深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)
我们在学习成熟网络模型时,如VGG、Inception、Resnet等,往往面临的第一个问题便是这些模型的各层参数是如何设置的呢?另外,我们如果要设计自己的网路模型时,又该如何设置各层参数呢?如果模型参数设置出错的话,其实模型也往往不能运行了。
所以,我们需要首先了解模型各层的含义,比如输出尺寸和可训练参数数量。理解后,大家在设计自己的网路模型时,就可以先在纸上画出网络流程图,设置各参数,计算输出尺寸和可训练参数数量,最后就可以照此进行编码实现了。
而在keras中,当我们构建模型或拿到一个成熟模型后,往往可以通过model.summary()来观察模型各层的信息。
本文将通过一个简单的例子来进行说明。本例以keras官网的一个简单模型VGG-like模型为基础,稍加改动代码如下:
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPool2D (train_data, train_labels), (test_data, test_labels) = keras.datasets.mnist.load_data()
train_data = train_data.reshape(-1, 28, 28, 1)
print("train data type:{}, shape:{}, dim:{}".format(type(train_data), train_data.shape, train_data.ndim))
# 第一组
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu', input_shape=(28, 28, 1)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 第二组
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 第三组
model.add(Flatten())
model.add(Dense(units=256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=10, activation='softmax')) model.summary()
本例的数据来源于mnist,这是尺寸为28*28,通道数为1,也即只有黑白两色的图片。其中卷积层的参数含义为:
- filters:表示过滤器的数量,每一个过滤器都会与对应的输入层进行卷积操作;
- kernel_size:表示过滤器的尺寸,一般为奇数值,如1,3,5,这里设置为3*3大小;
- strides:表示步长,即每一次过滤器在图片上移动的步数;
- padding:表示是否对图片边缘填充像素,一般有两个值可选,一是默认的valid,表示不填充像素,卷积后图片尺寸会变小;另一种是same,填充像素,使得输出尺寸和输入尺寸保持一致。
如果选择valid,假设输入尺寸为n * n,过滤器的大小为f * f,步长为s,则其输出图片的尺寸公式为:[(n - f)/s + 1] * [(n -f)/s + 1)],若计算结果不为整数,则向下取整;
如果选择same,假设输入尺寸为n * n,过滤器的大小为f * f,要填充的边缘像素宽度为p,则计算p的公式为:n + 2p -f +1 = n, 最后得 p = (f -1) /2。
运行上述例子,可以看到如下结果:
train data type:<class 'numpy.ndarray'>, shape:(60000, 28, 28, 1), dim:4
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_1 (Conv2D) (None, 24, 24, 32) 9248
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 10, 10, 64) 18496
_________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 8, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 4, 4, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 256) 262400
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
=================================================================
Total params: 329,962
Trainable params: 329,962
Non-trainable params: 0
让我们解读下,首先mnist为输入数据,尺寸大小为 (60000, 28, 28, 1), 这是典型的NHWC结构,即(图片数量,宽度,高度,通道数);
其次我们需要关注表格中的"output shape"输出尺寸,其遵循mnist一样的结构,只不过第一位往往是None,表示图片数待定,后三位则按照上述规则进行计算;
最后关注的是"param"可训练参数数量,不同的模型层计算方法不一样:
- 对于卷积层而言,假设过滤器尺寸为f * f, 过滤器数量为n, 若开启了bias,则bias数固定为1,输入图片的通道数为c,则param计算公式= (f * f * c + 1) * n;
- 对于池化层、flatten、dropout操作而言,是不需要训练参数的,所以param为0;
- 对于全连接层而言,假设输入的列向量大小为i,输出的列向量大小为o,若开启bias,则param计算公式为=i * o + o
按照代码中划分的三组模型层次,其输出尺寸和可训练参数数量的计算方法可如下图所示:
第一组:
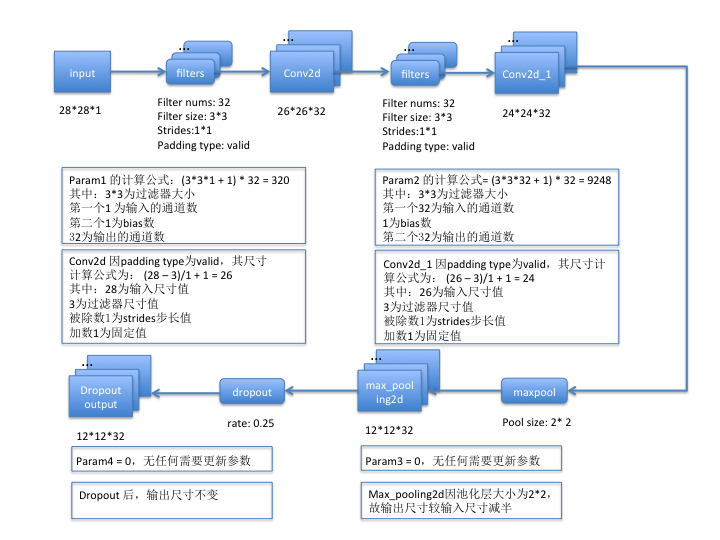
第二组:
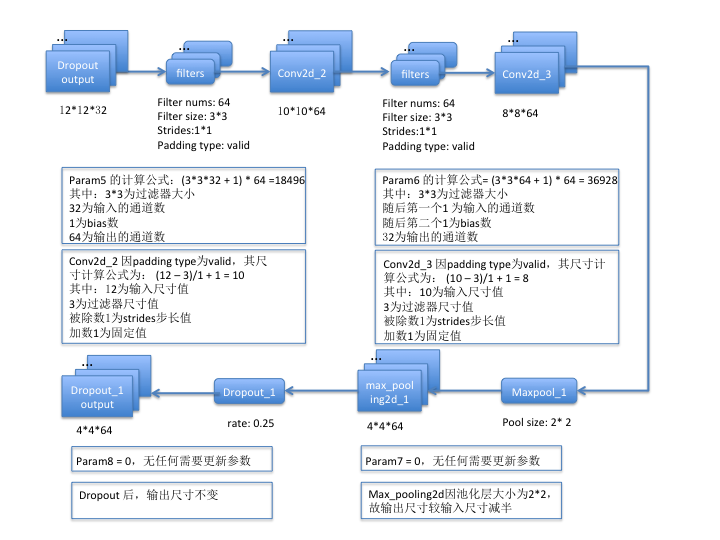
第三组:
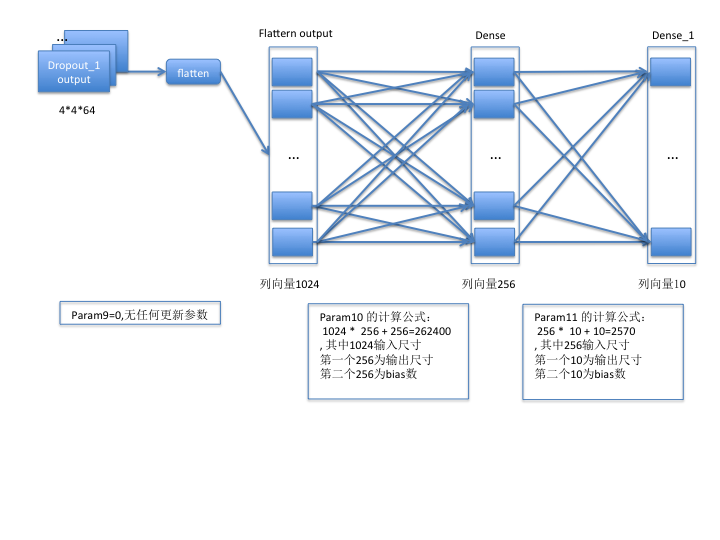
至此,模型各层的含义和相关计算方法已介绍完毕,希望此文能帮助大家更好地理解模型的构成和相关计算。
深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)的更多相关文章
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- pyhton pandas数据分析基础入门(一文看懂pandas)
//2019.07.17 pyhton中pandas数据分析基础入门(一文看懂pandas), 教你迅速入门pandas数据分析模块(后面附有入门完整代码,可以直接拷贝运行,含有详细的代码注释,可以轻 ...
- 深度学习基础系列(十一)| Keras中图像增强技术详解
在深度学习中,数据短缺是我们经常面临的一个问题,虽然现在有不少公开数据集,但跟大公司掌握的海量数据集相比,数量上仍然偏少,而某些特定领域的数据采集更是非常困难.根据之前的学习可知,数据量少带来的最直接 ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
- 深度学习基础系列(七)| Batch Normalization
Batch Normalization(批量标准化,简称BN)是近些年来深度学习优化中一个重要的手段.BN能带来如下优点: 加速训练过程: 可以使用较大的学习率: 允许在深层网络中使用sigmoid这 ...
- 深度学习基础系列(二)| 常见的Top-1和Top-5有什么区别?
在深度学习过程中,会经常看见各成熟网络模型在ImageNet上的Top-1准确率和Top-5准确率的介绍,如下图所示: 那Top-1 Accuracy和Top-5 Accuracy是指什么呢?区别在哪 ...
- 深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释
常见的激活函数有sigmoid.tanh和relu三种非线性函数,其数学表达式分别为: sigmoid: y = 1/(1 + e-x) tanh: y = (ex - e-x)/(ex + e-x) ...
随机推荐
- 全国排名的问题(linq 的连表查询 等同于sql的left join)
前言:要获得全国排名,(因为权限问题,显示的数据不是全国的数据,而是某个分区的数据,因此,不能获得数据后排序得到排名) 显示本部的员工积分并且获得在全国的排名. 我的思路:获得显示的员工信息集合1,获 ...
- Python学习笔记(三十一)正则表达式
---恢复内容开始--- 摘抄自:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000 ...
- JAVA多线程提高八:线程锁技术
前面我们讲到了synchronized:那么这节就来将lock的功效. 一.locks相关类 锁相关的类都在包java.util.concurrent.locks下,有以下类和接口: |---Abst ...
- AngularJs几种服务区别
下面说说这几种函数之间的区别: 函数 定义 适合场景 provider(name, Object OR constructor() ) 一个可配置的.有复杂逻辑的服务.如果你传递了一个对象,那么它应该 ...
- 【转】CentOS7 yum方式配置LAMP环境
采用Yum方式搭建: Apache+Mysql+PHP环境 原文地址: http://www.cnblogs.com/zutbaz/p/4420791.html 1.安装Apache yum inst ...
- 简易版jquery
最近写了一个简易版的jquery github地址:https://github.com/jiangzhenfei/Easy-Jquery 完成的方法: 1.$('#id') 2.extend扩展 ...
- E - Travel Cards CodeForces - 847K (思维)
题目链接:https://cn.vjudge.net/contest/272855#problem/E 题目大意:给你n,a,b,k,f.n代表有n次旅行计划,然后a代表一次单程旅行的车费,b代表从下 ...
- 阿里云一键web环境包
下载地址:https://files.cnblogs.com/files/wordblog/af3a48ef-3a13-479e-85c9-ead61173126c.zip 先把安装包传到服务器上用w ...
- UNIX环境高级编程学习笔记(十)为何 fork 函数会有两个不同的返回值【转】
转自:http://blog.csdn.net/fool_duck/article/details/46917377 以下是基于 linux 0.11 内核的说明. 在init/main.c第138行 ...
- C/C++——二维数组与指针、指针数组、数组指针(行指针)、二级指针的用法
本文转载自:https://blog.csdn.net/qq_33573235/article/details/79530792 1. 二维数组和指针 要用指针处理二维数组,首先要解决从存储的角度对二 ...