初识Hadoop一,配置及启动服务
一、Hadoop简介:
Hadoop是由Apache基金会所开发的分布式系统基础架构,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS;Hadoop框架最核心设计就是HDFS和MapReduce,HDFS为海量数据提供了存储,MapReduce为海量数据提供了计算。
Hadoop要解决的问题:海量数据的存储(HDFS)、海量数据的分析(MapReduce)和资源管理调度(YARN)
Hadoop主要作用于分布式
二、Hadoop实现机制
1、Hadoop是把一个文件切割成多个块(block),分别存储到不同服务器上,而且其中某些服务器又存有这个文件的多个块,如下图把文件A分成4块(A1\A2\A3\A4)存放在4个服务器上;这样不仅解决了并发请求一个文件时造成的阻塞,增大吞吐量,还做了副本备份

2、Hadoop分布式部署服务器,那就分主服务器和辅服务器。主服务器也就是NameNode,存储文件分块的相关信息,如哪个块在哪个服务器哪个路径下,而真正存储文件的是辅服务器,即DataNode。客户端请求文件时无需关心如何请求块,只需要知道HDFS为文件虚拟的一个文件路径即可,也就是直接请求NameNode。
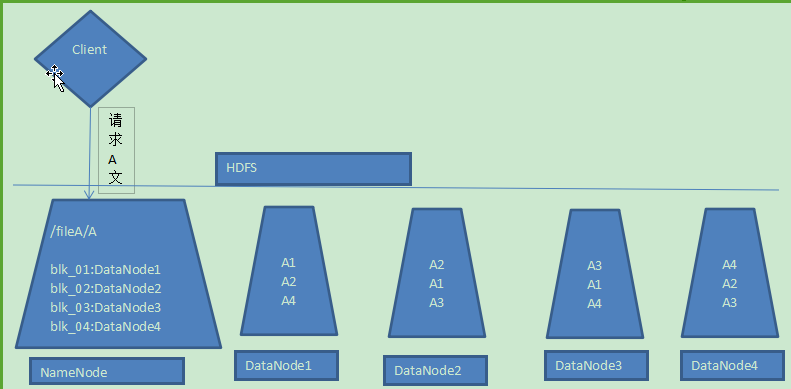
3、Hadoop只有一个NameNode,可以有多个DataNode,当DataNode不够用时还可以添加
三、Hadoop安装、配置及启动(CentOS7系统)
1、官网下载Hadoop hadoop-2.7.3.tar.gz
2、需要的软件环境JDK、SSH、rsync;JDK安装和部署参照本博文linux学习之系统管理、网络配置、软件安装第九步;ssh、rsync安装直接用yum install安装,一般这两个系统自带
2、在/home下新建文件夹hadoop,然后通过FlashFXP工具将下载好的hadoop压缩包上传至此文件夹下,使用tar命令解压
3、在解压后的文件下修改配置
(1)、设置JAVA_HOME环境变量(我的JDK安装目录为/home/jdk/jdk1.8.0_73/)
vi命令编辑etc/hadoop/hadoop-env.sh,找到相应位置修改如下:
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/home/jdk/jdk1.8.0_73
(2)、编辑文件etc/hadoop/core-site.xml文件,指定默认文件系统和工作空间(现在还路径下还没有tmp文件夹,执行完hdfs格式化后便可看到相关文件)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.3/tmp/</value>
</property>
</configuration>
(3)、编辑文件etc/hadoop/hdfs-site.xml文件,设置文件副本数,也就是文件分割成块后,要复制块个数(由于此处就本机一个节点,伪分布式,所以就配置为1,文件本身,不需要副本)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(4)、编辑文件etc/hadoop/mapred-site.xml文件,此文件其实不存在,二存在mapred-site.xml.template,所以执行命令mv mapred-site.xml.template mapred-site.xml修改此文件名,指定资源调度框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)、编辑文件etc/hadoop/yarn-site.xml文件,yarn也是分布式管理的,所以配置一个主服务器;然后还要配置中间数据调度的机制
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4、配置完成后,格式化hdfs系统
hadoop命令一般在bin文件夹下,所以要执行相关命令要在bin目录下进行操作,为了以后方便,所以要先把hadoop的bin目录配置到环境变量中,还有些命令在sbin目录中,所以也要配置到环境变量
vi /etc/profile环境变量部分代码如下
export JAVA_HOME=/home/jdk/jdk1.8.0_73
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存后记得用命令source /etc/profile配置立即生效
(执行前可以看下hadoop安装目录下不存在tmp文件夹)然后执行hadoop namenode -format命令,会发现以前hadoop安装路径下不存在tmp文件夹,现在已经有了
5、启动HDFS(sbin下有start-dfs.sh)
HDFS是分布式系统,所以启动HDFS时,会启动配置的各个服务器节点,包括本机,在启动过程中是通过ssh远程操作的,所以在不做特殊配置下,每次启动到节点(包括本机)相关操作时,都要输入密码,如果想避免每次都输入密码,可执行下面命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
执行start-dfs.sh启动HDFS(由于配置了环境变量,所以可以直接执行,不用切换到sbin目录下) 启动完后jps命令可以查看正在启动的java服务
[root@localhost bin]# jps
28800 SecondaryNameNode
28619 DataNode
28524 NameNode
29068 Jps
[root@localhost bin]#
netstat -nltp命令查看所监听的端口
[root@localhost bin]# netstat -nltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 28800/java
tcp 0 0 192.168.36.133:1521 0.0.0.0:* LISTEN 2485/tnslsnr
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 2397/dnsmasq
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 28524/java
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1080/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 1084/cupsd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 2263/master
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 28619/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 28619/java
tcp 0 0 127.0.0.1:38242 0.0.0.0:* LISTEN 28619/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 28619/java
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 28524/java
tcp6 0 0 :::22 :::* LISTEN 1080/sshd
tcp6 0 0 ::1:631 :::* LISTEN 1084/cupsd
tcp6 0 0 :::23 :::* LISTEN 1087/xinetd
tcp6 0 0 ::1:25 :::* LISTEN 2263/master
tcp6 0 0 :::36794 :::* LISTEN 2558/ora_d000_orcl
[root@localhost bin]#
NameNode和DataNode是通过9000端口通信的
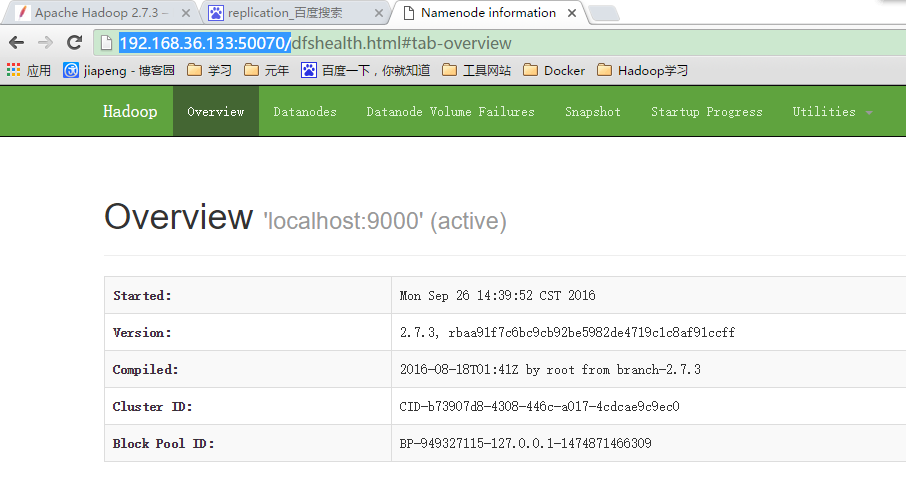
50070端口是提供的一个Web页面,我的系统ip是192.168.36.133,访问网址http://192.168.36.133:50070/可查看效果
6、启动yarn(yarn也是集群的)
执行start-yarn.sh命令(在sbin文件夹下),如果前面没有配置ssh免登录,也是要输入登录密码的。执行jps命令查看启动的Java服务,ResourceManager已启动
[root@localhost home]# jps
4080 Jps
3121 DataNode
3320 SecondaryNameNode
3672 ResourceManager
3768 NodeManager
3021 NameNode
[root@localhost home]#
到此已经配置启动完了,下一节开始使用
初识Hadoop一,配置及启动服务的更多相关文章
- MySQL——安装、配置、启动服务、
1.环境变量配置 将启动连接,加入环境变量中. mysqld :启动服务端 msysql -u 用户名 -p 密码 : 启动客户端 2.windows服务:一直在运行中 E:\wupeiqi\mys ...
- Hortonworks HDP Sandbox定制(配置)开机启动服务(组件)
定制Hortonworks HDP开机启动服务能够这样做:本文原文出处: http://blog.csdn.net/bluishglc/article/details/42109253 严禁不论什么形 ...
- Linux 配置脚本 启动服务
之前在mac安装了php和nginx每次都用一堆命令重启 今天没事情干,心血来潮,自己研究写了一段shell脚本来重启 首先vim /usr/sbin/pn 代码如下 #! /bin/bash php ...
- Dubbo 通过Spring 配置具体启动服务
dubbo 服务的启动加载过程,请先看 : http://www.cnblogs.com/ghj1976/p/5316126.html 以 dubbo-demo-provider-2.5.4-SNA ...
- 在Windows子系统(WSL)中配置开机启动服务
在WSL中跑了一些测试服务 比如 mysql nginx等,但关机后每次都要手动开启甚是吃力,本想着用rc.local来编辑开机启动 ,无奈不支持啊!先看看非WSL环境中是怎么实现的. 在 Ubunt ...
- hadoop搭建好,启动服务后,无法从web界面访问50070
在hadoop完全分布式搭建好以后,从主节点启动正常,使用jps查看启动的进程,正常,在几个从节点上使用jps查看,显示正常,但从web上输入下面网址: http://主节点IP:50070 无法正常 ...
- Ubuntu安装sysv-rc-conf配置开机启动服务
ubuntu下chkconfig的替代方案: 第一步:在终端键入sudo apt-get install sysv-rc-conf安装sysv-rc-conf服务. 第二步:检查设置系统开机自启动服务 ...
- centos6 centos7 配置开机启动服务
centos 6 :使用chkconfig命令即可. 我们以apache服务为例: #chkconfig --add apache 添加nginx服务 #chkconfig apache on 开机自 ...
- 安装、配置、启动FTP、SSH或NFS服务
(1)准备使用软件维护工具apt-get. Ubuntu7.10中没有安装FTP.SSH.NFS服务器软件,它提供了一个很方便的安装.升级.维护软件的工具apt-get.apt-get从光盘.网络上下 ...
随机推荐
- android 资讯阅读器
最近找申请到了一个不错的接口 , 非常适合拿来写一个资讯类的app. 现在着手写,随写随更.也算是抛砖引玉.烂尾请勿喷.╭(╯^╰)╮ android 资讯阅读器 第一阶段目标样式(滑动切换标签 , ...
- Ceph性能优化总结(v0.94)
优化方法论 做任何事情还是要有个方法论的,“授人以鱼不如授人以渔”的道理吧,方法通了,所有的问题就有了解决的途径.通过对公开资料的分析进行总结,对分布式存储系统的优化离不开以下几点: 1. 硬件层面 ...
- [转] 使用Spring MVC构建REST风格WEB应用
原文地址:http://fancy888.iteye.com/blog/1629120 对于运行在网络上的MIS系统而言,处理数据的是整个系统的主要任务,翻开程序我们可以看到,80%以上的代码都在处理 ...
- Servlet作业2-将表单提交的商品信息输出到页面中
1,表单页面 shangpin.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8&qu ...
- httpclient提示Cookie rejected: violates RFC 2109: domain must start with a dot
使用httpclient时发生如下告警信息: WARN - HttpMethodBase.processResponseHeaders(1505) | Cookie rejected: "$ ...
- linux下mysql基础从安装到基本使用
在LINUX下安装MYSQL #需要的安装包(按照先后顺序) libdbi-devel--2.1 libdbi--2.1 libdbi-drivers- perl-DBI-.el5 perl-DBD- ...
- Asp.net Mvc 使用EF6 code first 方式连接MySQL总结
最近由于服务器变更为Linux系统.MsSql for Linux什么时候出来到生产环境使用还是要很长时间的.于是考虑使用Mysql数据库,ORM使用EF.于是先踩下坑顺便记录一下,有需要的tx可以参 ...
- 3.Android 优化布局(解决TextView布局)
转载:http://www.jianshu.com/p/d3027acf475a 今天分享一个Layout布局中的一个小技巧,希望看过之后你也可以写出性能更好的布局,我个人的目的是用最少的view写出 ...
- Leetcode 74 and 240. Search a 2D matrix I and II
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the follo ...
- 更改codeblocks的配色方案
codeblocks默认只有一种配色方案, 不过我们可以手动添加. 在终端下输入如下命令: cd ~/.codeblocks sudo gedit default.conf 在打开的配置文件中, 找到 ...