009-Hadoop Hive sql语法详解4-DQL 操作:数据查询SQL-select、join、union、udtf
一、基本的Select 操作
语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[ CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
[LIMIT number]
•使用ALL和DISTINCT选项区分对重复记录的处理。
默认是ALL,表示查询所有记录。DISTINCT表示去掉重复的记录
•Where 条件
类似我们传统SQL的where 条件
目前支持 AND,OR ,0.9版本支持between
IN, NOT IN
不支持EXIST ,NOT EXIST
ORDER BY与SORT BY的不同
ORDER BY 全局排序,只有一个Reduce任务
SORT BY 只在本机做排序
Limit
Limit 可以限制查询的记录数
SELECT * FROM t1 LIMIT 5
实现Top k 查询
下面的查询语句查询销售记录最大的 5 个销售代表。
SET mapred.reduce.tasks = 1
SELECT * FROM test SORT BY amount DESC LIMIT 5
REGEX Column Specification
SELECT 语句可以使用正则表达式做列选择,下面的语句查询除了 ds 和 hr 之外的所有列:
SELECT `(ds|hr)?+.+` FROM test
示例
例如
按先件查询
SELECT a.foo FROM invites a WHERE a.ds='<DATE>';
将查询数据输出至目录:
INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>';
将查询结果输出至本地目录:
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
选择所有列到本地目录 :
hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a;
hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a WHERE a.key < 100;
hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/reg_3' SELECT a.* FROM events a;
hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_4' select a.invites, a.pokes FROM profiles a;
hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_5' SELECT COUNT(1) FROM invites a WHERE a.ds='<DATE>';
hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_5' SELECT a.foo, a.bar FROM invites a;
hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/sum' SELECT SUM(a.pc) FROM pc1 a;
将一个表的统计结果插入另一个表中:
hive> FROM invites a INSERT OVERWRITE TABLE events SELECT a.bar, count(1) WHERE a.foo > 0 GROUP BY a.bar;
hive> INSERT OVERWRITE TABLE events SELECT a.bar, count(1) FROM invites a WHERE a.foo > 0 GROUP BY a.bar;
JOIN
hive> FROM pokes t1 JOIN invites t2 ON (t1.bar = t2.bar) INSERT OVERWRITE TABLE events SELECT t1.bar, t1.foo, t2.foo;
将多表数据插入到同一表中:
FROM src
INSERT OVERWRITE TABLE dest1 SELECT src.* WHERE src.key < 100
INSERT OVERWRITE TABLE dest2 SELECT src.key, src.value WHERE src.key >= 100 and src.key < 200
INSERT OVERWRITE TABLE dest3 PARTITION(ds='2008-04-08', hr='12') SELECT src.key WHERE src.key >= 200 and src.key < 300
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/dest4.out' SELECT src.value WHERE src.key >= 300;
将文件流直接插入文件:
hive> FROM invites a INSERT OVERWRITE TABLE events SELECT TRANSFORM(a.foo, a.bar) AS (oof, rab) USING '/bin/cat' WHERE a.ds > '2008-08-09';
This streams the data in the map phase through the script /bin/cat (like hadoop streaming). Similarly - streaming can be used on the reduce side (please see the Hive Tutorial or examples)
2. 基于Partition的查询
一般 SELECT 查询会扫描整个表,使用 PARTITIONED BY 子句建表,查询就可以利用分区剪枝(input pruning)的特性
Hive 当前的实现是,只有分区断言出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝
可以使用 explain dependency语法,获取input table和input partition
3.Join
语法
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON equality_expression ( AND equality_expression )*
equality_expression:
expression = expression
•Hive 只支持等值连接(equality joins)、外连接(outer joins)和(left semi joins)。Hive 不支持所有非等值的连接,因为非等值连接非常难转化到 map/reduce 任务
•LEFT,RIGHT和FULL OUTER关键字用于处理join中空记录的情况
•LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现
•join 时,每次 map/reduce 任务的逻辑是这样的:reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统
•实践中,应该把最大的那个表写在最后
join 查询时,需要注意几个关键点
1、只支持等值join
•SELECT a.* FROM a JOIN b ON (a.id = b.id)
•SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
•可以 join 多于 2 个表,例如
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
2、如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务
3、增加on条件,避免笛卡尔积
4、在Join前使用where过滤不需要的数据

5、小表放在前,大表放在后
原因、在Reduce阶段,位于Join操作符左边的表的内容会被加载进内存,数据越少,越不会发生OOM
3.1、LEFT,RIGHT和FULL OUTER
示例
基础表结构
hive> select * from zz0;
111111
222222
888888
hive> select * from zz1;
111111
333333
444444
888888
join
hive> select * from zz0 join zz1 on zz0.uid = zz1.uid;
111111 111111
888888 888888
left outer join
hive> select * from zz0 left outer join zz1 on zz0.uid = zz1.uid;
111111 111111
222222 NULL
888888 888888
right outer join
hive> select * from zz0 right outer join zz1 on zz0.uid = zz1.uid;
111111 111111
NULL 333333
NULL 444444
888888 888888
full outer join
hive> select * from zz0 full outer join zz1 on zz0.uid = zz1.uid;
111111 111111
222222 NULL
NULL 333333
NULL 444444
888888 888888
left semi join
select * from zz0 left semi join zz1 on zz0.uid = zz1.uid;
111111 111111
888888 888888
说明:1、 JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行
2、于join区别

示例
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
4、UNION ALL
用来合并多个select的查询结果,需要保证select中字段须一致
select_statement UNION ALL select_statement UNION ALL select_statement ...
4.1、优化
利用hive对union all 的优化的特性, hive对union all优化只局限于非嵌套查询

合理使用 union all
不同表太多union all,不推荐使用;
通常采用建临时分区表,将不同表的的结果insert到不同的分区(可并行),最后在统一处理;

4.2、合理使用UDTF
说明
select col1,col2,newCol from myTable LATERAL VIEW explode(myCol) adTable as newCol
说明:执行过程相当于单独执行了两次读取,然后union 到一个表里,但job数只有一个、
同样myCol也需要为数组类型,但日常中我们多数情况下是string类型经过split函数拆分后获取数组类型
示例1:

select id,user,name,city from myTable LATERAL VIEW explode(split(all_citys,',')) adTable as city
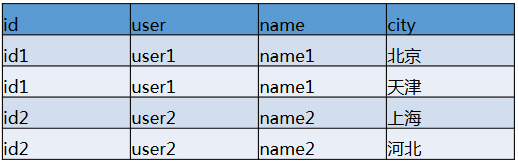
示例2:
应用UDTF优化:按不同维度进行订单汇总:

第一种写法:【3次读取order_table,4个job】
select * from (
select '',province,sum(sales) from order_table group by province
union all
select '',city,sum(sales) from order_table group by city
union ALL
select '',county,sum(sales) from order_table group by county
)df
第二种
select type,code,sum(sales) from(
select split(part,'_')[] as type,
split(part,'_')[] as code,
sales from order_table LATERAK VIEW
explode(split(concat(province,'_1-',city,'_2-',county,'_3'),'-'))
adTable as part
)df group by type,code
009-Hadoop Hive sql语法详解4-DQL 操作:数据查询SQL-select、join、union、udtf的更多相关文章
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- [转]Hadoop Hive sql语法详解
转自 : http://blog.csdn.net/hguisu/article/details/7256833 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式 ...
- Hadoop Hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询 ...
- 【hive】——Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQ ...
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- mysql用户授权、数据库权限管理、sql语法详解
mysql用户授权.数据库权限管理.sql语法详解 —— NiceCui 某个数据库所有的权限 ALL 后面+ PRIVILEGES SQL 某个数据库 特定的权限SQL mysql 授权语法 SQL ...
- 010-Hadoop Hive sql语法详解5-HiveQL与SQL区别
1.Hive不支持等值连接 •SQL中对两表内联可以写成:•select * from dual a,dual b where a.key = b.key;•Hive中应为•select * from ...
- SQL语法详解
ALTER DATABASE修改数据库全局特性 ALTER DATABASE实际上是修改数据库目录中的dp.opt文件 ALTER TABLE修改表的结构 ALTER TABLE对表进行增删列,创建取 ...
随机推荐
- 如意云路由刷PandoraBox
目录 1 准备固件 2 使用uboot刷机 2.1 修改IP 2.2 开始刷写 3 ssh登录 4 刷回如意云 准备固件 http://downloads.openwrt.org.cn/Pandora ...
- Ubuntu之No module named cv2
最简单的方法是:pip install opencv-python 另外,从源码安装的方法: 1下载opencv源码:http://opencv.org/releases.html 推荐2.4.13 ...
- cookie,Session机制的本质,跨应用程序的session共享
目录:一.术语session二.HTTP协议与状态保持三.理解cookie机制四.理解session机制五.理解javax.servlet.http.HttpSession六.HttpSession常 ...
- Spring Cloud都做了哪些事
Spring Cloud是一系列框架的有序集合.它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册.配置中心.消息总线.负载均衡.断路器.数据监控等,都可以用 ...
- printf 字体颜色打印
为了给printf着色方便, 我们可以定义一些宏: view plain copy to clipboard print ? #define NONE "/033[m&qu ...
- [ACM] FZU 2086 餐厅点餐 (枚举)
roblem Description Jack近期喜欢到学校餐厅吃饭.好吃干净还廉价. 在学校餐厅.有a种汤,b种饭.c种面条,d种荤菜,e种素菜. 为了保证膳食搭配,Jack每顿饭都会点1~2样荤菜 ...
- odoo 在原有工作流中添加审批流
odoo 在原有工作流中添加审批流 步骤: 1.加入所需的工作流节点以及相连的线(即所添加的审批流),代码如下: <?xml version="1.0" encoding=& ...
- img与特殊布局下对浏览器渲染的剖析
补白 在内联元素中,分为替换元素和非替换元素(不了解的同学可以百度一下),非替换元素是不可以设置尺寸的,而替换元素作为特殊的内联元素,由于其自身拥有尺寸属性,所以其的尺寸是可以进行再次设置的. 此文适 ...
- 编程之美 set 2 精确表达浮点数
有限小数和无限循环小数转化成分数 比如 0.9 -> 9/10 0.333(3) -> 1/3 解法 1. 主要涉及到一个数学公式的计算. 2. 对于有限小数, 分子分母求最大公约数即可 ...
- 杂记之--苹果4s手机呼叫转移怎么设置
您好,呼叫转移只需在拨号界面输入相应的代码就可以,无需其他设置无条件转移 **21*电话号码#再按拨号键 取消代码:##21# *#21# 再按拨号键无信号,关机转移 **62*电话号码#再按拨号键 ...