Hive 1、什么是Hive,Hive有什么用

一、什么是Hive
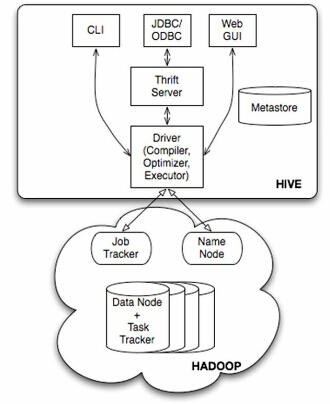
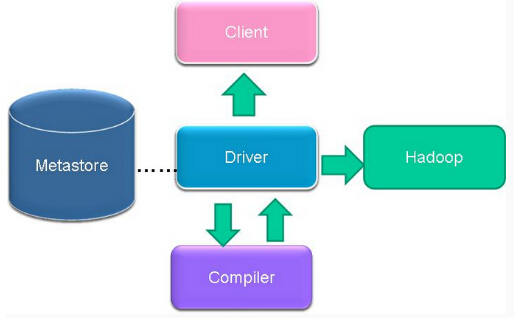
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
二、Hive的应用场景
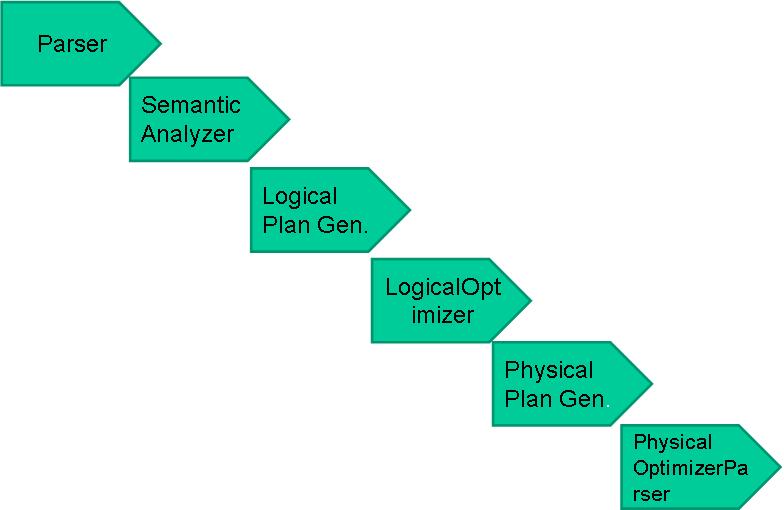
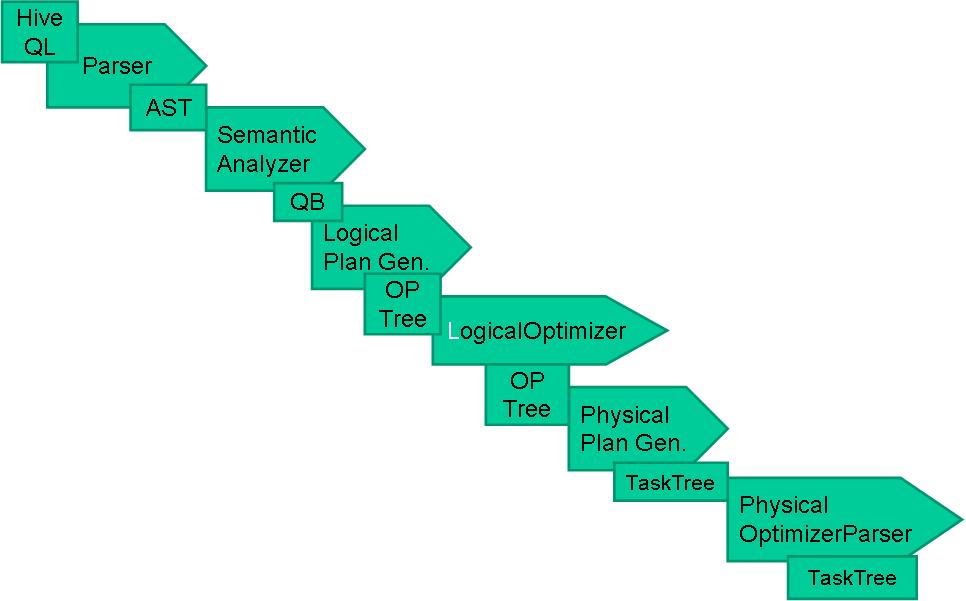
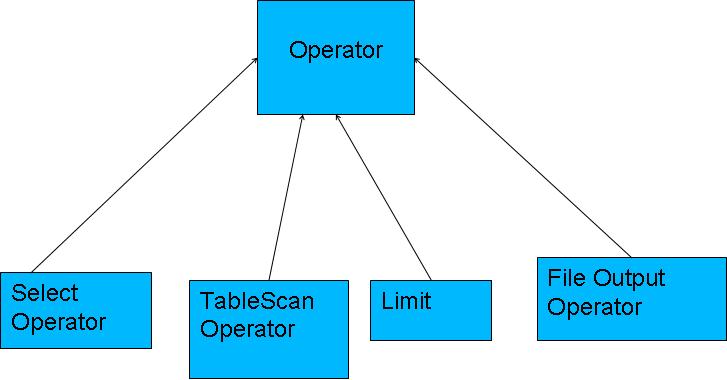
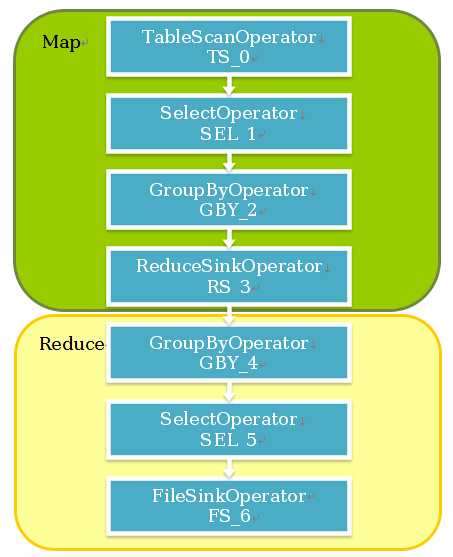
.编译器将一个Hive QL转换操作符
.操作符是Hive的最小的处理单元
.每个操作符代表HDFS的一个操作或者一道MapReduce作业


|
操作符
|
描述
|
|
TableScanOperator
|
扫描hive表数据
|
|
ReduceSinkOperator
|
创建将发送到Reducer端的<Key,Value>对
|
|
JoinOperator
|
Join两份数据
|
|
SelectOperator
|
选择输出列
|
|
FileSinkOperator
|
建立结果数据,输出至文件
|
|
FilterOperator
|
过滤输入数据
|
|
GroupByOperator
|
GroupBy语句
|
|
MapJoinOperator
|
/*+mapjoin(t) */
|
|
LimitOperator
|
Limit语句
|
|
UnionOperator
|
Union语句
|
Hive 1、什么是Hive,Hive有什么用的更多相关文章
- [Hive - LanguageManual ] ]SQL Standard Based Hive Authorization
Status of Hive Authorization before Hive 0.13 SQL Standards Based Hive Authorization (New in Hive 0. ...
- 深入浅出Hive企业级架构优化、Hive Sql优化、压缩和分布式缓存(企业Hadoop应用核心产品)
一.本课程是怎么样的一门课程(全面介绍) 1.1.课程的背景 作为企业Hadoop应用的核心产品,Hive承载着FaceBook.淘宝等大佬 95%以上的离线统计,很多企业里的离线统 ...
- Hive基础(4)---Hive的内置服务
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] 一:Hive的几种内置服务 ...
- 使用hive客户端java api读写hive集群上的信息
上文介绍了hdfs集群信息的读取方式,本文说hive 1.先解决依赖 <properties> <hive.version>1.2.1</hive.version> ...
- Hive thrift服务(将Hive作为一个服务器,其他机器可以作为客户端进行访问)
步骤一:启动为前台:bin/hiveserver2 步骤二:启动为后台:nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Hive官方使用手册——新Hive CLI(Beeline CLI)
Hive官方使用手册——新Hive CLI(Beeline CLI) https://blog.csdn.net/maizi1045/article/details/79481686
- Hive总结(八)Hive数据导出三种方式
今天我们再谈谈Hive中的三种不同的数据导出方式. 依据导出的地方不一样,将这些方式分为三种: (1).导出到本地文件系统. (2).导出到HDFS中: (3).导出到Hive的还有一个表中. 为了避 ...
- 【Hive学习之二】Hive SQL
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
随机推荐
- DedeCMS源码安装
一.源码下载地址 可以从以下网站下载DedeCMS源码进行安装,这里我下载了AB模板网的一个服装网站源码来演示DedeCMS源码的安装 http://www.adminbuy.cn/dedecms/2 ...
- 控制uibutton的title范围
moreBtn.contentEdgeInsets = UIEdgeInsetsMake(0,10, 0, 10);
- Android Paint之 setXfermode PorterDuffXfermode 讲解
setXfermodePorterDuffXfermode图层混合模式android图像混合模式AvoidXfermode 尊重原创,欢迎转载,转载请注明: FROM GA_studio htt ...
- Android Clipboard(复制/剪贴板)
Android提供的剪贴板框架,复制和粘贴不同类型的数据.数据可以是文本,图像,二进制流数据或其它复杂的数据类型. Android提供ClipboardManager.ClipData.Item和Cl ...
- [Angular 2] Refactoring mutations to enforce immutable data in Angular 2
When a Todo property updates, you still must create a new Array of Todos and assign a new reference. ...
- [ES6] Objects vs Maps
Map is really useful when you want to use object as a key to set vaule, in ES5, you cannot really us ...
- 一个小的程序--实现中英文切换(纯css)
<!doctype html><html lang="en"> <head> <meta charset="UTF-8" ...
- RAC 常用维护工具和命令(oracle 10g)
Oracle 的管理可以通过OEM或者命令行接口. Oracle Clusterware的命令集可以分为以下4种: 节点层:osnodes 网络层:oifcfg 集群层:crsctl, ocrchec ...
- 32位PLSQL_Developer连接oracle11g_64位
1. 请将你下载的instantclient-basic-win32-10.2.0.5 文件解压.然后复制到你的数据库安装的文件夹下的producti文件夹下,我的是: E:\app\Administ ...
- Servlet 技术全总结 (已完成,不定期增加内容)
Servlet是独立于平台和协议的服务器端的java应用程序,处理请求的信息并将其发送到客户端. Servlet的客户端可以提出请求并动态获得响应. Servlet动态生成web页面,担当浏览器或其他 ...