教你如何挑选深度学习GPU【转】
本文转载自:https://blog.csdn.net/qq_38906523/article/details/78730158
即将进入 2018 年,随着硬件的更新换代,越来越多的机器学习从业者又开始面临选择 GPU 的难题。正如我们所知,机器学习的成功与否很大程度上取决于硬件的承载能力。在今年 5 月,我在组装自己的深度学习机器时对市面上的所有 GPU 进行了评测。而在本文中,我们将更加深入地探讨:
为什么深度学习需要使用 GPU
GPU 的哪种性能指标最为重要
选购 GPU 时有哪些坑需要避免
性价比
每个价位的最佳选择
GPU + 深度学习
深度学习(DL)是机器学习(ML)的一个分支。深度学习使用神经网络来解决问题。神经网络的优点之一是自行寻找数据(特征)模式。这和以前告诉算法需要找什么不一样。但是,通常这意味着该模型从空白状态开始(除非使用迁移学习)。为了从头捕捉数据的本质/模式,神经网络需要处理大量信息。通常有两种处理方式:使用 CPU 或 GPU。
计算机的主要计算模块是中央处理器(CPU),CPU 的设计目的是在少量数据上执行快速计算。在 CPU 上添加数倍的数字非常快,但是在大量数据上进行计算就会很慢。如,几十、几百或几千次矩阵乘法。在表象背后,深度学习多由矩阵乘法之类的操作组成。
有趣的是,3D 电子游戏同样依赖这些操作来渲染那些美丽的风景。因此,GPU 的作用被开发出来,它们可以使用数千个核心处理大量并行计算。此外,它们还有大量内存带宽处理数据。这使得 GPU 成为进行 DL 的完美硬件。至少,在用于机器学习的 ASIC 如谷歌的 TPU 投入市场之前,我们还没有其他更好的选择。
总之,尽管使用 CPU 进行深度学习从技术上是可行的,想获得真实的结果你就应该使用 GPU。
对我来说,选择一个强大的图形处理器最重要的理由是节省时间和开发原型模型。网络训练速度加快,反馈时间就会缩短。这样我就可以更轻松地将模型假设和结果之间建立联系。
选择 GPU 的时候,我们在选择什么?
和深度学习相关的主要 GPU 性能指标如下:
内存带宽:GPU 处理大量数据的能力,是最重要的性能指标。
处理能力:表示 GPU 处理数据的速度,我们将其量化为 CUDA 核心数量和每一个核心的频率的乘积。
显存大小:一次性加载到显卡上的数据量。运行计算机视觉模型时,显存越大越好,特别是如果你想参加 CV Kaggle 竞赛的话。对于自然语言处理和数据分类,显存没有那么重要。
常见问题
多 GPU(SLI/交火)
选择多 GPU 有两个理由:需要并行训练多个模型,或者对单个模型进行分布式训练。
并行训练多个模型是一种测试不同原型和超参数的技术,可缩短反馈周期,你可以同时进行多项尝试。
分布式训练,或在多个显卡上训练单个模型的效率较低,但这种方式确实越来越受人们的欢迎。现在,使用 TensorFlow、Keras(通过 Horovod)、CNTK 和 PyTorch 可以让我们轻易地做到分布式训练。这些分布式训练库几乎都可以随 GPU 数量达成线性的性能提升。例如,使用两个 GPU 可以获得 1.8 倍的训练速度。
PCIe 通道:使用多显卡时需要注意,必须具备将数据馈送到显卡的能力。为此,每一个 GPU 必须有 16 个 PCIe 通道用于数据传输。Tim Dettmers 指出,使用两个有 8 个 PCIe 通道的 GPU,性能应该仅降低「0—10%」。
对于单个 GPU 而言,任何桌面级处理器和芯片组如 Intel i5 7500 和 Asus TUF Z270 需要使用 16 个通道。
然而,对于双 GPU,你可以使用 8x/8x 通道,或者使用一个处理器和支持 32PCIe 通道的主板。32 个通道超出了桌面级 CPU 的处理能力。使用 Intel Xeon 组合 MSI—X99A SLI PLUS 是可行的方案。
对于 3 个或 4 个 GPU,每个 GPU 可使用 8x 通道,组合支持 24 到 32 个 PCIe 通道的 Xeon。
如果需要使用 3 到 4 个有 16 个 PCIe 通道的 GPU,你得有一个怪兽级处理器。例如 AMD ThreadRipper(64 个通道)和相应的主板。
总之,GPU 越多,需要越快的处理器,还需要有更快的数据读取能力的硬盘。
英伟达还是 AMD
英伟达已经关注深度学习有一段时间,并取得了领先优势。他们的 CUDA 工具包具备扎实的技术水平,可用于所有主要的深度学习框架——TensorFlow、PyTorch、Caffe、CNTK 等。但截至目前,这些框架都不能在 OpenCL(运行于 AMD GPU)上工作。由于市面上的 AMD GPU 便宜得多,我希望这些框架对 OpenCL 的支持能尽快实现。而且,一些 AMD 卡还支持半精度计算,从而能将性能和显存大小加倍。
今年夏天,AMD 还发布了 ROCm 平台提供深度学习支持,它同样适用于主流深度学习库(如 PyTorch、TensorFlow、MxNet 和 CNTK)。目前,ROCm 仍然在不断开发中。
然而目前而言,如果想做深度学习的话,还是选择英伟达吧。
其它硬件
你的 GPU 还需要以下这些硬件才能正常运行:
硬盘:首先需要从硬盘读取数据,我推荐使用固态硬盘,但机械硬盘也可以。
CPU:深度学习任务有时需要用 CPU 解码数据(例如,jpeg 图片)。幸运的是,任何中端现代处理器都能做得不错。
主板:数据需要通过主板传输到 GPU 上。单显卡可以使用几乎任何芯片组都可以使用。
RAM:一般推荐内存的大小至少和显存一样大,但有更多的内存确实在某些场景是非常有帮助的,例如我们希望将整个数据集保存在内存中。
电源:一般来说我们需要为 CPU 和 GPU 提供足够的电源,至少需要超过额定功率 100 瓦。
我们总体上需要 500 到 1000 美元来获得以上设备,当然如果买一个二手工作站会更加省钱。
GPU 性能对比(2017 年 11 月)
下面是截止目前英伟达产品线主要 GPU 的性能对比,每个 GPU 的 RAM 或内存带宽等信息都展示在图表中。注意 Titan XP 和 GTX 1080 Ti 尽管价格相差非常多,但它们的性能却非常相近。
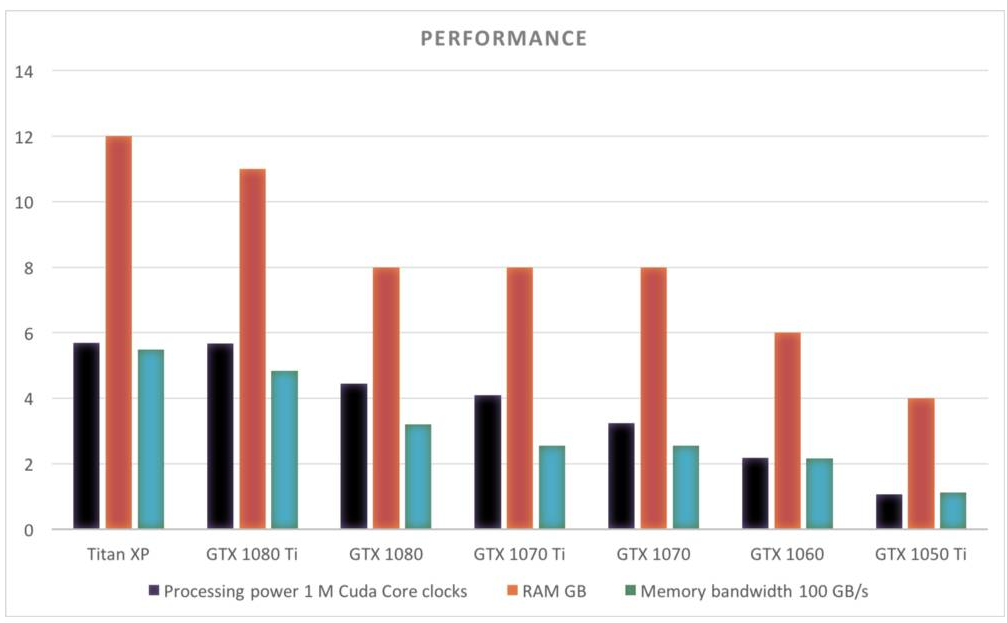
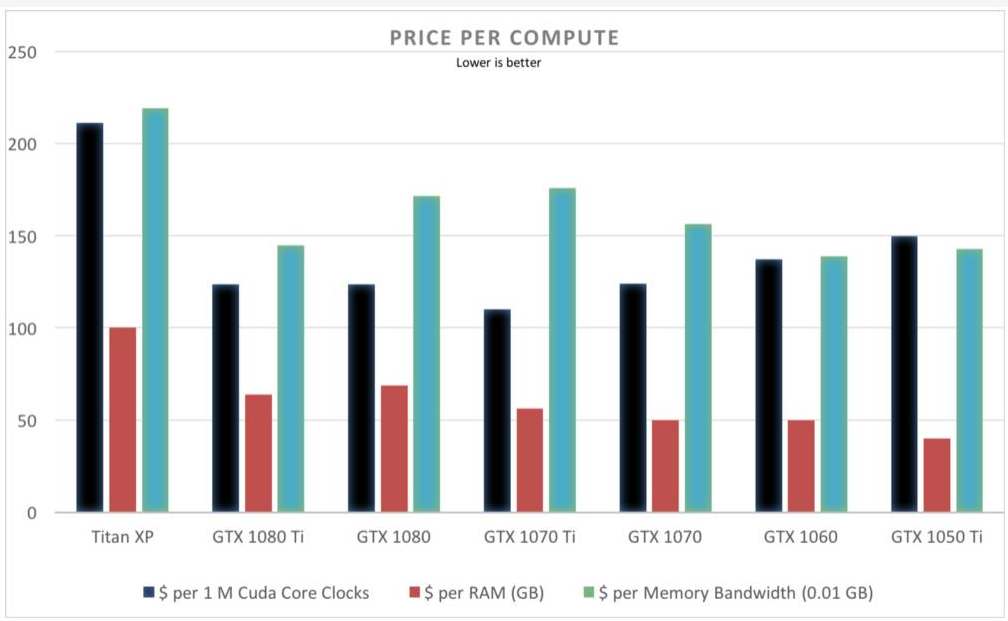
价格对比表明 GTX 1080 Ti、GTX 1070 和 GTX 1060 的性价比较高。所有GPU都是几乎相同的比值,除了 Titan XP。
Titan XP
参数:
显存(VRAM):12 GB
内存带宽:547.7 GB/s
处理器:3840 个 CUDA 核心 @ 1480 MHz(约 5.49 亿 CUDA 核心频率)
英伟达官网价格:9700 元
Titan XP 是目前英伟达消费级显卡的旗舰产品,正如性能指标所述,12GB 的内存宣示着它并不是为大多数人准备的,只有当你知道为什么需要它的时候,它才会位列推荐列表。
一块 Titan XP 的价格可以让你买到两块 GTX 1080,而那意味着强大的算力和 16GB 的显存。
GTX 1080 Ti
参数:
显存(VRAM):11 GB
内存带宽:484 GB/s
处理器:3584 个 CUDA 核心 @ 1582 MHz(约 5.67 亿 CUDA 核心频率)
英伟达官网价格:4600 元
这块显卡正是我目前正在使用的型号,它是一个完美的高端选项,拥有大容量显存和高吞吐量,物有所值。
如果资金允许,它是一个很好的选择。GTX 1080 Ti 可以让你完成计算机视觉任务,并在 Kaggle 竞赛中保持强势。
GTX 1080
参数:
显存(VRAM):8 GB
内存带宽:320 GB/s
处理器:2560 个 CUDA 核心 @ 1733 MHz(约 4.44 亿 CUDA 核心频率)
英伟达官网价格:3600 元
作为目前英伟达产品线里的中高端显卡,GTX 1080 的官方价格从 1080 Ti 的 700 美元降到了 550 美元。8 GB 的内存对于计算机视觉任务来说够用了。大多数 Kaggle 上的人都在使用这款显卡。
GTX 1070 Ti
参数:
显存(VRAM):8 GB
内存带宽:256 GB/s
处理器:2432 个 CUDA 核心 @ 1683 MHz(约 4.09 亿 CUDA 核心频率)
英伟达官网价格:3000 元
11 月 2 日推出的 GTX 1070 Ti 是英伟达产品线上最新的显卡。如果你觉得 GTX 1080 超出了预算,1070 Ti 可以为你提供同样大的 8 GB 显存,以及大约 80% 的性能,价格也打了八折,看起来不错。
GTX 1070
参数:
显存(VRAM):8 GB
内存带宽:256 GB/s
处理器:1920 个 CUDA 核心 @ 1683 MHz(约 3.23 亿 CUDA 核心频率)
英伟达官网价格:2700 元
现在很难买到这款 GPU 了,因为它们主要用于虚拟货币挖矿。它的显存配得上这个价位,就是速度有些慢。如果你能用较便宜的价格买到一两个二手的,那就下手吧。
GTX 1060(6 GB 版本)
参数:
显存(VRAM):6 GB
内存带宽:216 GB/s
处理器:1280 个 CUDA 核心 @ 1708 MHz(约 2.19 亿 CUDA 核心频率)
英伟达官网价格:2000 元
相对来说比较便宜,但是 6 GB 显存对于深度学习任务可能不够用。如果你要做计算机视觉,那么这可能是最低配置。如果做 NLP 和分类数据模型,这款还可以。
GTX 1050 Ti
参数:
显存(VRAM):4 GB
内存带宽:112 GB/s
处理器:768 个 CUDA 核心 @ 1392 MHz(约 1.07 亿 CUDA 核心频率)
英伟达官网价格:1060 元
这是一款入门级 GPU。如果你不确定是否要做深度学习,那么选择这款不用花费太多钱就可以体验一下。
值得注意的问题
上代旗舰 Titan X Pascal 曾是英伟达最好的消费级 GPU 产品,而 GTX 1080 Ti 的出现淘汰了 Titan X Pascal,前者与后者有同样的参数,但 1080 Ti 便宜了 40%。
英伟达还拥有一个面向专业市场的 Tesla GPU 产品线,其中包括 K40、K80、P100 和其他型号。虽然你或许很少能够接触到,但你可能已经通过 Amazon Web Services、谷歌云平台或其他云供应商在使用这些 GPU 了。
我在之前的文章中对 GTX 1080 Ti 和 K40 进行了一些基准测试。1080 的速度是 K40 的 5 倍,是 K80 的 2.5 倍。K40 有 12 GB 显存,K80 有 24 GB 的显存。
理论上,P100 和 GTX 1080 Ti 应该性能差不多。但是,之前的对比(https://www.reddit.com/r/NiceHash/comments/77uxe0/gtx_1080ti_vs_nvidia_tesla_p100_xpost_from/)发现 P100 在每个基准中都比较落后。
K40 售价超过了 13,000元,K80 售价超过 20,000 元,P100 售价约 30,000 元。它们的市场正被英伟达自家的桌面级 GPU 无情吞噬。显然,按照现在的情况,我不推荐你去购买它们。
一句话推荐
如果你不设定自己的预算,装配电脑就成了一件困难的事。在这里,我将给出不同预算区间下 GPU 的最佳选择。
4600-6000 元区间:首推 GTX 1080 Ti。如果你需要双显卡 SLI,请购买两块 GTX 1070(可能不太好找)或两块 GTX 1070 Ti。Kaggle 排行榜,我来了!
2600-4600 元区间:可选 GTX 1080 或 GTX 1070 Ti。如果你真的需要 SLI 的话或许两块 GTX 1060 也是可以的,但请注意它们的 6GB 内存可能会不够用。
2000-2600 元区间:GTX 1060 可以让你入门深度学习,如果你可以找到成色不错的 GTX 1070 那就更好了。
2000 元以下:在这个区间内,GTX 1050 Ti 是最佳选择,但如果你真的想做深度学习,请加钱上 GTX 1060。
教你如何挑选深度学习GPU【转】的更多相关文章
- 如何挑选深度学习 GPU?
如何挑选深度学习 GPU? 深度学习是一个对计算有着大量需求的领域,从一定程度上来说,GPU的选择将从根本上决定深度学习的体验.因此,选择购买合适的GPU是一项非常重要的决策.那么2020年,如何选择 ...
- 深度学习 GPU环境 Ubuntu 16.04 + Nvidia GTX 1080 + Python 3.6 + CUDA 9.0 + cuDNN 7.1 + TensorFlow 1.6 环境配置
本节详细说明一下深度学习环境配置,Ubuntu 16.04 + Nvidia GTX 1080 + Python 3.6 + CUDA 9.0 + cuDNN 7.1 + TensorFlow 1.6 ...
- 深度学习GPU集群管理软件 OpenPAI 简介
OpenPAI:大规模人工智能集群管理平台 2018年5月22日,在微软举办的“新一代人工智能开放科研教育平台暨中国高校人工智能科研教育高峰论坛”上,微软亚洲研究院宣布,携手北京大学.中国科学技术大学 ...
- 使用colab运行深度学习gpu应用(Mask R-CNN)实践
1,目的 Google Colaboratory(https://colab.research.google.com)是谷歌开放的一款研究工具,主要用于机器学习的开发和研究.这款工具现在可以免费使用, ...
- 免费深度学习GPU,Google Yes!
深度学习越加火热,但是,很多实验室并没有配套的硬件设备,让贫穷的学生党头大 经过网上大量的搜罗,我整理了适合学生党的深度学习解决方案.利用Colab + Kaggle两大免费的GPU环境,让深度学习变 ...
- GitHub 上 57 款最流行的开源深度学习项目
转载:https://www.oschina.net/news/79500/57-most-popular-deep-learning-project-at-github GitHub 上 57 款最 ...
- 学习笔记︱Nvidia DIGITS网页版深度学习框架——深度学习版SPSS
DIGITS: Deep Learning GPU Training System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统.目的在于整合现有的Deep Learnin ...
- Github上Stars最多的53个深度学习项目,TensorFlow遥遥领先
原文:https://github.com/aymericdamien/TopDeepLearning 项目名称 Stars 项目介绍 TensorFlow 29622 使用数据流图计算可扩展机器学习 ...
- GitHub 上 57 款最流行的开源深度学习项目【转】
GitHub 上 57 款最流行的开源深度学习项目[转] 2017-02-19 20:09 334人阅读 评论(0) 收藏 举报 分类: deeplearning(28) from: https:// ...
随机推荐
- hibernate的日期映射
2. 映射 Java 的时间, 日期类型 1). 两个基础知识: I. 在 Java 中, 代表时间和日期的类型包括: java.util.Date 和 java.util.Calendar. 此外, ...
- Python全栈day10(运算符)
一,运算符 + - * . ** % // 二,in 和not in 一个字符串包含多个字符可以通过in判断字符是否属于改字符串 >>> name = "zhangsan& ...
- Code Forces 21 A(模拟)
A. Jabber ID time limit per test 0.5 second memory limit per test 256 megabytes input standard input ...
- googlr 黄金法则 监控
googlr 黄金法则 监控
- Storm-源码分析- Messaging (backtype.storm.messaging)
先定义两个接口和一个类 TaskMessage类本身比较好理解, 抽象storm的message格式 对于IContext, 注释也说了, 定义messaging plugin, 通过什么渠道去发送m ...
- Linux常用软件(以及特殊命令)清单(ubuntu)
LibreOffice 解压缩命令 unar .tar 创建新文档命令:touch.vi/vim 浏览器:google chrome.firefox
- git学习——<二>git配置文件
一.git所有配置文件 <一>./etc/gitconfig全局配置文件 修改该配置文件,会对所有用户有影响. 使用git config --system来配置该文件 <二>. ...
- android shareSDK实现第三方分享
一. http://www.mob.com/ 在mob官网注册账号,获取ShareSDK的appkey,下载shareSDK并解压. 二.进入ShareSDK解压目录,打开“Share SDK f ...
- apache-storm-1.0.3安装部署
CentOS7-1 CentOS7-2 CentOS7-3 CentOS7-4 nimbus supervisor supervisor supervisor core(UI) 1.首 ...
- JVM之基本概念
1.类加载子系统:负责从文件系统或者网络中加载Class信息,加载的信息存放在一块称之为方法区的内存空间. 2.方法区:就是存放类信息.常量信息.常量池信息.包括字符串字面量和数字常量等.方法区是辅助 ...