给cpu发个信号
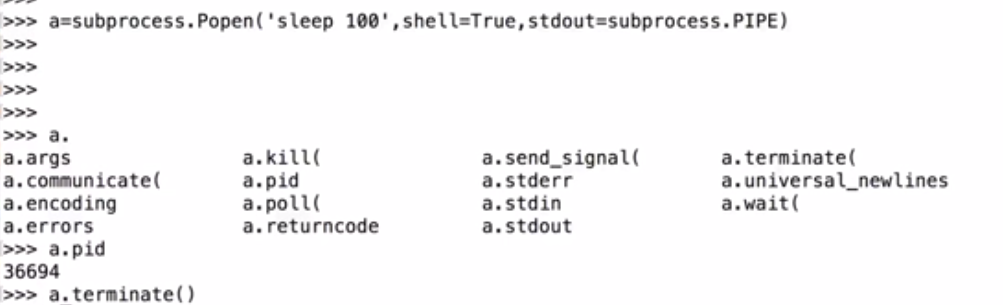
terminate()尝试让这个进程终止


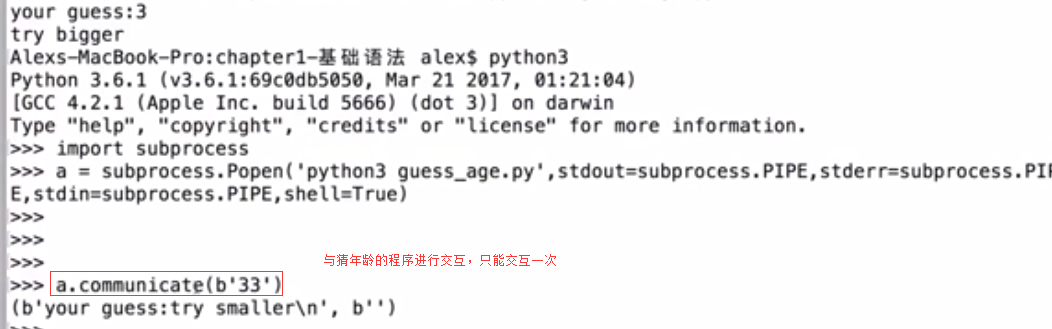
communicate


软件开发目录规范
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
简要解释一下:
- bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。
- foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。
- docs/: 存放一些文档。
- setup.py: 安装、部署、打包的脚本。
- requirements.txt: 存放软件依赖的外部Python包列表。
- README: 项目说明文件。
conf 存配置文件的,(账户数据、日志的文件名或者格式,这些用户可以配置的;)
第四章:4.0 python常用的模块的更多相关文章
- Python开发【第五章】:Python常用模块
一.模块介绍: 1.模块定义 用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能),本质上就是.py结尾python文件 分类:内置模块.开源模块.自定义模块 2.导入模块 本质:导 ...
- python 常用的模块
面试的过程中经常被问到使用过那些python模块,然后我大脑就出现了一片空白各种模块一顿说,其实一点顺序也没有然后给面试官造成的印象就是自己是否真实的用到这些模块,所以总结下自己实际工作中常用的模块: ...
- 进击的Python【第四章】:Python的高级应用(一)
Python的高级应用(一) 本章内容: 内置函数 生成器 迭代器 装饰器 JSON和PICKLE的简单用法 软件目录结构规范 一.内置函数 1.数学运算类 abs(x) 求绝对值1.参数可以是整型, ...
- Python笔记·第四章—— 细数Python中的数据类型以及他们的方法
一.数据类型的种类及主要功能 1.数字类型 数字类型主要是用来计算,它分为整数类型int和浮点类型float 2.布尔类型 布尔类型主要是用于判断,它分为真True和False两种 3.字符串类型 字 ...
- Python开发【第四章】:Python函数剖析
一.Python函数剖析 1.函数的调用顺序 #!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian #函数错误的调用方式 def fun ...
- 第十四章 openwrt 安装 python
需要安装libffi,python-mini,python.libffi以及python-mini需要安装在python之前 如果部分软件包不一样可以在下面的web后台搜索,搜索前先opkg ...
- python常用小模块使用汇总
在写代码过程中常用到一些好用的小模块,现整理汇总一下: 1.获取当前的文件名和目录名,并添到系统环境变量中. file = os.path.abspath(__file__) ...
- Day6 Python常用的模块
一.logging模块 一.日志级别 critical=50 error=40 waring=30 info=20 debug=10 notset=0 二.默认的日志级别是waring(30),默认的 ...
- python 常用第三方模块
除了内建的模块外,Python还有大量的第三方模块. 基本上,所有的第三方模块都会在https://pypi.python.org/pypi上注册,只要找到对应的模块名字,即可用pip安装. 本章介绍 ...
随机推荐
- tomcat配置详解
Tomcat Server的结构图如下: 该文件描述了如何启动Tomcat Server <Server> <Listener /> <GlobaNaming ...
- 了解PID控制
@2019-03-07 [小记] 了解PID控制 比例 - 积分 - 微分 积分 --- 记忆过去 比例 --- 了解现在 微分 --- 预测未来
- 【bfs】抓住那头牛
[题目] 农夫知道一头牛的位置,想要抓住它.农夫和牛都位于数轴上,农夫起始位于点N(0≤N≤100000),牛位于点K(0≤K≤100000).农夫有两种移动方式: 1.从X移动到X-1或X+1,每次 ...
- centos6/7安装java和maven
下载安装包并解压到相关目录即可 编辑环境变量vim /etc/profile.d/maven.sh export JAVA_HOME=/app/soft/java-1.8.0_181 export J ...
- fzyzojP1635 -- 平均值
做法大概有两种: 1.二分平均值,每个值减去平均值,求有没有一个区间的总和大于等于0 (类比,中位数是二分之后,比mid大的为1,小的为0,看有没有区间大于等于0这样) 最值问题——判定问题 单调队列 ...
- zabbix数据库分表的实现
前提条件是主从同步操作完成(主从同步的前提是两个数据库表结构必须一样) 先看一下mysql配置文件 vi /usr/local/mysql/my.cnf 配置内容:------------------ ...
- CNN:Channel与Core的高H、宽W的权值理解
转自: 知乎问题[能否对卷积神经网络工作原理做一个直观的解释?https://www.zhihu.com/question/39022858]中YJango 的回答; 因总是忘记回答地址,方便以后查阅 ...
- <一>企业级开源仓库nexus实战应用–nexus的安装
1,Nexus 介绍. Nexus是什么? Nexus 是一个强大的maven仓库管理器,它极大地简化了本地内部仓库的维护和外部仓库的访问. 不仅如此,他还可以用来创建yum.pypi.npm.doc ...
- 类型和原生函数及类型转换(二:终结js类型判断)
typeof instanceof isArray() Object.prototype.toString.call() DOM对象与DOM集合对象的类型判断 一.typeof typeof是一个一元 ...
- SPFA+SLF+LLL
关于SLF优化 朴素SPFA使用常规队列(FIFO)更新距离,并没有考虑优化出队顺序(dis值小的优先出队)可以在一开始就把各个点的dis值限值小,从而避免大量的松弛操作,从而提高效率.这就是SLF( ...