HashMap的两种实现方式
本文主要简要分析了Java中和Redis中HashMap的实现,并且对比了两者的异同
1.Java的实现
下图表示了Java中一个HashMap的主要实现方式
因为大家对于Java中HashMap的实现方式,已经比较熟悉了,所以咱们只是简单的说一下.
基本结构
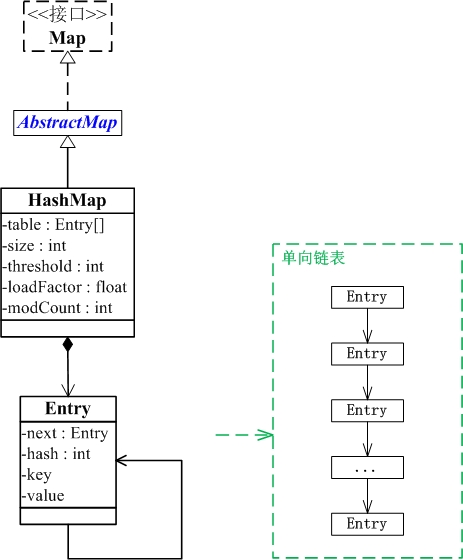
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。 size是HashMap的大小,它是HashMap保存的键值对的数量。 threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。loadFactor就是加载因子。 modCount是用来实现fail-fast机制的。
计算Hash值和在数组中的位置
//length为Entry数组长度
static int indexFor(int h, int length) {
return h & (length - 1);
}
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
添加键值对时的操作(put)
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; e.value = value;
e.recordAccess(this); return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i); return null;}
解决Hash冲突的方式,扩容时机
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)resize(2 * table.length);
}
扩容过程
// 重新调整HashMap的大小,newCapacity是调整后的单位
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中,
// 然后,将“新HashMap”赋值给“旧HashMap”。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
// 将HashMap中的全部元素都添加到newTable中
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
2.Redis的实现
整个基本结构
哈希表
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小(相当于Java中的capacity)
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量(相当于Java中的size)
unsigned long used;
} dictht;
键值对
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
哈希结构
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
简单例子:

添加键值对时的操作(dictAdd)
计算 hash 和 数组位置
# 使用字典设置的哈希函数,计算键 key 的哈希值(相当于hash())
hash = dict->type->hashFunction(key);
# 使用哈希表的 sizemask 属性和哈希值,计算出索引值(相当于indexFor())
index = hash & dict->ht[x].sizemask;
先计算 key的哈希值 在将 该哈希值&(数组长度-1)确定下标(与Java极为相似)
注:Redis 使用 MurmurHash2 算法来计算键的哈希值;这种算法的优点在于, 即使输入的键是有规律的, 算法仍能给出一个很好的随机分布性, 并且算法的计算速度也非常快。关于 MurmurHash 算法的更多信息可以参考该算法的主页: http://code.google.com/p/smhasher/ 。
解决hash冲突

用拉链法解决hash冲突,将旧entry链表插进新entry尾部(与Java极为相似)
扩容时机
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 1 ;
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5;
注:该值不可通过配置来修改,要变必须改源码。
其中哈希表的负载因子可以通过公式:
# 负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[0].used / ht[0].size
该值和Java不同,Java默认值为0.75,相比之下Java扩容更加积极。
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行, 服务器执行扩展操作所需的负载因子并不相同, 这是因为在执行 BGSAVE 命令或 BGREWRITEAOF 命令的过程中, Redis 需要创建当前服务器进程的子进程, 而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率, 所以在子进程存在期间, 服务器会提高执行扩展操作所需的负载因子, 从而尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存。
缩容时机(Java中不会自动缩容)
当哈希表的负载因子小于 0.1
时, 程序自动开始对哈希表执行收缩操作
因为Java中HashMap不会自动缩容,所以在在大量put后,再大量remove,并且还持有该引用的话,会浪费很多内存
变容过程



渐进式转移
扩展或收缩哈希表需要将 ht[0]里面的所有键值对 rehash 到 ht[1]里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。
这样做的原因在于, 如果 ht[0]里只保存着四个键值对, 那么服务器可以在瞬间就将这些键值对全部 rehash 到 ht[1]; 但是, 如果哈希表里保存的键值对数量不是四个, 而是四百万、四千万甚至四亿个键值对, 那么要一次性将这些键值对全部 rehash 到 ht[1]的话, 庞大的计算量可能会导致服务器在一段时间内停止服务。
因此, 为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0]里面的所有键值对全部 rehash 到 ht[1], 而是分多次、渐进式地将 ht[0]里面的键值对慢慢地 rehash 到 ht[1]。

因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0]和 ht[1]两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在ht[0]里面进行查找, 如果没找到的话, 就会继续到 ht[1]里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1]里面, 而 ht[0]则不再进行任何添加操作: 这一措施保证了 ht[0]包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
3.对比两者的异同
Java Redis
基本结构
两者都是键值对数组,键值对是链表
计算哈希值和数组位置
通过自身hash函数,计算hash值,与数组长度&,确定数组下标
解决Hash冲突的方式
拉链法
容量变化时机
默认值为0.75,更加消极,有缩容 默认值为1,更加积极,只可变大,不可变小
容量变化过程
一起完成 分次完成(渐进式)
HashMap的两种实现方式的更多相关文章
- HashMap的两种遍历方式
HashMap的两种遍历方式 HashMap存储的是键值对:key-value . java将HashMap的键值对作为一个整体对象(java.util.Map.Entry)进行处理,这优化了Hash ...
- [Java]HashMap的两种排序方式
先将 Map 中的 key 和 value 全部取出来封装成 JavaBea 数组,再将这个数组排序,排序完成后,重新写回 Map 中,写回时采用 LinkedHashMap 可以保证迭代的顺序. 下 ...
- HashMap的两种排序方式
Map<String, Integer> map = new HashMap<String, Integer>();map.put("d", 2);map. ...
- Map集合的两种遍历方式
Map集合:即 接口Map<K,V> map集合的两种取出方式: 1.Set<k> keyset: 将map中所有的键存入到set集合(即将所有的key值存入到set中) ...
- 细说java中Map的两种迭代方式
曾经对java中迭代方式总是迷迷糊糊的,今天总算弄懂了.特意的总结了一下.基本是算是理解透彻了. 1.再说Map之前先说下Iterator: Iterator主要用于遍历(即迭代訪问)Collecti ...
- Map集合的两种取出方式
Map集合有两种取出方式, 1.keySet:将Map中的键存入Set集合,利用set的迭代器来处理所有的键 举例代码如下: import java.util.*; class Test { publ ...
- Map的两种遍历方式
********************************************************************************* ****************** ...
- Java中的HashMap的2种遍历方式比较
首先我们准备数据,准备一个map Map<String, String> map = new HashMap<String, String>(); for (int i = 0 ...
- 谨慎使用keySet:对于HashMap的2种遍历方式比较
HashMap存储的是键值对,所以一般情况下其遍历同List及Set应该有所不同. 但java巧妙的将HashMap的键值对作为一个整体对象(java.util.Map.Entry)进行处理,这优化了 ...
随机推荐
- Model View Controller
On the iPhone or iPod touch, a modal view controller takes over the entire screen. This is the defau ...
- HDP 2.3 Notes
Hortonworks Data Platform 2.3.4.0-3485 [bug] /usr/hdp/2.3.4.0-3485/zookeeper/bin/zkEnv.sh 26 if [ -z ...
- 向架构师进军-->可重用架构资源
如果你对项目管理.系统架构有兴趣,请加微信订阅号"softjg",加入这个PM.架构师的大家庭 软件架构有三个主要来源:拿取.方法以及直觉.拿取也就是可重用资源.对于一个标准的系统 ...
- Android 调用系统联系人界面的添加联系人,添加已有联系人,编辑和修改。
一.添加联系人 Intent addIntent = new Intent(Intent.ACTION_INSERT,Uri.withAppendedPath(Uri.parse("cont ...
- 关于jq+devexpress基础知识总结(随便的基础)
//获取某行某列的值 onSelectionChanged: function (selectedItems) { ]; if (data != null) postionno = data.POST ...
- leetcode-【简单题】Happy Number
题目: Write an algorithm to determine if a number is "happy". A happy number is a number def ...
- mysql 复制表结构、表数据的方法
From: http://blog.163.com/yaoyingying681@126/blog/static/109463675201191173221759/ MySQL 添加列,修改列,删除列 ...
- Servlet--表单、超链接、转发、重定向4种情况的路径
Servlet中相对路径总结 假设web工程使用如下目录结构: 在介绍相对路径和绝对路径前需要先了解几个概念: 服务器的站点根目录:以tomcat服务器为例,tomcat服务器站点根目录就是apach ...
- nginx 配置全站404(百度闭站保护)
在百度站长里申请闭站保护时,需要全站404.可能过nginx配置实现 location / { #root html; #index index.html index.htm; retur ...
- HTTP权威协议笔记-3.Http报文
3.1 报文流 http使用流入和流出来描述事物处理方向,报文包含:起始行.首部和主体. 3.2 起始行 起始行包含:请求行和回应行. 3.2.1请求行 请求行包含:方法.请求URL(描述了对哪个资源 ...