Postgres数据库在Linux中优化
I/O 优化
1 打开 noatime nodirtime,async
方法: 修改 /etc/fstab
stat 命令查看
2 调整预读
方法: 查看 sudo blockdev --getra /dev/sda
设置 sudo blockdev --setra 4096 /dev/sdf (4096个扇区,即2M)
3 调整虚拟内存参数
A 方法: 查看 cat /proc/sys/vm/wappiness
设置 vi /etc/sysctl.conf 添加
vm.swappiness=0 虚拟内存参数 范围 0-100 越大越倾向使用swap空间 ,为了使数据库性能尽量平稳此参数设置为0
vm.overcommit_memory=2 (0 启发式策略、1 调用总成功、2 禁用overcommit,完全避免OOM killer)
生效 sysctl -p
swapoff -a
B 方法:
查看命令 vmstat -an 1 或 cat /proc/meminfo
4 写缓存优化
vm.dirty_background_radio
vm.dirty_radio
vm.dirty_writeback_centisecs
物理内存大将至调低些
5 调整I/O 调度
deadline 平衡所有请求,避免某个请求饿死,让响应时间最优化。
A echo deadline > /sys/block/sddd/queue/scheduler
B 修改 grub.conf
elevator=deadline
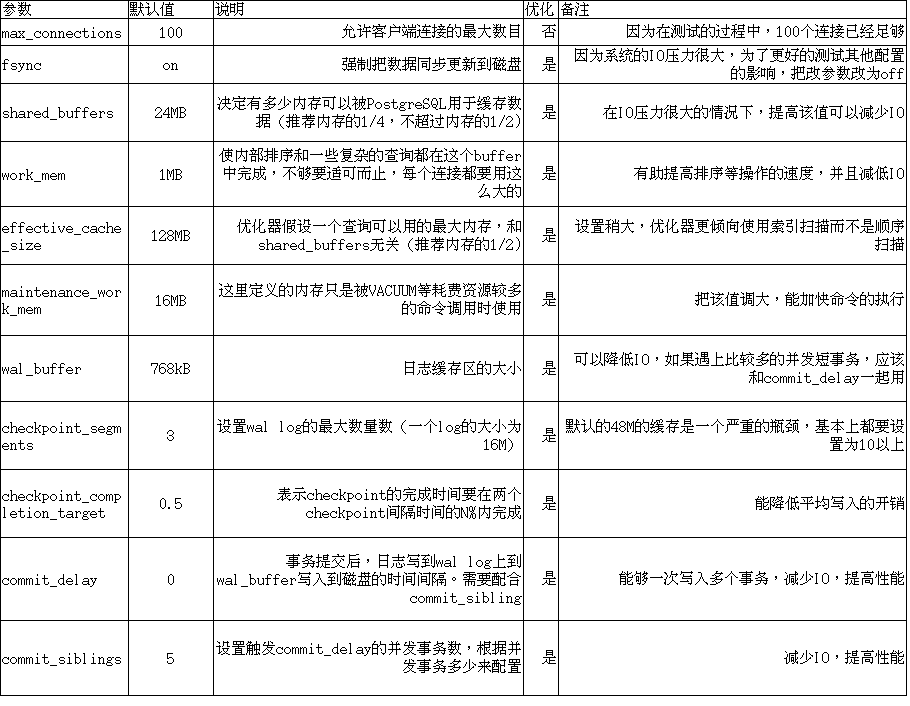
内存优化
share_buffers 共享缓存区 推荐值内存的1/4 不要超过 1/2.
work_mem 每个进程单独分配的内存
maintence_work_mem 每个进程单独分配的内存,用于维护操作。
双缓存的优化
说明:数据库中对数据块设计了专门的共享内存缓存区,数据库的数据文件都在文件系统中,操作系统的文件系统也有缓存。
数据库配置 huge_pages = try
sysctl vm.nr_hugepages=10240
Postgres数据库在Linux中优化的更多相关文章
- Postgres数据库在Linux中的I/O优化
I/O 优化1 打开 noatime方法: 修改 /etc/fstab2 调整预读方法: 查看 sudo blockdev --getra /dev/sda 设置 sudo blockdev --se ...
- 数据库与linux中quota的作用
linux命令,quota 命令显示磁盘使用情况和限额.缺省情况下,或者带 -u 标志,只显示用户限额.quota 命令报告 /etc/filesystems 文件中列出的所有文件系统的限额.如果 q ...
- 如丝般顺滑地从Windows迁移SQLServer数据库到Linux
老鸟看过菜鸟的上一篇<MSSQL On Linux备份与还原>文章后,很满意,但是还是忍不住发问:"这篇文章讲的是MSSQL在Linux系统上的备份与还原,如果我之前是Windo ...
- postgres数据库中的数据转换
postgres8.3以后,字段数据之间的默认转换取消了.如果需要进行数据变换的话,在postgres数据库中,我们可以用"::"来进行字段数据的类型转换.实际上"::& ...
- linux中安装oracle数据库
1. 执行 ./runInstaller 提示 /tmp 的空间过小执行 mount -o remount,size=1G,noatime /tmp重新设置 /tmp 的大小 2. 安装完成数据库之后 ...
- 通过window(Navicat)访问linux中的mysql数据库
Centos安装Mysql数据库 查看我们的操作系统上是否已经安装了mysql数据库 [root@centos~]# rpm -qa | grep mysql // 这个命令就会查看该操作系统上是否已 ...
- 在Windows10系统中配置和运行MongoDB数据库,linux开启mongdb
参考链接:http://jingyan.baidu.com/article/11c17a2c03081ef446e39d02.html linux中开启mongodb服务: 1. 进入到/data/ ...
- 在ef core中使用postgres数据库的全文检索功能实战
起源 之前做的很多项目都使用solr/elasticsearch作为全文检索引擎,它们功能全面而强大,但是对于较小的项目而言,构建和维护成本显然过高,尤其是从关系数据库/文档数据库到全文检索引擎的数据 ...
- 在ef core中使用postgres数据库的全文检索功能实战之中文支持
前言 有关通用的postgres数据库全文检索在ef core中的使用方法,参见我的上一篇文章. 本文实践了zhparser中文插件进行全文检索. 准备工作 安装插件,最方便的方法是直接使用安装好插件 ...
随机推荐
- OrderedDict 有序字典以及读取json串时如何保持原有顺序
1. OrderedDict 有序字典 OrderedDict是dict的子类,它记住了内容添加的顺序.比较时,OrderedDict要内容和顺序完全相同才会视为相等 import collectio ...
- UNITY Destroy()和DestroyImadiate()都不会立即释放对象内存
如题,destroyimadiate是立即将物体从场景hierachy中移除,并标记为 "null",注意 是带引号的null.这是UNITY内部的一个处理技巧.关于这个技巧有很争 ...
- Cookie&Session会话跟踪技术
今日内容学习目标 可以响应给浏览器Cookie信息[response.addCookie()] 可以接受浏览器Cookie信息[request.getCookies()] [创建cookie,设置pa ...
- Junit Test 的时候出错java.lang.IllegalStateException: Failed to load ApplicationContext
问题原因 JDK1.8 spring版本3.2.0RELEASE JDK和spring版本不兼容 解决方法 1.降低JDK版本到1.7 2.将spring的版本升级到4.0.0RELEASE或者 ...
- 自定义tag标签的方法
JSP1.0中可以通过继承TagSupport或者BodyTagSupport来实现自定义的tag处理方法. JSP2.0中也支持另外一种更为简单的自定tag的方法,那就是直接讲JSP代码保存成*.t ...
- (转)C#命名规范
C#命名规范 数据类型 数据类型简写 标准命名举例 Array arr arrShoppingList Boolean bln blnIsPostB ...
- springmvc基本知识点
springmvc高级知识:
- guestfs-python 手册
Help on module guestfs: NAME guestfs - Python bindings for libguestfs FILE /usr/lib64/python2.7/site ...
- Linux实战教学笔记40: Mha-Atlas-MySQL高可用方案实践(二)
六,配置VIP漂移 主机名 IP地址(NAT) 漂移VIP 描述 mysql-db01 eth0:192.168.0.51 VIP:192.168.0.60 系统:CentOS6.5(6.x都可以) ...
- python's metaclass
[python's metaclass] 和objc中类似,metaclass用于创建一个类对象,但与objc不同的是,objc中每个类对象有各自不同的metaclass,而python中的metac ...