day5-re模块
一、概述
但凡有过语言开发经验的童鞋都清楚,很多时候需要进行字符串的匹配搜索、查找替换等处理,此时正则表达式就是解决问题的不二法门。正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程:
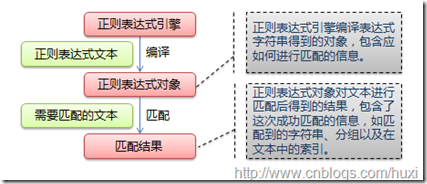
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的(以上文字和图片版权归大神AstralWind所有,引用自http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html)。
匹配过程和规则详见下一章节。
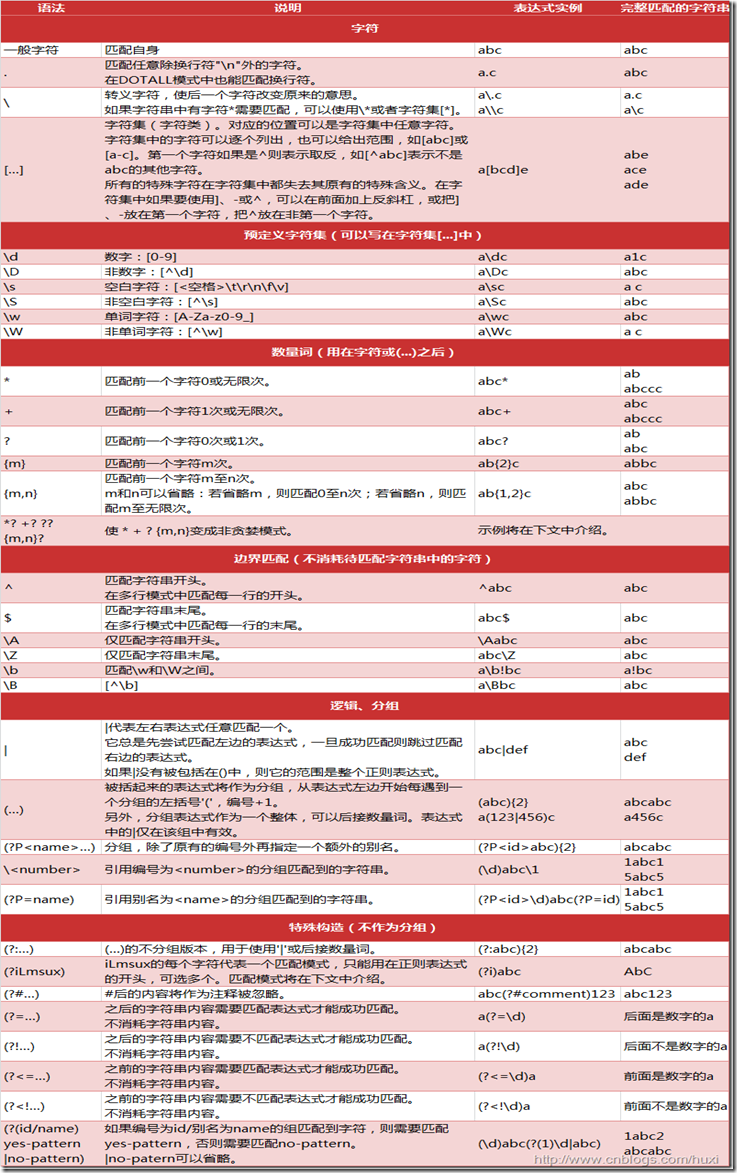
二、正则表达式元字符和语法
正则表达式之所以功能强大,在于丰富的元字符。Python中常用的元字符和语法如下(感谢大神AstralWind的分享,图片引用自http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html):
三、re模块的常见匹配方法
- re.match(pattern, string, flags=0)
功能:在string的开始位置开始匹配指定的字符串1 >>> import re
2 #从字符串开始位置匹配,匹配失败
3 >>> print(re.match('abc', '1abc123').group())
4 Traceback (most recent call last):
5 File "<stdin>", line 1, in <module>
6 AttributeError: 'NoneType' object has no attribute 'group'
7 #匹配失败返回None
8 >>> print(re.match('abc', '1abc123'))
9 None
10 #匹配成功
11 >>> print(re.match('abc', 'abc123').group())
12 abc
13 >>> print(re.match('abc', 'abc123'))
14 <_sre.SRE_Match object; span=(0, 3), match='abc'> - re.search(pattern, string, flags=0)
功能:在string中查找指定的字符串,位置任意1 >>> import re
2 #把match改为search后匹配成功
3 >>> print(re.search('abc', '1abc123').group())
4 abc
5 >>> print(re.search('abc', '1abc123'))
6 <_sre.SRE_Match object; span=(1, 4), match='abc'>
7 #使用元字符匹配
8 >>> print(re.search('[a-z]+\d', 'abc123abc'))
9 <_sre.SRE_Match object; span=(0, 4), match='abc1'> - re.findall(pattern, string, flags=0)
功能:把匹配到的字符以列表的形式返回1 >>> import re
2 #默认最长匹配,能匹配多少次就匹配多少次,下文会有专门章节讲述
3 >>> print(re.findall('abc', '1abc123abc'))
4 ['abc', 'abc']
5 >>> print(re.findall('abc', '1abc123ab2c'))
6 ['abc'] - re.split(pattern, string, maxsplit=0, flags=0)
功能:以指定的pattern作为分隔符来分割指定的字符串,然后以列表形式返回分割后的结果1 >>> import re
2 >>>
3 >>> print(re.split('\d', 'a1b2c3'))
4 ['a', 'b', 'c', '']
5 >>> print(re.split('\d', '1a1b2c3'))
6 ['', 'a', 'b', 'c', '']
7 >>>如果指定的分隔符在字符串中不存在,则直接返回以完整字符串为唯一元素的列表
1 >>> import re
2 >>> print(re.split('\d', 'abc'))
3 ['abc']
4 >>> print(re.split('\s', 'abc'))
5 ['abc'] - re.sub(pattern, repl, string, count=0, flags=0)
功能:查找匹配string中的patter,并用repl进行替换。默认替换全部,可通过count来限定替换的次数。1 >>> import re
2 >>> print(re.sub('\d', '\s', 'abc123abc'))
3 abc\s\s\sabc
4 >>> print(re.sub('[a-z]', '0', 'abc123abc'))
5 000123000
6 #限定仅替换3次
7 >>> print(re.sub('[a-z]', '0', 'abc123abc', count=3))
8 000123abc - finditer(pattern, string)
功能:返回一个迭代器1 >>> import re
2 >>> print(re.finditer('abc', 'abc123'))
3 <callable_iterator object at 0x00000000025AD2B0>
4 >>> print(re.finditer('abc2', 'abc123'))
5 <callable_iterator object at 0x00000000025AD390>目前尚不明确具体使用场景,代码验证无论匹配是否成功都会返回一个迭代器对象,意义何在呢?
四、re模块的特殊用法和匹配模式
4.1 特殊用法
- group([group1, ...])
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串(即匹配到pattern的完整子串);不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
这里的多个参数指的是匹配到了多个分组,然后通过分组编号或别名形式指定返回的分组。
需要注意的是如果要匹配多个分组,每个分组都需要在pattern中用圆括号括起来,以明确表示这是一个分隔的单独分组;另外re模块的常见匹配函数中,只有match、search有group方法,其他的函数没有。1 >>> import re
2 >>> a=re.search('(\w+)\s(\w+)', 'hello world')
3 >>> print(a.group(1,2))
4 ('hello', 'world')
5 >>> print(a.group())
6 hello world
7 #为分组4定义一个别名
8 >>> b=re.match('(\w+)\s(\w+)\s(\w+)\s(?P<gender>\w+)', 'Maxwell is a man')
9 >>> print(b.group())
10 Maxwell is a man
11 #通过分组编号获取匹配的分组
12 >>> print(b.group(4))
13 man
14 #通过别名获取匹配分组,注意别名要引起来
15 >>> print(b.group('gender'))
16 man - groups(default=None)
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。这个要跟分组匹配结合起来使用'(...)'。由于返回的结果是元组形式,因此可以通过len(a.groups())来获取分组的个数。1 >>> import re
2 >>> a=re.search('(\w+)\s(\w+)', 'hello world')
3 >>> print(a.groups())
4 ('hello', 'world')
5 #获取分组个数
6 >>> print(len(a.groups()))
7 2
8
9 #由于返回的是元组形式,因此可以通过len()获取到匹配到的分组个数 - groupdict(default=None)
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。这个是跟另外一个分组匹配结合起来用的,即:'(?P<name>...)'。
这里的前提是先定义匹配分组的别名,方法很简单,每一个别名都通过(?P<name>pattern)定义即可,当然引号是所有分组共用的啦1 >>> import re
2 >>> a=re.match('(?P<province>\d{4})(?P<city>\d{2})(?P<birthday>\d{8})(?P<id>\d{4})','510123199502162018')
3 >>> print(a.group())
4 510123199502162018
5 >>> print(a.groupdict())
6 {'province': '5101', 'city': '23', 'birthday': '19950216', 'id': '2018'}
7 >>> print(a.groupdict('birthday'))
8 {'province': '5101', 'city': '23', 'birthday': '19950216', 'id': '2018'}这里有些不太明白的是,既然返回的结果是一个标准的dict,为什么直接打印整个dict和打印某个key的结果相同呢?如果仅仅需要获取某个分组还是必须得通过a.group(‘alias’)吗?
- span([group])
返回(start(group), end(group)),返回指定匹配的pattern在源字符串中的起始位置和结束位置(实际在match和search的返回结果中有显示)1 >>> import re
2 >>> print(re.search('[a-z]+\d', 'abc123abc'))
3 <_sre.SRE_Match object; span=(0, 4), match='abc1'>
4 >>> print(re.search('[a-z]+\d', 'abc123abc').span())
5 (0, 4) - start([group])
返回匹配的完整子串在源string中的起始索引位置,即span()输出的起始索引位置。1 >>> import re
2 >>> a=re.search('(\w+)\s+(\w+)', 'hello world')
3 >>> a.group()
4 'hello world'
5 >>> a.group(1)
6 'hello'
7 >>> a.group(2)
8 'world'
9 >>> a.start()
10 0
11 >>> a.span()
12 (0, 11) - end([group])
返回匹配的完整子串在源string中的结束索引位置,即span()输出的结束索引位置。1 >>> import re
2 >>> a=re.search('(\w+)\s+(\w+)', 'hello world')
3 >>> a.group()
4 'hello world'
5 >>> a.group(1)
6 'hello'
7 >>> a.group(2)
8 'world'
9 >>> a.end()
10 11
11 >>> a.span()
12 (0, 11) - compile(pattern[, flags])
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。还记得文章开头概述部分讲到的正则表达式匹配流程吗?第一步就是通过正则表达式引擎把正则表达式文本pattern编译为正则表达式pattern对象,因此compile这个环节无需手动完成,个人理解通过手动编译好的正则表达式对象对匹配只是理论上时间少那么一丢丢吧,完全可以忽略了。1 >>> import re
2 >>> a=re.compile('(\w+)\s+(\w+)')
3 >>> b=a.search('hello world')
4 >>> b.group()
5 'hello world'
使用compile有一个好处是可以复用pattern对象的一些属性,如输出定义的pattern,groups数量,定义有别名的分组的索引等,可能有那么一点用处
把。
1 >>> a=re.compile('(\w+)\s+(\w+)')
2 >>> print(a.pattern)
3 (\w+)\s+(\w+)
4 >>> print(a.groups)
5 2
6 >>> print(a.flags)
7 32
8 >>> print(a.groupindex)
9 {}
10 >>> b=re.compile('(\w+)\s+(?P<keyword>\w+)')
11 >>> print(b.groupindex)
12 {'keyword': 2}
13 >>> print(b.groups)
14 2
- 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
这里的加r直白理解是可以免去人工处理转义符的麻烦,说的官方一些是跳脱解释器对转义符的解释,保留转义符’\’原本的字符串反斜杠意义,算是返璞归真吧。1 >>> import re
2 >>> a='hello\nworld'
3 >>> print(a)
4 hello
5 world
6 #跳脱转义符,\n被当做普通字符串处理
7 >>> a=r'hello\nworld'
8 >>> print(a)
9 hello\nworld
10注意:
细心的同学会发现上述论述存在一个看似相互矛盾的问题,在不考虑加r的情况下,为什么匹配一个反斜杠需要4个反斜杠来转义3次,而匹配一个数字的\\d只需要两个反斜杠转义一次就可以了呢?这是因为\d是一个元字符,python解释器内部作了特殊处理,除元字符外,其他情况下的反斜杠匹配,在不加r的前提下都需要不厌其烦地写4次从而转义3次。
当然,这里的’\\d’两个反斜杠前面的那个对后面的反斜杠进行转义,最后给到解释器的就是‘\d’, 这里有一个斜杠是多余了,加r也多余了,忘掉“同样,匹配一个数字的"\\d"可以写成r"\d"”这段文字把,简单就好啊!1 >>> import re
2 >>> a = re.split("\\\\","C:\download\test")
3 >>> print(a)
4 ['C:', 'download\test']
5 >>> a = re.split(r"\\","C:\download\test")
6 >>> print(a)
7 ['C:', 'download\test']
8 >>>
9 >>>
10 >>> b=re.split('\\d','a1b2c3')
11 >>> print(b)
12 ['a', 'b', 'c', '']
13 >>> b=re.split(r'\d','a1b2c3')
14 >>> print(b)
15 ['a', 'b', 'c', '']
16 >>> b=re.split('\d','a1b2c3')
17 >>> print(b)
18 ['a', 'b', 'c', '']
19 >>>
4.2 匹配模式
正则表达式提供了一些可用的匹配模式,用于改变默认的匹配模式,比如忽略大小写、忽略换行进行多行匹配等,可以满足我们在实际应用中的复杂匹配需求,比如爬虫需要爬js代码等。这些匹配模式都是在匹配方法中通过flags参数来指定的。
- re.I(flags=
re.IGNORECASE)
说明:忽略大小写(括号内是完整的写法,下同)1 >>> import re
2 >>> a=re.search('hello', 'Hello world')
3 >>> print(a.group())
4 Traceback (most recent call last):
5 File "<stdin>", line 1, in <module>
6 AttributeError: 'NoneType' object has no attribute 'group' #匹配失败
7 >>> a=re.search('hello', 'Hello world', re.I)
8 >>> print(a.group())
9 Hello
10 >>> - re.M(flags=
MULTILINE)
说明:多行模式,改变'^'和'$'的匹配行为,使得他们中间也能包括换行符。1 >>> import re
2 >>> a='This is the first line.\nThis is the second line.'
3 >>> print(a)
4 This is the first line.
5 This is the second line.
6 >>> b=re.search('This.*line\.', a)
7 >>> print(b.group())
8 This is the first line.
9 >>> b=re.search('This.*line\.', a, re.S)
10 >>> print(b.group())
11 This is the first line.
12 This is the second line.
13 >>> b=re.findall('^This.*line\.$',a)
14 >>> print(b)
15 []
16 #pattern添加?改成非贪婪模式匹配
17 >>> b=re.findall('^This.*?line\.$',a,re.M)
18 >>> print(b)
19 ['This is the first line.', 'This is the second line.'] - re.S(flags=
DOTALL)
说明:点任意匹配模式,改变'.'的行为。有些地方也成为单行模式,使得点号也能匹配换行符(点号原本是可以匹配任何字符,唯独换行符要除外)。1 >>> import re
2 >>> a='This is the first line.\nThis is the second line.'
3 >>> print(a)
4 This is the first line.
5 This is the second line.
6 >>> b=re.search('This.*line\.', a)
7 >>> print(b.group())
8 This is the first line.
9 >>> b=re.search('This.*line\.', a, re.S)
10 >>> print(b.group())
11 This is the first line.
12 This is the second line.我们知道正则默认的匹配模式是尽可能长地贪婪匹配,删除程序中由于点号默认不能匹配换行符,因此在使用re.S之前只能匹配出一行。
上面三种匹配模式,忽略大小写非常实用,而多行模式和单行模式,则是匹配跨行文本的利器。
上面示例程序中,即便是把匹配用的pattern通过添加?改变成非贪婪模式匹配(贪婪模式与非贪婪模式下面章节会详细阐述),依然能匹配成功,这是因为在多行模式下,^除了匹配整个字符串的起始位置,还匹配换行符后面的位置;$除了匹配整个字符串的结束位置,还匹配换行符前面的位置。简而言之,多行模式允许 ^和$中间出现换行符。
五、贪婪匹配与非贪婪匹配
OK,要用好正则表达式,贪婪匹配与非贪婪匹配非得整明白不可。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符(最长匹配模式);非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式”ab*”如果用于查找”abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab*?”,将找到”a”。
引用一段网上找到的博文把:
标准量词修饰的子表达式,在可匹配可不匹配的情况下,总会先尝试进行匹配,称这种方式为匹配优先,或者贪婪模式。此前介绍的一些量词,“{m}”、“{m,n}”、“{m,}”、“?”、“*”和“+”都是匹配优先的。
一些NFA正则引擎支持忽略优先量词,也就是在标准量词后加一个“?”,此时,在可匹配可不匹配的情况下,总会先忽略匹配,只有在由忽略优先量词修饰的子表达式,必须进行匹配才能使整个表达式匹配成功时,才会进行匹配,称这种方式为忽略优先,或者非贪婪模式。忽略优先量词包括“{m}?”、“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”(以上论述引用自http://blog.csdn.net/haoxizh/article/details/44648069)。
上述文字有部分地方讲得略生涩,通俗一些理解:贪婪模式是尽可能多尽可能长地匹配,能匹配多长能匹配多少就是多少,所以叫匹配优先;非贪婪模式恰好相反,只要满足最小条件下的匹配即可,即尽可能少尽可能短地匹配,它的宗旨是匹配一次即可,多余的统统忽略不管。
还是来几个栗子更清楚直观了:
1 >>> import re
2 >>> print(re.findall('ab*','abbbc'))
3 ['abbb']
4 >>> print(re.findall('ab*?','abbbc'))
5 ['a']
6 >>> print(re.findall('ab{2}','abbbc'))
7 ['abb']
8 #对于单个指定匹配多少次的情况,非贪婪模式与贪婪模式匹配的结果相同
9 >>> print(re.findall('ab{2}?','abbbc'))
10 ['abb']
11 >>> print(re.findall('ab{1,3}','abbbc'))
12 ['abbb']
13 >>> print(re.findall('ab{1,3}?','abbbc'))
14 ['ab']
15 >>> print(re.findall('ab{1,}','abbbc'))
16 ['abbb']
17 >>> print(re.findall('ab{1,}?','abbbc'))
18 ['ab']
19 >>> print(re.findall('ab?','abbbc'))
20 ['ab']
21 >>> print(re.findall('ab??','abbbc'))
22 ['a']
23 >>> print(re.findall('ab+','abbbc'))
24 ['abbb']
25 >>> print(re.findall('ab+?','abbbc'))
26 ['ab']
从上述示例程序可以看出,非贪婪模式改变了数量词的默认匹配行为,对于数量词指定的匹配的下限次数和上限次数({m,n},{m,})情况,以及匹配时的次数可少也可以多的情况(*,?,+),统统按最少匹配次数(最短匹配)来处理。
另外需要注意的是,引用的博文论述中对于{m}?的描述不太准确,示例程序显示这种情况下由于匹配的次数已经指定且是唯一的,因此非贪婪模式的匹配效果不能直观体现出来,忘掉这个吧。
由于Python中默认的匹配模式是贪婪模式,实际应用中非贪婪模式用的很多的。
day5-re模块的更多相关文章
- Python学习-day5 常用模块
day5主要是各种常用模块的学习 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 conf ...
- Python 之路 Day5 - 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- [Python Day5] 常用模块
目录: 1.模块介绍 2.time & datetime 3.random 4.OS 5.sys 6.shutil 7.json & pickle 8.shelve 9.xml 处理 ...
- python 学习day5(模块)
一.模块介绍 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能 ...
- 小白的Python之路 day5 python模块详解及import本质
一.定义 模块:用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能) 本质就是.py结尾的python文件(文件名:test.py,对应的模块名:test) 包:用来从逻辑上组织模块 ...
- 小白的Python之路 day5 random模块和string模块详解
random模块详解 一.概述 首先我们看到这个单词是随机的意思,他在python中的主要用于一些随机数,或者需要写一些随机数的代码,下面我们就来整理他的一些用法 二.常用方法 1. random.r ...
- 小白的Python之路 day5 shutil模块
shutil模块 一.主要用途 高级的文件.文件夹.压缩包 等处理模块 二.常用方法详解 1.shutil.copyfileobj(fsrc, fdst) 功能:把一个文件的内容拷贝到另外一个文件中, ...
- 小白的Python之路 day5 shelve模块讲解
shelve模块讲解 一.概述 之前我们说不管是json也好,还是pickle也好,在python3中只能dump一次和load一次,有什么方法可以向dump多少次就dump多少次,并且load不会出 ...
- 小白的Python之路 day5 configparser模块的特点和用法
configparser模块的特点和用法 一.概述 主要用于生成和修改常见配置文件,当前模块的名称在 python 3.x 版本中变更为 configparser.在python2.x版本中为Conf ...
- 小白的Python之路 day5 hashlib模块
hashlib模块 一.概述 用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 二.算法的演 ...
随机推荐
- 搜狗员工用百度算什么,谷歌员工当着老板的面用bing,结果悲剧了!
之前看到一篇文章,写的是搜狗的员工遇到问题时,用百度,结果网友的评论真是亮瞎眼.今天,W3Cschool小师妹将为大家分享一个类似的故事,那就是谷歌员工当着老板的面,竟然用BING. 这位谷歌员工称, ...
- Winter-2-STL-E Andy's First Dictionary 解题报告及测试数据
use stringstream Time Limit:3000MS Memory Limit:0KB Description Andy, 8, has a dream - he wants ...
- LeetCode 902. Numbers At Most N Given Digit Set
应该是常数 N的位数时间级别 我的这个方法超时很严重...但是特此记录 费劲巴拉写的... 超时: int atMostNGivenDigitSet(char** D, int DSize, int ...
- Linux中LVM2原理
一.LVM原理 [MD]:Multi Device 多设备 Mdadm是一个用户空间工具,是RAID的管理工具,与真正的RAID工作没有太大关系.真正的RAID集成在linux内核中 [DM]Devi ...
- LVM2逻辑卷创建及扩容
LVM是Logical Volume Manager(逻辑卷管理器)的简写,又译为逻辑卷宗管理器.逻辑扇区管理器.逻辑磁盘管理器.是Linux核心所提供的逻辑卷管理(Logical Volume Ma ...
- window连接linux共享
前提说明:windows主机信息:192.168.1.100 帐号:abc 密码:123 共享文件夹:sharelinux主机信息:192.168.1.200 帐号:def 密码:456 共享文件夹: ...
- Python学习笔记之Centos6.9安装Python3.6
0x00 注意 如果本机安装了python2,尽量不要管他,使用python3运行python脚本就好,因为可能有程序依赖目前的python2环境, 比如yum!!!!! 不要动现有的python2环 ...
- nfs挂载
安装: yum install nfs-utils rpcbind 配置共享目录:vim /etc/exports /xxx/cloudcms *(insecure,rw,async,no_root_ ...
- 从HighGUI的一段代码中看OpenCV打开视频的方式
OpenCV的HighGUI提供了视频和摄像头的直接打开.那么它是如何实现的了?这里进行初步分析. ; switch(apiPreference) { default: ...
- Java学习第四周学习笔记
20145307<Java程序设计>第4周学习总结 教材学习内容总结 继承与多态 继承 继承作为面向对象的第二大特征,基本上就是避免多个类间重复定义共同行为.即当多个类中存在相同属性和行为 ...