Ad Click Prediction: a View from the Trenches (2013)论文阅读
文章链接:
https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/41159.pdf
补充:https://courses.cs.washington.edu/courses/cse599s/14sp/scribes/lecture20/lecture20_draft.pdf
- abstract
FTRL-proximal在线学习算法得到的模型更稀疏、收敛性质更佳,使用各坐标单独的学习率。
- introduction
扩展性问题
省内存、效果分析、置信度预估、校准、特征管理
- brief system overview
revenue = bid price * ctr
目标:预估ctr = P(click | q,a)
特征:query,ad creative text,ad metadata等
方法:regularized logistic regression(正则化逻辑回归,rLR)
平台:Photon(谷歌流式特征平台)
训练方式:DistBelief(谷歌训练平台),Downpour SGD
重点考虑:稀疏性、线上预估阶段延时
- online learning and sparsity
对于大规模在线学习,以LR为例的广义线性模型(generalized linear models)很有优势。十亿维特征,非零值只有几百维,每个样本只读一遍。
LogLoss(logistic loss):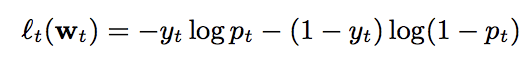
梯度: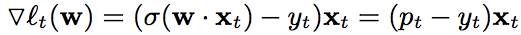
OGD(online gradient descent)适合此类问题,但难得到稀疏解。直接在loss上加L1惩罚不能得到稀疏解(?)
FOBOS和truncated gradient可得到稀疏解,RDA进一步平衡正确率和稀疏性。为了同时拥有RDA的稀疏性(sparsity)和OGD正确性(accuracy)提升,提出FTRL-Proximal。可简单理解为OGD上增加正则项,但是由于各维度独立更新参数w,因此方便引入L1正则。


lambda_1 = 0时两者得到相同参数向量序列,但FTRL-Proximal使用lambda_1 > 0很好地得到稀疏解。
迭代中每维只需要存一个值,更新w方式:

因此对比OGD保留w,FTRL-Proximal内存中只保留z。算法1额外增加了逐维学习率调整,并支持L2正则,存储-eta_t*z_t而非z_t

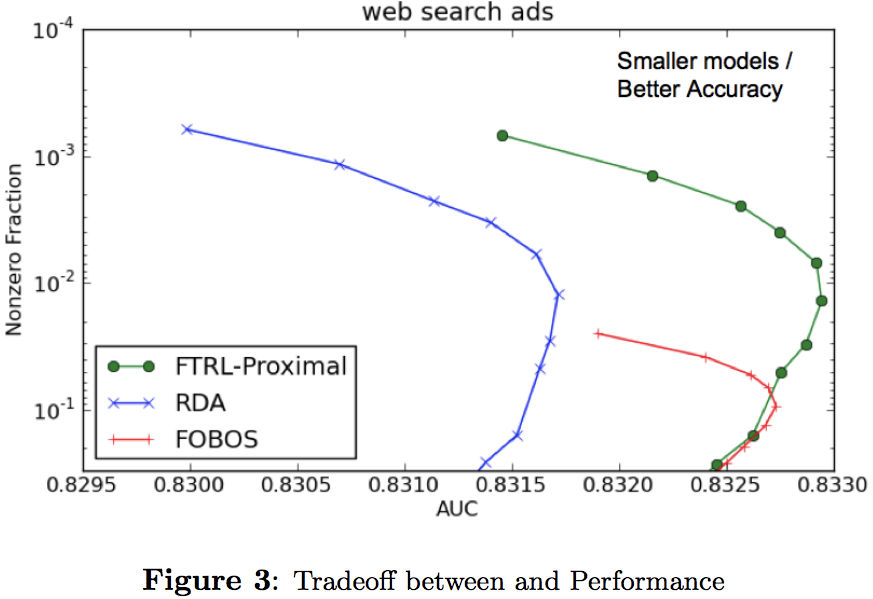
—— experimental results
FTRL-Proximal with L1显著优于RDA和FOBOS,并且很好平衡accuracy和model size。
每维参数不为零要求至少见过k次特征数值。
—— per-coordinate learning rates
逐维设定学习率显著提升效果(高频特征学习率低):
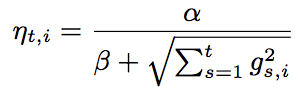
alpha最优值和数据有关,beta取1足够好。效果相对全局唯一学习率AucLoss下降11.2%。
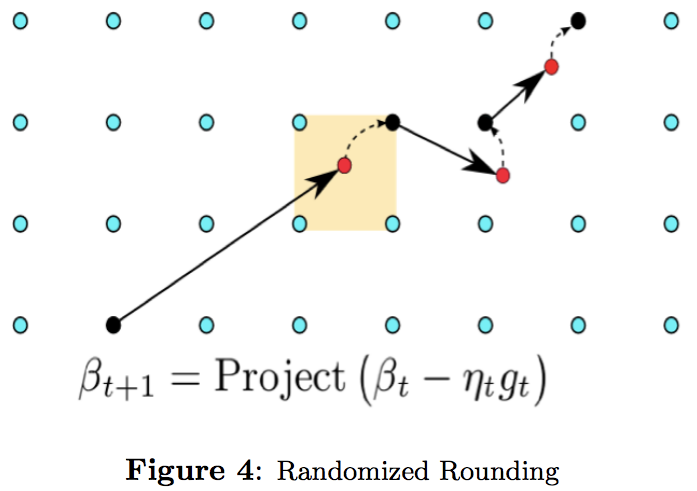
- saving memory at massive scale
包括相似item分组,randomized rounding,L1正则。
—— Probabilistic Feature Inclusion
有些模型情形,十亿级别样本中,一半特征数值只出现一次。
1)Poisson Inclusion:以概率p添加特征
2)Bloom Filter Inclusion:Counting Bloom Filter,设定阈值n
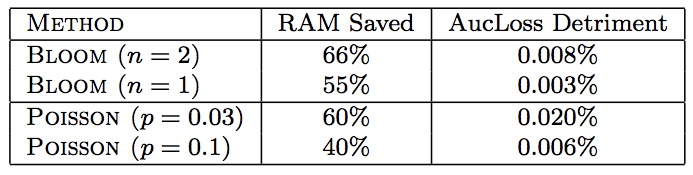
两种方法都不错,BF方式有更好的均衡性(RAM saving和loss)
—— encoding values with fewer bits
【TODO】(没有效果损失)
—— training many similar models
【TODO】
—— a single value structure
【TODO】
—— computing learning rates with counts
【TODO】
—— subsampling training data
1)保留至少点击一个ad的query
2)按概率r采样无点击ad的query
采样query是合理的,因为包含通用特征query phrase。但是要纠偏,对于每个样本计算loss(梯度同理)提权:
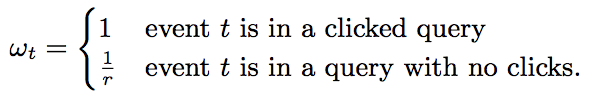
得到相同的期望loss。试验显示激进的下采样对accuracy影响甚微。
- evaluating model performance
AucLoss = 1 - AUC,LogLoss,SquaredError
—— progressive validation
计算评估度量(metrics)在country、query topic、layout等维度
只在最近的数据上度量
绝对度量是有误导性的。输出不点击可以预估为接近50%,可以预估为2%。明显2%更好,所以需要LogLoss这种度量。而且需要在country、query等细分维度做度量。
相对度量也有必要:对比基线(baseline)的相对数值。
—— deep understanding through visualization
大致是可视化细分维度的各种指标
—— confidence estimates
accuracy的预期,用作给explore/exploit算法做参考。本文提出uncertainty score。核心思想是每维保存一个uncertainty counters n_{t,i},用来做学习率调整。大的n_i得到一个小的学习率,因为参数很可能足够精确了。
LogLoss的梯度叫log-odds score = (p_t - y_t),绝对值<=1。假设特征向量长度x_{t,i}<=1,我们能做到根据一个样本(x,y)来预测log-odds。做简化lambda_1 = lambda_2 = 0,如此FTRL-Proximal等效于OGD。
令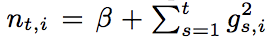 ,结合:
,结合:

—— calibrating predictions
增加校准层(calibration layer)将预估ctr调整到观测ctr。
拟合校准函数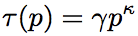 ,p是预估ctr。用Poisson regression在额外的数据上拟合。也可以用单调递增的分段线性函数(折线)或者分段常数函数拟合。比如用isotonic regression(加权最小二乘法拟合)。相对而言分段线性函数能对高和低的边界区域有效纠偏。
,p是预估ctr。用Poisson regression在额外的数据上拟合。也可以用单调递增的分段线性函数(折线)或者分段常数函数拟合。比如用isotonic regression(加权最小二乘法拟合)。相对而言分段线性函数能对高和低的边界区域有效纠偏。
但是没有有效的理论保证校准有效。
- automated feature management
将特征空间组织成各种信号(signals),比如ad words、country,能转换为实数特征。为了管理signals和models,做了metadata index。
- unsuccessful experiments
—— aggressive feature hashing
一些文献声称的feature hashing(用作省内存)的方式在试验中无效。因此保存可解释(即non-hashed)的特征数值向量。
—— dropout
对特征采样的尝试往往是负向的
—— feature bagging
k overlapping subsets of feature space做bagging,结论是大概0.1%-0.6%负向。
—— feature vector normalization
往往负向。
Ad Click Prediction: a View from the Trenches (2013)论文阅读的更多相关文章
- 【Paper】Deep & Cross Network for Ad Click Predictions
目录 背景 相关工作 主要贡献 核心思想 Embedding和Stacking层 交叉网络(Cross Network) 深度网络(Deep Network) 组合层(Combination Laye ...
- 论文阅读(Xiang Bai——【arXiv2016】Scene Text Detection via Holistic, Multi-Channel Prediction)
Xiang Bai--[arXiv2016]Scene Text Detection via Holistic, Multi-Channel Prediction 目录 作者和相关链接 方法概括 创新 ...
- AD阶段分类论文阅读笔记
A Deep Learning Pipeline for Classifying Different Stages of Alzheimer's Disease from fMRI Data -- Y ...
- 论文阅读:Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs(2019 ACL)
基于Attention的知识图谱关系预测 论文地址 Abstract 关于知识库完成的研究(也称为关系预测)的任务越来越受关注.多项最新研究表明,基于卷积神经网络(CNN)的模型会生成更丰富,更具表达 ...
- 各大公司广泛使用的在线学习算法FTRL详解
各大公司广泛使用的在线学习算法FTRL详解 现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据 ...
- 在线最优化求解(Online Optimization)之五:FTRL
在线最优化求解(Online Optimization)之五:FTRL 在上一篇博文中中我们从原理上定性比较了L1-FOBOS和L1-RDA在稀疏性上的表现.有实验证明,L1-FOBOS这一类基于梯度 ...
- 各大公司广泛使用的在线学习算法FTRL详解 - EE_NovRain
转载请注明本文链接:http://www.cnblogs.com/EE-NovRain/p/3810737.html 现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression ...
- Logistic Regression的几个变种
原文:http://blog.xlvector.net/2014-02/different-logistic-regression/ 最近几年广告系统成为很多公司的重要系统之一,定向广告技术是广告系统 ...
- Kaggle : Display Advertising Challenge( ctr 预估 )
原文:http://blog.csdn.net/hero_fantao/article/details/42747281 Display Advertising Challenge --------- ...
随机推荐
- 《深入理解Elasticsearch》README
书目 <深入理解ElasticSearch>拉斐尔·酷奇,马雷克·罗戈任斯基[著]张世武,余洪森,商旦[译] 机械工业出版社,2016.1 本系列包括以下8篇笔记 第01章 Elastic ...
- How do I avoid capturing self in blocks when implementing an API?
Short answer Instead of accessing self directly, you should access it indirectly, from a reference t ...
- Ubuntu使用tzselect修改时区
1.命令行运行 sudo tzselect 2.选择洲区(这里选择亚洲Asia) waichung@desktop:~$ sudo tzselect [sudo] password for waich ...
- Alpha冲刺(十)
Information: 队名:彳艮彳亍团队 组长博客:戳我进入 作业博客:班级博客本次作业的链接 Details: 组员1(组长)柯奇豪 过去两天完成了哪些任务 本人负责的模块(共享编辑)的前端 ...
- Mac下默认JDK路径
2.JDK8以及JDK7安装的默认路径为:/Library/Java/JavaVirtualMachines/jdk1.8.0.jdk
- JAVA并发设计模式学习笔记(一)—— JAVA多线程编程
这个专题主要讨论并发编程的问题,所有的讨论都是基于JAVA语言的(因其独特的内存模型以及原生对多线程的支持能力),不过本文传达的是一种分析的思路,任何有经验的朋友都能很轻松地将其扩展到任何一门语言. ...
- GCT感受
GCT考试已经结束了,但是复习GCT的时候一直没来得及总结点什么,GCT考的比较基础,所以复习起来并不是特别费力,但是还是有一些东西值得我们去学习的. 对于GCT考试,一开始在报名的时候其实心里是挺抵 ...
- Rsync+Inotify实现文件自动同步
1>rsync概述 rsync的优点与不足 rsync与传统的cp.tar备份方式相比,rsync具有安全性高.备份迅速.支持增量备份等优点,通过rsync可以解决对实时性要求不高的数据备份需求 ...
- Arduino I2C + 气压传感器LPS25H
LPS25H是ST生产的MEMS数字气压传感器.主要特性有: 测量范围:260 ~ 1260 hPa绝对气压 分辨率:均方根1 Pa 工作电压:1.7 ~ 3.6 V 功耗:4μA(低分辨率模式)~2 ...
- Redis分布式锁方案