Python- discover()方法与执行顺序补充
可以根据不同的功能创建不同的测试文件,甚至是不同的测试目录,测试文件中还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,让整体结构更加清晰
但通过addTest()添加、删除测试用例就变得非常麻烦
TestLoader 类中提供的discover()方法可以自动识别测试用例
discover(start_dir,pattern='test*.py',top_level_dir= None)
找到指定目录下所有测试模块,并可递归查到子目录下的测试模块,只有匹配到文件名时才加载
start_dir:要测试的模块名或测试用例目录
pattern='test*.py':表示用例文件名的匹配原则。此处匹配以“test”开头的.py 类型的文件,* 表示任意多个字符
top_level_dir= None 测试模块的顶层目录,如果没有顶层目录,默认为None
实例1:
import unittest
test_dir = './'
#定义测试目录为当前目录
discover = unittest.defaultTestLoader.discover(test_dir,pattern='test*.py') if __name__ == '__main__':
runner = unittest.TextTestRunner()
runner.run(discover)
discover()方法会自动根据测试目录test_dir 匹配查找测试用例文件,并将查找到的测试用例组装到测试套件中,因此,可以直接通过
run()方法执行discover,大大简化了测试用例的查找与执行 实例2:
suite = unittest.TestSuite()
all_cases = unittest.defaultTestLoader.discover(PY_PATH,'Test*.py')
#discover()方法会自动根据测试目录匹配查找测试用例文件(Test*.py),并将查找到的测试用例组装到测试套件中
[suite.addTests(case) for case in all_cases]
report_html = BeautifulReport.BeautifulReport(suite)
二、用例执行的顺序
unittest 框架默认根据ASCII码的顺序加载测试用例,数字与字母的顺序为:0~9,A~Z,a~z
如果要让某个测试用例先执行,不能使用默认的main()方法,需要通过TestSuite类的addTest()方法按照一定的顺序来加载
discover(start_dir,pattern='test*.py',top_level_dir=None)
找到指定目录下所有测试模块,并可递归查到子目录下的测试木块,只有匹配到的文件名才会被加载。如果启动的不是顶层目录,那么顶层目录必然单独指定。
- start_dir:要测试的模块名或测试用例的目录。
- pattent=‘test*.py’:表示用例文件名的匹配原则。此处匹配文件名一test开头的所有.py类型文件,*表示任意多个字符。
- top_level_dir=None :测试模块的顶层目录,如果没有顶层目录,默认为None。

import unittest
import json
import requests
from HTMLTestRunner import HTMLTestRunner
import time #定义测试用例的目录为当前目录
test_dir = './'
discover = unittest.defaultTestLoader.discover(test_dir,pattern = 'test*.py') if __name__=="__main__": #按照一定的格式获取当前的时间
now = time.strftime("%Y-%m-%d %H-%M-%S") #定义报告存放路径
filename = './' + now + 'test_result.html' fp = open(filename,"wb")
#定义测试报告
runner = HTMLTestRunner(stream = fp,
title = "xxx接口测试报告",
description = "测试用例执行情况:")
#运行测试
runner.run(discover)
fp.close() #关闭报告文件
下面直接举例说明discover用法:
一、 准备工作
目录结构:
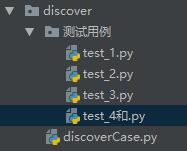
DiscoverCase.py 文件代码:
import unittest
import os def discover_case(case_dir):
# 待执行用例的目录
testcase = unittest.TestSuite()
discover = unittest.defaultTestLoader.discover(case_dir,pattern="*.py",top_level_dir=None)
# discover方法筛选出来的用例,循环添加到测试套件中
print(discover)
for test_suite in discover:
for test_case in test_suite:
print(test_case)
# 添加用例到testcase
#testcase.addTests(test_case)
testcase.addTests(test_case) return(testcase)
path = os.path.join(os.getcwd(), "测试用例")
case = discover_case(case_dir=path)
print(case)
Test1代码(test2~4代码基本相同):
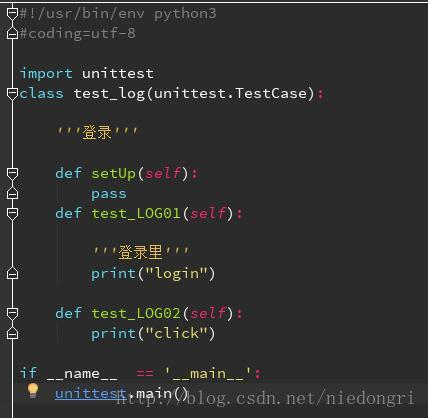
注意:每个testcase里面的执行用例(即以test开头的函数)必现大于或等于两个,不然会报错。
二、写好这些后我们就直接跑程序看结果
运行后用例的文件名、类名、函数名都会遍历出来

注意:如果用例名称全为中文是不可以加载的到的,必须以字母开始,比如“i登录.py”
Python- discover()方法与执行顺序补充的更多相关文章
- Python unittest discover()方法与执行顺序补充
一.discover更多测试用例 可以根据不同的功能创建不同的测试文件,甚至是不同的测试目录,测试文件中还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,让整体结构更加清晰 但通过addTe ...
- Python----unittest discover()方法与执行顺序
一.Unittest discover()可以根据不同的功能创建不同的测试文件,甚至是不同的测试目录,测试文件中还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,让整体结构更加清晰一般是通过 ...
- python:unittest之discover()方法批量执行用例
自动化测试过程中,自动化覆盖的功能点和对应测试用例之间的关系基本都是1 VS N,如果每次将测试用例一个个单独执行,不仅效率很低, 无法快速反馈测试结果,而且维护起来很麻烦.在python的单元测试框 ...
- 在Spring Bean的生命周期中各方法的执行顺序
Spring 容器中的 Bean 是有生命周期的,Spring 允许在 Bean 在初始化完成后以及 Bean 销毁前执行特定的操作,常用的设定方式有以下十种: 通过实现 InitializingBe ...
- C#类中方法的执行顺序
有些中级开发小伙伴还是搞不太明白在继承父类以及不同场景实例化的情况下,父类和子类的各种方法的执行顺序到底是什么,下面通过场景的举例来重新认识下方法的执行顺序: (下面内容涉及到了C#中的继承,构造函数 ...
- unittest的discover方法批量执行02
前言 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了. 加载用例后,用unittest里面的Text ...
- python中try except执行顺序
python中try except finally的执行顺序 先执行try中语句 如果try中抛出异常, 执行异常中语句. 如果try 或 except 中没有return语句,执行完try 或者 e ...
- jquery和js的几种页面加载函数的方法以及执行顺序
参考博客:http://www.cnblogs.com/itslives-com/p/4646790.html https://www.cnblogs.com/james641/p/783837 ...
- odoo开发笔记 -- 多个子类继承同一个父类方法的执行顺序
场景描述: odoo模块化开发的架构理念,科学&高效, 可以让很多业务场景,尽可能松耦合:让开发人员的主要精力,关注在当前的业务逻辑: 所谓「前人栽树,后人乘凉」,模块整体好比一棵大树, 开发 ...
随机推荐
- ios开发之 -- Swap file ".Podfile.swp" already exists!
- Proxool线程池的简单实现demo
使用的jar包:ojdbc14.jar proxool-0.9.0.jar commons-logging-1.1.3.jar 代码分为两部分: ProxoolTest.java和proxo ...
- poj_1125 Floyd最短路
题目大意 N个股票经纪人,每个股票经纪人都会将得到的消息传播给另外一些股票经纪人,传播的速度均不固定,且从A传到B的速度和B传到A的速度不一定相等.给定一个消息,并不一定能够传遍所有的股票经纪人,因为 ...
- JZOJ.5305【NOIP2017模拟8.18】C
Description
- 通过AnimationSet 同步或一部播放多个动画 Android 属性动画(Property Animation) 完全解析 (下)
AnimationSet提供了一个把多个动画组合成一个组合的机制,并可设置组中动画的时序关系,如同时播放,顺序播放等. 以下例子同时应用5个动画: 播放anim1: 同时播放anim2,anim3,a ...
- java中Logger.getLogger(Test.class),即log4日志的使用
log4的使用方法: log4是具有日志记录功能,主要通过一个配置文件来对程序进行监测有两种配置方式:一种程序配置,一种文件配置有三个主要单元要了解,Logger,appender,layout. l ...
- Vscode 调试 C 语言时数组值无法显示的问题
使用 Vscode 的 Gdb 扩展调试 C 语言时,发现数组变量在 变量列表里面中显示为指针,且只显示为其第一个元素的值,无法看到所有元素的值. 如图所示: 解决: 假设有一个元素个数为10的数组v ...
- msvcp71.dll 怎么丢失的?如何修复
解决方法:另一台电脑上下载这个dll,再用优盘拷回来,复制到c:\windows\system32\下. 个人遇到的情况:迅雷下载东西时,或者在操作迅雷时出现的. win7 64位下 点击下载
- Python全栈day9(Python基础)
Python基础 一,Windows安装Python3.5 下载地址:https://www.python.org/ftp/python/3.5.2/python-3.5.2rc1-amd64.exe ...
- new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象的实例。
new运算符 - JavaScript | MDN https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operator ...