Stanford NLP 学习笔记2:文本处理基础(text processing)
I. 正则表达式(regular expression)
正则表达式是专门处理文本字符串的正式语言(这个是基础中的基础,就不再详细叙述,不了解的可以看这里)。
- ^(在字符前): 负选择,匹配除括号以外的字符。比如
[^A-W]匹配所有非大写字符;[^e^]匹配所有e和^以外的字符 - |:或者。比如a|b|c等价于
[a-c] - *:匹配大于等于0个符号前面的字符;+:匹配至少一个前面的字符;.:匹配所有单个字符;?:匹配0或1个前面的字符
- \:转义符:将特殊字符转化为简单字符。比如.匹配所有字符,.匹配.。
- 锚定符。^:匹配开头;$:匹配结尾。比如:^[a-z]匹配非小写字母开头的字符串;.$匹配所有.结尾的字符串。
匹配的错误类型:
- 一类错误(type I error):假阳性。匹配上不想匹配的字符串。比如只想匹配单词the却匹配上了other。
- 二类错误(type II error):假阴性。没有匹配上想要的字符串。比如像匹配单词the却没有匹配The。
基本上在NLP分析过程(甚至是所有机器学习问题)都是在处理这两类错误。减少一类错误(假阳性)意味着提高模型精度;减少二类错误(假阴性)意味着增加召回率。
总结:
正则表达式很强大,通配操作很方便,一般也是文本处理的第一步。在许多困难的任务中用到的机器学习分类器也会使用正则表达式作为特征。
II. 分词
文本标准化一般操作:1.断句。 2.分词。 3. 统一词格式(大小写,复数单数形式,所有格形式等)。
词根(lemma)和词形(wordform)

例子中的San Francisco可以拆开作为两个token,也可以整个作为一个token;而前后两个the只能算作一个type,而they和their也可以看成一个type
统计语料(corpus)时,一般默认用N代表tokens的数量;用V代表词汇库,即所有类型;|V|代表词汇库的大小。
Church & Gale(1990)提出|V| > O(N^1/2)
分词过程的一些问题:
- 缩写(有些包含标点符号)

- 其他语言
- 法语:

- 德语:复合名称之间没有空格

- 中文和日文:单词之间没有空格
中文分词:
中文由字符组成,每个字符一般时单音节和单字形的;平均每个单词包含2.4个字符。中文标准基线的分词算法是最大匹配算法(maximum matching algorithm)或贪婪算法(greedy algorithm)。

这里,由于中文的单词长度相对比较一致,因此这个方法效果比较好,但是这个方法对英语来说并不合适,因为英文单词长短差异很大且常长度不同的单词一般都混杂在一起使用。因此目前主流的分词算法都采用了概率模型。
III. 词标准化和词干提取
- 标准化
信息提取的时候,indexed text和query terms需要有相同的格式。比如U.S.A --> USA
上述处理可以通过删除词内.号实现。
非对称推广(asymmetric expansion):比如:

但是实际操作中为了降低时间复杂性等考虑一般还是会采用对称推广。 - 大小写折叠(Case Folding):将所有大写字符转换成小写字符
可能的例外:句中间的大写字符,比如General Motors;缩写单词的大写字符,比如Fed(Federal reserve bank) - 词形还原(lemmatization)
将词的变体转换为原型词根(寻找不同变体的共同词头)。比如:
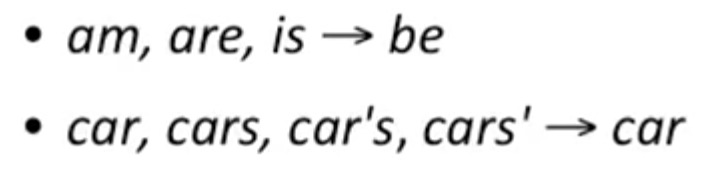
构词(morphology):词素(morpheme)是指构成词的最小的有语法意义单位。由词干(stem)和词缀(affix)组成。

其中方框内的就是词干,而圆圈内的就是词缀。 - 词干化(stemming)
在信息提取时将词转换成其词干形式,而词干化就是将词的词缀去除留下词干(这一过程时语言依赖的,不同语言的词干化规则不同)。比如:

最著名的词干分析器是Porter's algorithm:这是由一系列按顺序排列的词干化规则组成

IV. 分句
将文本分成按边界一个个单句。!和?是很清晰的句子边界标志,但是.号不是。.号可以作为句子边界,缩写标志(Inc.和Dr.等)以及浮点数(.2%和4.3等)。因此在判断.号是否为边界的时候可以采用包括决策树,正则表达式,SVM,logistic regression , neural network等分类器来进行判断。
由于决策树只需通过if-else进行判断,所以利用决策树作为分类器十分直观易懂。决策树的关键在于选取特征。比如提取.号相关的文本特征:

但是除非特征数很少,否则很难手动进行决策树的构建,因为对于大部分数字型特征都需要设定阈值。所以一般都是通过机器学习的方式从语料自动学习来生成结构。
传送门:https://www.youtube.com/watch?v=di0N3kXfGYg
Stanford NLP 学习笔记2:文本处理基础(text processing)的更多相关文章
- Stanford NLP学习笔记:7. 情感分析(Sentiment)
1. 什么是情感分析(别名:观点提取,主题分析,情感挖掘...) 应用: 1)正面VS负面的影评(影片分类问题) 2)产品/品牌评价: Google产品搜索 3)twitter情感预测股票市场行情/消 ...
- Stanford NLP学习笔记1:课程介绍
Stanford NLP课程简介 1. NLP应用例子 问答系统: IBM Watson 信息提取(information extraction) 情感分析 机器翻译 2. NLP应用当前进展 很成熟 ...
- stanford NLP学习笔记3:最小编辑距离(Minimum Edit Distance)
I. 最小编辑距离的定义 最小编辑距离旨在定义两个字符串之间的相似度(word similarity).定义相似度可以用于拼写纠错,计算生物学上的序列比对,机器翻译,信息提取,语音识别等. 编辑距离就 ...
- Linux 学习笔记之超详细基础linux命令 Part 13
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 ---------------------------------接Part 12---------------- ...
- Linux 学习笔记之超详细基础linux命令 Part 4
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 ---------------------------------接Part 3----------------- ...
- Linux 学习笔记之超详细基础linux命令 Part 2
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 ---------------------------------接Part 1----------------- ...
- Linux 学习笔记之超详细基础linux命令 Part 1
Linux学习笔记之超详细基础linux命令 by:授客 QQ:1033553122 说明:主要是在REHL Server 6操作系统下进行的测试 --字符界面虚拟终端与图形界面之间的切 方法:[ ...
- 【学习笔记】jQuery的基础学习
[学习笔记]jQuery的基础学习 新建 模板 小书匠 什么是jQuery对象? jQuery 对象就是通过jQuery包装DOM对象后产生的对象.jQuery 对象是 jQuery 独有的. 如果 ...
- 【学习笔记】JavaScript的基础学习
[学习笔记]JavaScript的基础学习 一 变量 1 变量命名规则 Camel 标记法 首字母是小写的,接下来的字母都以大写字符开头.例如: var myTestValue = 0, mySeco ...
随机推荐
- HttpFox插件安装和打开教程
HttpFox插件安装教程 1.打开火狐浏览器,选择右上角的打开菜单 2.选择附加组件,在获取附件组件栏中搜索HttpFox插件 3.找到HttpFox插件选择安装 4.安装完成后选择左边的扩展栏确认 ...
- C++学习笔记31:术语翻译
reference:引用 dereference:引领,好于"解引用" type:型式,好于"类型" int:整数型式,简称整型 class:类型式,简称类型 ...
- android 中theme和style的语法相关
1.theme和style都是一组属性的集合,用于定义文本.颜色.大小等显示风格.他们都是资源,可以用android系统级别的一些默认的风格和主题资源,你也可以自定义你自己的主题和风格资源. 2.自定 ...
- MyBatis笔记
Mybatis:将java对象映射成SQL语句,再将结果转化为java对象,解决了java对象和sql拼接.结果集的问题,又可以自己写sql语句 总体结构: 根据JDBC规范建立与数据库的连接 通过反 ...
- entity framework 数据加载三种方式的异同(延迟加载,预加载,显示加载)
三种加载方式的区别 显示加载: 显示加载
- PHP连接MySQL数据库
PHP连接MySQL数据库 既然现在你看到了这篇文章,说明你肯定知道PHP和MySQL是怎么一回事,我就不啰嗦了.但为什么你还要继续阅读此文呢?可能是以前你习惯复制粘贴一些代码,并没有真正弄懂代码的含 ...
- [c++] stack的使用
cout << ; i<; i++) first.push(i); cout << ...
- 八皇后—Java
package queen; public class queen { static boolean col[] = new boolean[8]; static boolean main_diago ...
- JavaScript的json和Array及Array数组的使用方法
1.关于json JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集.也可以称为数据集和数组类似,能够存数据! //Ar ...
- Dos学习笔记(2)dos屏幕内容的复制
方法1,选择复制,右键dos屏幕=>标记=>然后选择开始复制的地方,拖动覆盖要复制的内容,好了之后,按回车键(Enter). 方法2,全部复制,右键dos屏幕=>全选=>然后回 ...