java提高篇(二五)-----HashTable
 在java中与有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相对应的value值。一个是前面提到的HashMap,还有一个就是马上要讲解的HashTable。对于HashTable而言,它在很大程度上和HashMap的实现差不多,如果我们对HashMap比较了解的话,对HashTable的认知会提高很大的帮助。他们两者之间只存在几点的不同,这个后面会阐述。
在java中与有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相对应的value值。一个是前面提到的HashMap,还有一个就是马上要讲解的HashTable。对于HashTable而言,它在很大程度上和HashMap的实现差不多,如果我们对HashMap比较了解的话,对HashTable的认知会提高很大的帮助。他们两者之间只存在几点的不同,这个后面会阐述。
一、定义
HashTable在Java中的定义如下:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable
从中可以看出HashTable继承Dictionary类,实现Map接口。其中Dictionary类是任何可将键映射到相应值的类(如 Hashtable)的抽象父类。每个键和每个值都是一个对象。在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是"key-value键值对"接口。
HashTable采用"拉链法"实现哈希表,它定义了几个重要的参数:table、count、threshold、loadFactor、modCount。
table:为一个Entry[]数组类型,Entry代表了“拉链”的节点,每一个Entry代表了一个键值对,哈希表的"key-value键值对"都是存储在Entry数组中的。
count:HashTable的大小,注意这个大小并不是HashTable的容器大小,而是他所包含Entry键值对的数量。
threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor:加载因子。
modCount:用来实现“fail-fast”机制的(也就是快速失败)。所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你(你已经出错了)。
二、构造方法
在HashTabel中存在5个构造函数。通过这5个构造函数我们构建出一个我想要的HashTable。
public Hashtable() {
this(11, 0.75f);
}
默认构造函数,容量为11,加载因子为0.75。
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
用指定初始容量和默认的加载因子 (0.75) 构造一个新的空哈希表。
public Hashtable(int initialCapacity, float loadFactor) {
//验证初始容量
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
//验证加载因子
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
</span><span style="color: #0000ff">if</span> (initialCapacity==0<span style="color: #000000">)
initialCapacity </span>= 1<span style="color: #000000">;
</span><span style="color: #0000ff">this</span>.loadFactor =<span style="color: #000000"> loadFactor;
</span><span style="color: #008000">//</span><span style="color: #008000">初始化table,获得大小为initialCapacity的table数组</span>
table = <span style="color: #0000ff">new</span><span style="color: #000000"> Entry[initialCapacity];
</span><span style="color: #008000">//</span><span style="color: #008000">计算阀值</span>
threshold = (<span style="color: #0000ff">int</span>)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1<span style="color: #000000">);
</span><span style="color: #008000">//</span><span style="color: #008000">初始化HashSeed值</span>
initHashSeedAsNeeded(initialCapacity);
}
用指定初始容量和指定加载因子构造一个新的空哈希表。其中initHashSeedAsNeeded方法用于初始化hashSeed参数,其中hashSeed用于计算key的hash值,它与key的hashCode进行按位异或运算。这个hashSeed是一个与实例相关的随机值,主要用于解决hash冲突。
private int hash(Object k) {
return hashSeed ^ k.hashCode();
}
构造一个与给定的 Map 具有相同映射关系的新哈希表。
public Hashtable(Map<? extends K, ? extends V> t) {
//设置table容器大小,其值==t.size * 2 + 1
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
三、主要方法
HashTable的API对外提供了许多方法,这些方法能够很好帮助我们操作HashTable,但是这里我只介绍两个最根本的方法:put、get。
首先我们先看put方法:将指定 key 映射到此哈希表中的指定 value。注意这里键key和值value都不可为空。
public synchronized V put(K key, V value) {
// 确保value不为null
if (value == null) {
throw new NullPointerException();
}
</span><span style="color: #008000">/*</span><span style="color: #008000">
* 确保key在table[]是不重复的
* 处理过程:
* 1、计算key的hash值,确认在table[]中的索引位置
* 2、迭代index索引位置,如果该位置处的链表中存在一个一样的key,则替换其value,返回旧值
</span><span style="color: #008000">*/</span><span style="color: #000000">
Entry tab[] </span>=<span style="color: #000000"> table;
</span><span style="color: #0000ff">int</span> hash = hash(key); <span style="color: #008000">//</span><span style="color: #008000">计算key的hash值</span>
<span style="color: #0000ff">int</span> index = (hash & 0x7FFFFFFF) % tab.length; <span style="color: #008000">//</span><span style="color: #008000">确认该key的索引位置
</span><span style="color: #008000">//</span><span style="color: #008000">迭代,寻找该key,替换</span>
<span style="color: #0000ff">for</span> (Entry<K,V> e = tab[index] ; e != <span style="color: #0000ff">null</span> ; e =<span style="color: #000000"> e.next) {
</span><span style="color: #0000ff">if</span> ((e.hash == hash) &&<span style="color: #000000"> e.key.equals(key)) {
V old </span>=<span style="color: #000000"> e.value;
e.value </span>=<span style="color: #000000"> value;
</span><span style="color: #0000ff">return</span><span style="color: #000000"> old;
}
}
modCount</span>++<span style="color: #000000">;
</span><span style="color: #0000ff">if</span> (count >= threshold) { <span style="color: #008000">//</span><span style="color: #008000">如果容器中的元素数量已经达到阀值,则进行扩容操作</span>
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
</span><span style="color: #008000">//</span><span style="color: #008000"> 在索引位置处插入一个新的节点</span>
Entry<K,V> e =<span style="color: #000000"> tab[index];
tab[index] </span>= <span style="color: #0000ff">new</span> Entry<><span style="color: #000000">(hash, key, value, e);
</span><span style="color: #008000">//</span><span style="color: #008000">容器中元素+1</span>
count++<span style="color: #000000">;
</span><span style="color: #0000ff">return</span> <span style="color: #0000ff">null</span><span style="color: #000000">;
}</span></pre>
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表(我们暂且理解为链表),若该链表中存在一个这个的key对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。如下:
首先我们假设一个容量为5的table,存在8、10、13、16、17、21。他们在table中位置如下:
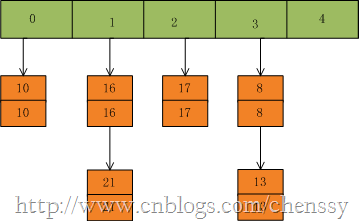
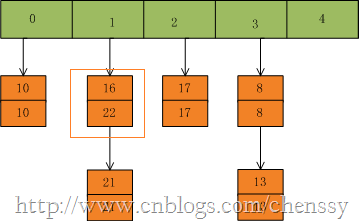
然后我们插入一个数:put(16,22),key=16在table的索引位置为1,同时在1索引位置有两个数,程序对该“链表”进行迭代,发现存在一个key=16,这时要做的工作就是用newValue=22替换oldValue16,并将oldValue=16返回。
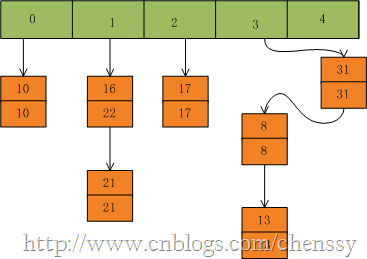
在put(33,33),key=33所在的索引位置为3,并且在该链表中也没有存在某个key=33的节点,所以就将该节点插入该链表的第一个位置。
在HashTabled的put方法中有两个地方需要注意:
1、HashTable的扩容操作,在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,HashTable就会进行扩容处理rehash(),如下:
protected void rehash() {
int oldCapacity = table.length;
//元素
Entry<K,V>[] oldMap = table;
</span><span style="color: #008000">//</span><span style="color: #008000">新容量=旧容量 * 2 + 1</span>
<span style="color: #0000ff">int</span> newCapacity = (oldCapacity << 1) + 1<span style="color: #000000">;
</span><span style="color: #0000ff">if</span> (newCapacity - MAX_ARRAY_SIZE > 0<span style="color: #000000">) {
</span><span style="color: #0000ff">if</span> (oldCapacity ==<span style="color: #000000"> MAX_ARRAY_SIZE)
</span><span style="color: #0000ff">return</span><span style="color: #000000">;
newCapacity </span>=<span style="color: #000000"> MAX_ARRAY_SIZE;
}
</span><span style="color: #008000">//</span><span style="color: #008000">新建一个size = newCapacity 的HashTable</span>
Entry<K,V>[] newMap = <span style="color: #0000ff">new</span><span style="color: #000000"> Entry[];
modCount</span>++<span style="color: #000000">;
</span><span style="color: #008000">//</span><span style="color: #008000">重新计算阀值</span>
threshold = (<span style="color: #0000ff">int</span>)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1<span style="color: #000000">);
</span><span style="color: #008000">//</span><span style="color: #008000">重新计算hashSeed</span>
<span style="color: #0000ff">boolean</span> rehash =<span style="color: #000000"> initHashSeedAsNeeded(newCapacity);
table </span>=<span style="color: #000000"> newMap;
</span><span style="color: #008000">//</span><span style="color: #008000">将原来的元素拷贝到新的HashTable中</span>
<span style="color: #0000ff">for</span> (<span style="color: #0000ff">int</span> i = oldCapacity ; i-- > 0<span style="color: #000000"> ;) {
</span><span style="color: #0000ff">for</span> (Entry<K,V> old = oldMap[i] ; old != <span style="color: #0000ff">null</span><span style="color: #000000"> ; ) {
Entry</span><K,V> e =<span style="color: #000000"> old;
old </span>=<span style="color: #000000"> old.next;
</span><span style="color: #0000ff">if</span><span style="color: #000000"> (rehash) {
e.hash </span>=<span style="color: #000000"> hash(e.key);
}
</span><span style="color: #0000ff">int</span> index = (e.hash & 0x7FFFFFFF) %<span style="color: #000000"> newCapacity;
e.next </span>=<span style="color: #000000"> newMap[index];
newMap[index] </span>=<span style="color: #000000"> e;
}
}
}</span></pre>
在这个rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程是比较消耗时间的,同时还需要重新计算hashSeed的,毕竟容量已经变了。这里对阀值啰嗦一下:比如初始值11、加载因子默认0.75,那么这个时候阀值threshold=8,当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,而阀值threshold=17*0.75 = 13,当容器元素再一次达到阀值时,HashTable还会进行扩容操作,一次类推。
2、其实这里是我的一个疑问,在计算索引位置index时,HashTable进行了一个与运算过程(hash & 0x7FFFFFFF),为什么需要做一步操作,这么做有什么好处?如果哪位知道,望指导,LZ不胜感激!!下面是计算key的hash值,这里hashSeed发挥了作用。
private int hash(Object k) {
return hashSeed ^ k.hashCode();
}
相对于put方法,get方法就会比较简单,处理过程就是计算key的hash值,判断在table数组中的索引位置,然后迭代链表,匹配直到找到相对应key的value,若没有找到返回null。
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
四、HashTable与HashMap的区别
HashTable和HashMap存在很多的相同点,但是他们还是有几个比较重要的不同点。
第一:我们从他们的定义就可以看出他们的不同,HashTable基于Dictionary类,而HashMap是基于AbstractMap。Dictionary是什么?它是任何可将键映射到相应值的类的抽象父类,而AbstractMap是基于Map接口的骨干实现,它以最大限度地减少实现此接口所需的工作。
第二:HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null。如下:
当HashMap遇到为null的key时,它会调用putForNullKey方法来进行处理。对于value没有进行任何处理,只要是对象都可以。
if (key == null)
return putForNullKey(value);
而当HashTable遇到null时,他会直接抛出NullPointerException异常信息。
if (value == null) {
throw new NullPointerException();
}
第三:Hashtable的方法是同步的,而HashMap的方法不是。所以有人一般都建议如果是涉及到多线程同步时采用HashTable,没有涉及就采用HashMap,但是在Collections类中存在一个静态方法:synchronizedMap(),该方法创建了一个线程安全的Map对象,并把它作为一个封装的对象来返回,所以通过Collections类的synchronizedMap方法是可以我们你同步访问潜在的HashMap。这样君该如何选择呢???
java提高篇(二五)-----HashTable的更多相关文章
- 【转】java提高篇(二)-----理解java的三大特性之继承
[转]java提高篇(二)-----理解java的三大特性之继承 原文地址:http://www.cnblogs.com/chenssy/p/3354884.html 在<Think in ja ...
- Java提高(二)---- HashTable
阅读博客 java提高篇(二五)—–HashTable 这篇博客由chenssy 发表与2014年4月,基于源码是jdk1.7 ========================== 本文针对jdk1. ...
- java提高篇(十五)-----关键字final
在程序设计中,我们有时可能希望某些数据是不能够改变的,这个时候final就有用武之地了.final是java的关键字,它所表示的是“这部分是无法修改的”.不想被改变的原因有两个:效率.设计.使用到fi ...
- java提高篇(二)-----理解java的三大特性之继承
在<Think in java>中有这样一句话:复用代码是Java众多引人注目的功能之一.但要想成为极具革命性的语言,仅仅能够复制代码并对加以改变是不够的,它还必须能够做更多的事情.在这句 ...
- (转)java提高篇(二)-----理解java的三大特性之继承
在<Think in java>中有这样一句话:复用代码是Java众多引人注目的功能之一.但要想成为极具革命性的语言,仅仅能够复制代码并对加以改变是不够的,它还必须能够做更多的事情.在这句 ...
- java提高篇(二二)---LinkedList
一.概述 LinkedList与ArrayList一样实现List接口,只是ArrayList是List接口的大小可变数组的实现,LinkedList是List接口链表的实现.基于链表实现的方式使得L ...
- java提高篇(五)-----使用序列化实现对象的拷贝
我们知道在Java中存在这个接口Cloneable,实现该接口的类都会具备被拷贝的能力,同时拷贝是在内存中进行,在性能方面比我们直接通过new生成对象来的快,特别是在大对象的生成上,使得性 ...
- Java提高篇——对象克隆(复制)
假如说你想复制一个简单变量.很简单: int apples = 5; int pears = apples; 不仅仅是int类型,其它七种原始数据类型(boolean,char,byte,short, ...
- Java提高篇(二六)-----hashCode
在前面三篇博文中LZ讲解了(HashMap.HashSet.HashTable),在其中LZ不断地讲解他们的put和get方法,在这两个方法中计算key的hashCode应该是最重要也是最 ...
- Java提高篇(三二)-----List总结
前面LZ已经充分介绍了有关于List接口的大部分知识,如ArrayList.LinkedList.Vector.Stack,通过这几个知识点可以对List接口有了比较深的了解了.只有通过归纳总结的知识 ...
随机推荐
- python学习-day14-前端之html、css
一.Html 1.本质:一个规则,浏览器能任务的规则 2.开发者: 学习Html规则 开发后台程序: - 写Html文件(充当模板的作用) ***** ...
- Linux下GDB调试
GDB 是一个强大的命令行调试工具.大家知道命令行的强大就是在于,其可以形成执行 序列,形成脚本.UNIX 下的软件全是命令行的,这给程序开发提供了极大的便利,命令行 软件的优势在于, 他们可以非常容 ...
- html5 完整图片上传
<div class="photo" style="display:none;" id="upPhoto"><div cl ...
- java单例模式实现方式
Singleton 模式要求一个类有且仅有一个实例,并提供一个全局访问点. Singleton模式 是一种职责型模式.因为我们创建了一个对象,这个对象扮演了独一无二的角色,在这个单独的对象实例中,它集 ...
- JavaScript的Ajax请求示例
//创建XMLHttpRequest对象 var request = false; try { request = new ...
- House Robber III leetcode 动态规划
https://leetcode.com/submissions/detail/56095603/ 这是一道不错的DP题!自己想了好久没有清晰的思路,参看大神博客!http://siukwan.sin ...
- GIT分支管理模型
GIT分支管理模型 link: git-branching-model 主分支(Main branches) 项目两个常驻分支: master 主干分支(锁定),仅用于发布新版本,平时不能在上面干活, ...
- 获取基于Internet Explorer_Server的聊天窗口内容
假设在得到窗体中控件的句柄(通过SPY++)的前提下,如果是像文本框这种控件,只要用SendMessage就可得到文本了,但是对于聊天记录窗口却行不通(返回空值),因为那其实是一个内置浏览器Inter ...
- [转] 多进程下数据库环境的恢复:DB_REGISTER
http://www.cnblogs.com/promise6522/archive/2012/05/09/2493542.html
- CSS伪类选择器
一.CSS伪类选择器用于给某些选择器添加效果语法规则:选择器:伪选择器例:a:link {color: #FF0000} 未访问的链接 a:visited {color: #00FF00} 已访问的链 ...