Lucene学习总结之八:Lucene的查询语法,JavaCC及QueryParser
一、Lucene的查询语法
Lucene所支持的查询语法可见http://lucene.apache.org/java/3_0_1/queryparsersyntax.html
(1) 语法关键字
+ - && || ! ( ) { } [ ] ^ " ~ * ? : /
如果所要查询的查询词中本身包含关键字,则需要用/进行转义
(2) 查询词(Term)
Lucene支持两种查询词,一种是单一查询词,如"hello",一种是词组(phrase),如"hello world"。
(3) 查询域(Field)
在查询语句中,可以指定从哪个域中寻找查询词,如果不指定,则从默认域中查找。
查询域和查询词之间用:分隔,如title:"Do it right"。
:仅对紧跟其后的查询词起作用,如果title:Do it right,则仅表示在title中查询Do,而it right要在默认域中查询。
(4) 通配符查询(Wildcard)
支持两种通配符:?表示一个字符,*表示多个字符。
通配符可以出现在查询词的中间或者末尾,如te?t,test*,te*t,但决不能出现在开始,如*test,?test。
(5) 模糊查询(Fuzzy)
模糊查询的算法是基于Levenshtein Distance,也即当两个词的差别小于某个比例的时候,就算匹配,如roam~0.8,即表示差别小于0.2,相似度大于0.8才算匹配。
(6) 临近查询(Proximity)
在词组后面跟随~10,表示词组中的多个词之间的距离之和不超过10,则满足查询。
所谓词之间的距离,即查询词组中词为满足和目标词组相同的最小移动次数。
如索引中有词组"apple boy cat"。
如果查询词为"apple boy cat"~0,则匹配。
如果查询词为"boy apple cat"~2,距离设为2方能匹配,设为1则不能匹配。
|
(0) |
boy |
apple |
cat |
|
(1) |
boy apple |
cat |
|
|
(2) |
apple |
boy |
cat |
如果查询词为"cat boy apple"~4,距离设为4方能匹配。
|
(0) |
cat |
boy |
apple |
|
(1) |
cat boy |
apple |
|
|
(2) |
boy |
cat apple |
|
|
(3) |
boy apple |
cat |
|
|
(4) |
apple |
boy |
cat |
(7) 区间查询(Range)
区间查询包含两种,一种是包含边界,用[A TO B]指定,一种是不包含边界,用{A TO B}指定。
如date:[20020101 TO 20030101],当然区间查询不仅仅用于时间,如title:{Aida TO Carmen}
(8) 增加一个查询词的权重(Boost)
可以在查询词后面加^N来设定此查询词的权重,默认是1,如果N大于1,则说明此查询词更重要,如果N小于1,则说明此查询词更不重要。
如jakarta^4 apache,"jakarta apache"^4 "Apache Lucene"
(9) 布尔操作符
布尔操作符包括连接符,如AND,OR,和修饰符,如NOT,+,-。
默认状态下,空格被认为是OR的关系,QueryParser.setDefaultOperator(Operator.AND)设置为空格为AND。
+表示一个查询语句是必须满足的(required),NOT和-表示一个查询语句是不能满足的(prohibited)。
(10) 组合
可以用括号,将查询语句进行组合,从而设定优先级。
如(jakarta OR apache) AND website
Lucene的查询语法是由QueryParser来进行解析,从而生成查询对象的。
通过编译原理我们知道,解析一个语法表达式,需要经过词法分析和语法分析的过程,也即需要词法分析器和语法分析器。
QueryParser是通过JavaCC来生成词法分析器和语法分析器的。
二、JavaCC介绍
本节例子基本出于JavaCC tutorial的文章,http://www.engr.mun.ca/~theo/JavaCC-Tutorial/
JavaCC是一个词法分析器和语法分析器的生成器。
所谓词法分析器就是将一系列字符分成一个个的Token,并标记Token的分类。
例如,对于下面的C语言程序:
|
int main() { return 0 ; } |
将被分成以下的Token:
|
“int”, “ ”, “main”, “(”, “)”, “”,“{”, “/n”, “/t”, “return” “”,“0”,“”,“;”,“/n”, “}”, “/n”, “” |
标记了Token的类型后如下:
|
KWINT, SPACE, ID, OPAR, CPAR, SPACE, OBRACE, SPACE, SPACE, KWRETURN, SPACE, OCTALCONST, SPACE, SEMICOLON, SPACE, CBRACE, SPACE, EOF |
EOF表示文件的结束。
词法分析器工作过程如图所示:

此一系列Token将被传给语法分析器(当然并不是所有的Token都会传给语法分析器,本例中SPACE就例外),从而形成一棵语法分析树来表示程序的结构。
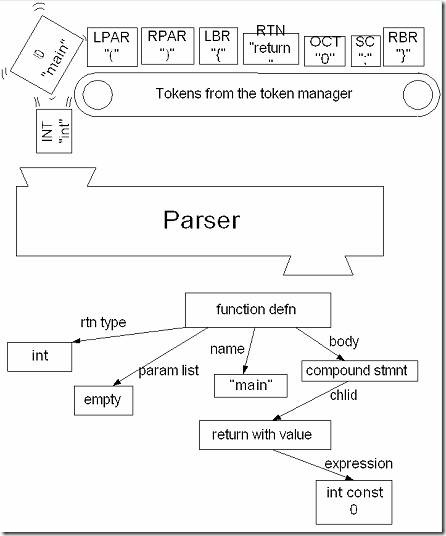
JavaCC本身既不是一个词法分析器,也不是一个语法分析器,而是根据指定的规则生成两者的生成器。
2.1、第一个实例——正整数相加
下面我们来看第一个例子,即能够解析正整数相加的表达式,例如99+42+0+15。
(1) 生成一个adder.jj文件
此文件中写入的即生成词法分析器和语法分析器的规则。
(2) 设定选项,并声明类
|
/* adder.jj Adding up numbers */ options { STATIC = false ; } PARSER_BEGIN(Adder) class Adder { static void main( String[] args ) throws ParseException, TokenMgrError { Adder parser = new Adder( System.in ) ; parser.Start() ; } } PARSER_END(Adder) |
STATIC选项默认是true,设为false,使得生成的函数不是static的。
PARSER_BEGIN和PARSER_END之间的java代码部分,此部分不需要通过JavaCC根据规则生成java代码,而是直接拷贝到生成的java代码中的。
(3) 声明一个词法分析器
|
SKIP : { " " } SKIP : { "/n" | "/r" | "/r/n" } TOKEN : { < PLUS : "+" > } TOKEN : { < NUMBER : (["0"-"9"])+ > } |
第一二行表示空格和回车换行是不会传给语法分析器的。
第三行声明了一个Token,名称为PLUS,符号为“+”。
第四行声明了一个Token,名称为NUMBER,符号位一个或多个0-9的数的组合。
如果词法分析器分析的表达式如下:
- “123 + 456/n”,则分析为NUMBER, PLUS, NUMBER, EOF
- “123 - 456/n”,则报TokenMgrError,因为“-”不是一个有效的Token.
- “123 ++ 456/n”,则分析为NUMBER, PLUS, PLUS, NUMBER, EOF,词法分析正确,后面的语法分析将会错误。
(4) 声明一个语法分析器
|
void Start() : {} { <NUMBER> ( <PLUS> <NUMBER> )* <EOF> } |
语法分析器使用BNF表达式。
上述声明将生成start函数,称为Adder类的一个成员函数
语法分析器要求输入的语句必须以NUMBER开始,以EOF结尾,中间是零到多个PLUS和NUMBER的组合。
(5) 用javacc编译adder.jj来生成语法分析器和词法分析器
最后生成的adder.jj如下:
|
options PARSER_BEGIN(Adder) public class Adder SKIP : TOKEN : /* OPERATORS */ TOKEN : void start() : |
用JavaCC编译adder.jj生成如下文件:
- Adder.java:语法分析器。其中的main函数是完全从adder.jj中拷贝的,而start函数是被javacc由adder.jj描述的规则生成的。
- AdderConstants.java:一些常量,如PLUS, NUMBER, EOF等。
- AdderTokenManager.java:词法分析器。
- ParseException.java:用于在语法分析错误的时候抛出。
- SimpleCharStream.java:用于将一系列字符串传入词法分析器。
- Token.java:代表词法分析后的一个个Token。Token对象有一个整型域kind,来表示此Token的类型(PLUS, NUMBER, EOF),有一个String类型的域image,来表示此Token的值。
- TokenMgrError.java:用于在词法分析错误的时候抛出。
下面我们对adder.jj生成的start函数进行分析:
|
final public void start() throws ParseException { //从词法分析器取得下一个Token,而且要求必须是NUMBER类型,否则抛出异常。 //此步要求表达式第一个出现的字符必须是NUMBER。 jj_consume_token(NUMBER); label_1: while (true) { //jj_ntk()是取得下一个Token的类型,如果是PLUS,则继续进行,如果是EOF则退出循环。 switch ((jj_ntk==-1)?jj_ntk():jj_ntk) { case PLUS: ; break; default: jj_la1[0] = jj_gen; break label_1; } //要求下一个PLUS字符,再下一个是一个NUMBER,如此下去。 jj_consume_token(PLUS); jj_consume_token(NUMBER); } } |
(6) 运行Adder.java
如果输入“123+456”则不报任何错误。
如果输入“123++456”则报如下异常:
|
Exception in thread "main" org.apache.javacc.ParseException: Encountered " "+" "+ "" at line 1, column 5. |
如果输入“123-456”则报如下异常:
|
Exception in thread "main" org.apache.javacc.TokenMgrError: Lexical error at line 1, column 4. Encountered: "-" (45), after : "" |
2.2、扩展语法分析器
在上面的例子中的start函数中,我们仅仅通过语法分析器来判断输入的语句是否正确。
我们可以扩展BNF表达式,加入Java代码,使得经过语法分析后,得到我们想要的结果或者对象。
我们将start函数改写为:
|
int start() throws NumberFormatException : { //start函数中有三个变量 Token t ; int i ; int value ; } { //首先要求表达式的第一个一定是一个NUMBER,并把其值付给t t= <NUMBER> //将t的值取出来,解析为整型,放入变量i中 { i = Integer.parseInt( t.image ) ; } //最后的结果value设为i { value = i ; } //紧接着应该是零个或者多个PLUS和NUMBER的组合 ( <PLUS> //每出现一个NUMBER,都将其付给t,并将t的值解析为整型,付给i t= <NUMBER> { i = Integer.parseInt( t.image ) ; } //将i加到value上 { value += i ; } )* //最后的value就是表达式的和 { return value ; } } |
生成的start函数如下:
|
final public int start() throws ParseException, NumberFormatException { Token t; int i; int value; t = jj_consume_token(NUMBER); i = Integer.parseInt(t.image); value = i; label_1: while (true) { switch ((jj_ntk == -1) ? jj_ntk() : jj_ntk) { case PLUS: ; break; default: jj_la1[0] = jj_gen; break label_1; } jj_consume_token(PLUS); t = jj_consume_token(NUMBER); i = Integer.parseInt(t.image); value += i; } { if (true) return value; } throw new Error("Missing return statement in function"); } |
从上面的例子,我们发现,把一个NUMBER取出,并解析为整型这一步是可以共用的,所以可以抽象为一个函数:
|
int start() throws NumberFormatException : { int i; int value ; } { value = getNextNumberValue() ( <PLUS> i = getNextNumberValue() { value += i ; } )* { return value ; } } int getNextNumberValue() throws NumberFormatException : { Token t ; } { t=<NUMBER> { return Integer.parseInt( t.image ) ; } } |
生成的函数如下:
|
final public int start() throws ParseException, NumberFormatException { int i; int value; value = getNextNumberValue(); label_1: while (true) { switch ((jj_ntk == -1) ? jj_ntk() : jj_ntk) { case PLUS: ; break; default: jj_la1[0] = jj_gen; break label_1; } jj_consume_token(PLUS); i = getNextNumberValue(); value += i; } { if (true) return value; } throw new Error("Missing return statement in function"); } final public int getNextNumberValue() throws ParseException, NumberFormatException { Token t; t = jj_consume_token(NUMBER); { if (true) return Integer.parseInt(t.image); } throw new Error("Missing return statement in function"); } |
2.3、第二个实例:计算器
(1) 生成一个calculator.jj文件
用于写入生成计算器词法分析器和语法分析器的规则。
(2) 设定选项,并声明类
|
options { STATIC = false ; } PARSER_BEGIN(Calculator) import java.io.PrintStream ; class Calculator { static void main( String[] args ) throws ParseException, TokenMgrError, NumberFormatException { Calculator parser = new Calculator( System.in ) ; parser.Start( System.out ) ; } double previousValue = 0.0 ; } PARSER_END(Calculator) |
previousValue用来记录上一次计算的结果。
(3) 声明一个词法分析器
|
SKIP : { " " } TOKEN : { < EOL:"/n" | "/r" | "/r/n" > } TOKEN : { < PLUS : "+" > } |
我们想要支持小数,则有四种情况:没有小数,小数点在中间,小数点在前面,小数点在后面。则语法规则如下:
|
TOKEN { < NUMBER : (["0"-"9"])+ | (["0"-"9"])+ "." (["0"-"9"])+ | (["0"-"9"])+ "." | "." (["0"-"9"])+ > } |
由于同一个表达式["0"-"9"]使用了多次,因而我们可以定义变量,如下:
|
TOKEN : { < NUMBER : <DIGITS> | <DIGITS> "." <DIGITS> | <DIGITS> "." | "." <DIGITS>> } TOKEN : { < #DIGITS : (["0"-"9"])+ > } |
(4) 声明一个语法分析器
我们想做的计算器包含多行,每行都是一个四则运算表达式,语法规则如下:
|
Start -> (Expression EOL)* EOF |
|
void Start(PrintStream printStream) throws NumberFormatException : {} { ( previousValue = Expression() <EOL> { printStream.println( previousValue ) ; } )* <EOF> } |
每一行的四则运算表达式如果只包含加法,则语法规则如下:
|
Expression -> Primary (PLUS Primary)* |
|
double Expression() throws NumberFormatException : { double i ; double value ; } { value = Primary() ( <PLUS> i= Primary() { value += i ; } )* { return value ; } } |
其中Primary()得到一个数的值:
|
double Primary() throws NumberFormatException : { Token t ; } { t= <NUMBER> { return Double.parseDouble( t.image ) ; } } |
(5) 扩展词法分析器和语法分析器
如果我们想支持减法,则需要在词法分析器中添加:
|
TOKEN : { < MINUS : "-" > } |
语法分析器应该变为:
|
Expression -> Primary (PLUS Primary | MINUS Primary)* |
|
double Expression() throws NumberFormatException : { double i ; double value ; } { value = Primary() ( <PLUS> i = Primary() { value += i ; } | <MINUS> i = Primary() { value -= i ; } )* { return value ; } } |
如果我们想添加乘法和除法,则在词法分析器中应该加入:
|
TOKEN : { < TIMES : "*" > } TOKEN : { < DIVIDE : "/" > } |
对于加减乘除混合运算,则应该考虑优先级,乘除的优先级高于加减,应该先做乘除,再做加减:
|
Expression -> Term (PLUSTerm | MINUSTerm)* Term -> Primary (TIMES Primary | DIVIDE Primary)* |
|
double Expression() throws NumberFormatException : { double i ; double value ; } { value = Term() ( <PLUS> i= Term() { value += i ; } | <MINUS> i= Term() { value -= i ; } )* { return value ; } } |
|
double Term() throws NumberFormatException : { double i ; double value ; } { value = Primary() ( <TIMES> i = Primary() { value *= i ; } | <DIVIDE> i = Primary() { value /= i ; } )* { return value ; } } |
下面我们要开始支持括号,负号,以及取得上一行四则运算表达式的值。
对于词法分析器,我们添加如下Token:
|
TOKEN : { < OPEN PAR : "(" > } TOKEN : { < CLOSE PAR : ")" > } TOKEN : { < PREVIOUS : "$" > } |
对于语法分析器,对于最基本的表达式,有四种情况:
其可以是一个NUMBER,也可以是上一行四则运算表达式的值PREVIOUS,也可以是被括号括起来的一个子语法表达式,也可以是取负的一个基本语法表达式。
|
Primary –> NUMBER | PREVIOUS | OPEN_PAR Expression CLOSE_PAR | MINUS Primary |
|
double Primary() throws NumberFormatException : { Token t ; double d ; } { t=<NUMBER> { return Double.parseDouble( t.image ) ; } | <PREVIOUS> { return previousValue ; } | <OPEN PAR> d=Expression() <CLOSE PAR> { return d ; } | <MINUS> d=Primary() { return -d ; } } |
(6) 用javacc编译calculator.jj来生成语法分析器和词法分析器
最后生成的calculator.jj如下:
|
options PARSER_BEGIN(Calculator) SKIP : { " " } void start(PrintStream printStream) throws NumberFormatException : double Expression() throws NumberFormatException : double Term() throws NumberFormatException : double Primary() throws NumberFormatException : |
生成的start函数如下:
|
final public void start(PrintStream printStream) throws ParseException, NumberFormatException { label_1: while (true) { switch ((jj_ntk==-1)?jj_ntk():jj_ntk) { case MINUS: case NUMBER: case OPEN_PAR: case PREVIOUS: ; break; default: jj_la1[0] = jj_gen; break label_1; } previousValue = Expression(); printStream.println( previousValue ) ; } } final public double Expression() throws ParseException, NumberFormatException { double i ; double value ; value = Term(); label_2: while (true) { switch ((jj_ntk==-1)?jj_ntk():jj_ntk) { case PLUS: case MINUS: ; break; default: jj_la1[1] = jj_gen; break label_2; } switch ((jj_ntk==-1)?jj_ntk():jj_ntk) { case PLUS: jj_consume_token(PLUS); i = Term(); value += i ; break; case MINUS: jj_consume_token(MINUS); i = Term(); value -= i ; break; default: jj_la1[2] = jj_gen; jj_consume_token(-1); throw new ParseException(); } } {if (true) return value ;} throw new Error("Missing return statement in function"); } final public double Term() throws ParseException, NumberFormatException { double i ; double value ; value = Primary(); label_3: while (true) { switch ((jj_ntk==-1)?jj_ntk():jj_ntk) { case TIMES: case DIVIDE: ; break; default: jj_la1[3] = jj_gen; break label_3; } switch ((jj_ntk==-1)?jj_ntk():jj_ntk) { case TIMES: jj_consume_token(TIMES); i = Primary(); value *= i ; break; case DIVIDE: jj_consume_token(DIVIDE); i = Primary(); value /= i ; break; default: jj_la1[4] = jj_gen; jj_consume_token(-1); throw new ParseException(); } } {if (true) return value ;} throw new Error("Missing return statement in function"); } final public double Primary() throws ParseException, NumberFormatException { Token t ; double d ; switch ((jj_ntk==-1)?jj_ntk():jj_ntk) { case NUMBER: t = jj_consume_token(NUMBER); {if (true) return Double.parseDouble( t.image ) ;} break; case PREVIOUS: jj_consume_token(PREVIOUS); {if (true) return previousValue ;} break; case OPEN_PAR: jj_consume_token(OPEN_PAR); d = Expression(); jj_consume_token(CLOSE_PAR); {if (true) return d ;} break; case MINUS: jj_consume_token(MINUS); d = Primary(); {if (true) return -d ;} break; default: jj_la1[5] = jj_gen; jj_consume_token(-1); throw new ParseException(); } throw new Error("Missing return statement in function"); } |
三、解析QueryParser.jj
3.1、声明QueryParser类
在QueryParser.jj文件中,PARSER_BEGIN(QueryParser)和PARSER_END(QueryParser)之间,定义了QueryParser类。
其中最重要的一个函数是public Query parse(String query)函数,也即我们解析Lucene查询语法的时候调用的函数。
这是一个纯Java代码定义的函数,会直接拷贝到QueryParser.java文件中。
parse函数中,最重要的一行代码是调用Query res = TopLevelQuery(field),而TopLevelQuery函数是QueryParser.jj中定义的语法分析器被JavaCC编译后会生成的函数。
3.2、声明词法分析器
在解析词法分析器之前,首先介绍一下JavaCC的词法状态的概念(lexical state)。
有可能存在如下的情况,在不同的情况下,要求的词法词法规则不同,比如我们要解析一个java文件(即满足java语法的表达式),在默认的状态DEFAULT下,是要求解析的对象(即表达式)满足java语言的词法规则,然而当出现"/**"的时候,其后面的表达式则不需要满足java语言的语法规则,而是应该满足java注释的语法规则(要识别@param变量等),于是我们做如下定义:
|
//默认处于DEFAULT状态,当遇到/**的时候,转换为IN_JAVADOC_COMMENT状态 <DEFAULT> TOKEN : {<STARTDOC : “/**” > : IN_JAVADOC_COMMENT } //在IN_JAVADOC_COMMENT状态下,需要识别@param变量 <IN_JAVADOC_COMMENT> TOKEN : {<PARAM : "@param" >} //在IN_JAVADOC_COMMENT状态下,遇到*/的时候,装换为DEFAULT状态 <IN_JAVADOC_COMMENT> TOKEN : {<ENDDOC: "*/">: DEFAULT } |
<*> 表示应用于任何状态。
(1) 应用于所有状态的变量
|
<*> TOKEN : { <#_NUM_CHAR: ["0"-"9"] > //数字 | <#_ESCAPED_CHAR: "//" ~[] > //"/"后的任何一个字符都是被转义的 | <#_TERM_START_CHAR: ( ~[ " ", "/t", "/n", "/r", "/u3000", "+", "-", "!", "(", ")", ":", "^", "[", "]", "/"", "{", "}", "~", "*", "?", "//" ] | <_ESCAPED_CHAR> ) > //表达式中任何一个term,都不能以[]括起来的列表中的lucene查询语法关键字开头,当然被转义的除外。 | <#_TERM_CHAR: ( <_TERM_START_CHAR> | <_ESCAPED_CHAR> | "-" | "+" ) > //表达式中的term非起始字符,可以包含任何非语法关键字字符,转义过的字符,也可以包含+, -(但包含+,-的符合词法,不合语法)。 | <#_WHITESPACE: ( " " | "/t" | "/n" | "/r" | "/u3000") > //被认为是空格的字符 | <#_QUOTED_CHAR: ( ~[ "/"", "//" ] | <_ESCAPED_CHAR> ) > //被引号括起来的字符不应再包括"和/,当然转义过的除外。 } |
(2) 默认状态的Token
|
<DEFAULT> TOKEN : { <AND: ("AND" | "&&") > | <OR: ("OR" | "||") > | <NOT: ("NOT" | "!") > | <PLUS: "+" > | <MINUS: "-" > | <LPAREN: "(" > | <RPAREN: ")" > | <COLON: ":" > | <STAR: "*" > | <CARAT: "^" > : Boost //当遇到^的时候,后面跟随的是boost表达式,进入Boost状态 | <QUOTED: "/"" (<_QUOTED_CHAR>)* "/""> | <TERM: <_TERM_START_CHAR> (<_TERM_CHAR>)* > | <FUZZY_SLOP: "~" ( (<_NUM_CHAR>)+ ( "." (<_NUM_CHAR>)+ )? )? > //Fuzzy查询,~后面跟小数。 | <PREFIXTERM: ("*") | ( <_TERM_START_CHAR> (<_TERM_CHAR>)* "*" ) > //使用*进行Prefix查询,可以尽包含*,或者末尾包含*,然而只包含*符合词法,不合语法。 | <WILDTERM: (<_TERM_START_CHAR> | [ "*", "?" ]) (<_TERM_CHAR> | ( [ "*", "?" ] ))* > //使用*和?进行wildcard查询 | <RANGEIN_START: "[" > : RangeIn //遇到[]的时候,是包含边界的Range查询 | <RANGEEX_START: "{" > : RangeEx //遇到{}的时候,是不包含边界的Range查询 } |
|
<Boost> TOKEN : { <NUMBER: (<_NUM_CHAR>)+ ( "." (<_NUM_CHAR>)+ )? > : DEFAULT //boost是一个小数 } |
|
//包含边界的Range查询是[A TO B]的形式。 <RangeIn> TOKEN : { <RANGEIN_TO: "TO"> | <RANGEIN_END: "]"> : DEFAULT | <RANGEIN_QUOTED: "/"" (~["/""] | "///"")+ "/""> | <RANGEIN_GOOP: (~[ " ", "]" ])+ > } |
|
//不包含边界的Range查询是{A TO B}的形式 <RangeEx> TOKEN : { <RANGEEX_TO: "TO"> | <RANGEEX_END: "}"> : DEFAULT | <RANGEEX_QUOTED: "/"" (~["/""] | "///"")+ "/""> | <RANGEEX_GOOP: (~[ " ", "}" ])+ > } |
3.3、声明语法分析器
Lucene的语法规则如下:
|
Query ::= ( Clause )* Clause ::= ["+", "-"] [<TERM> ":"] ( <TERM> | "(" Query ")" ) |
(1) 从Query到Clause
一个Query查询语句,是由多个clause组成的,每个clause有修饰符Modifier,或为+, 或为-,clause之间的有连接符,或为AND,或为OR,或为NOT。
在Lucene的语法解析中NOT被算作Modifier,和-起相同作用。
此过程表达式如下:
|
Query TopLevelQuery(String field) : { Query q; } { q=Query(field) <EOF> { return q; } } |
|
Query Query(String field) : { List<BooleanClause> clauses = new ArrayList<BooleanClause>(); Query q, firstQuery=null; int conj, mods; } { //查询语句开头是一个Modifier,可以为空 //Modifier后面便是子语句clause,可以生成子查询语句q mods=Modifiers() q=Clause(field) { //如果第一个语句的Modifier是空,则将子查询q付给firstQuery,从后面我们可以看到,当只有一个查询语句的时候,如果其Modifier为空,则不返回BooleanQuery,而是返回子查询对象firstQuery。从这里我们可以看出,如果查询语句为"A",则生成TermQuery,其term为"A",如果查询语句为"+A",则生成BooleanQuery,其子查询只有一个,就是TermQuery,其term为"A"。 addClause(clauses, CONJ_NONE, mods, q); if (mods == MOD_NONE) firstQuery=q; } ( //除了第一个语句外,其他的前面可以有连接符,或为AND,或为OR。 //如果在第一个语句之前出现连接符,则报错,如"OR a",会报Encountered " <OR> "OR "" at line 1, column 0. //除了连接符,也会有Modifier,后面是子语句clause,生成子查询q,并加入BooleanQuery中。 conj=Conjunction() mods=Modifiers() q=Clause(field) { addClause(clauses, conj, mods, q); } )* { //如果只有一个查询语句,且其modifier为空,则返回firstQuery,否则由所有的子语句clause,生成BooleanQuery。 if (clauses.size() == 1 && firstQuery != null) return firstQuery; else { return getBooleanQuery(clauses); } } } |
|
int Modifiers() : { //默认modifier为空,如果遇到+,就是required,如果遇到-或者NOT,就是prohibited。 int ret = MOD_NONE; } { [ <PLUS> { ret = MOD_REQ; } | <MINUS> { ret = MOD_NOT; } | <NOT> { ret = MOD_NOT; } ] { return ret; } } |
|
//连接符 int Conjunction() : { int ret = CONJ_NONE; } { [ <AND> { ret = CONJ_AND; } | <OR> { ret = CONJ_OR; } ] { return ret; } } |
(2) 一个子语句clause
由上面的分析我们可以知道,JavaCC使用的是编译原理里面的自上而下分析法,基本采用的是LL(1)的方法:
- 第一个L :从左到右扫描输入串
- 第二个L :生成的是最左推导
- (1):向前看一个输入符号(lookahead)
JavaCC还提供LOOKAHEAD(n),也即当仅读入下一个符号时,不足以判断接下来的如何解析,会出现Choice Conflict,则需要多读入几个符号,来进一步判断。
|
Query Clause(String field) : { Query q; Token fieldToken=null, boost=null; } { //此处之所以向前看两个符号,就是当看到<TERM>的时候,不知道它是一个field,还是一个term,当<TERM><COLON>在一起的时候,说明<TERM>代表一个field, 否则代表一个term [ LOOKAHEAD(2) ( fieldToken=<TERM> <COLON> {field=discardEscapeChar(fieldToken.image);} | <STAR> <COLON> {field="*";} ) ] ( //或者是一个term,则由此term生成一个查询对象 //或者是一个由括号括起来的子查询 //()?表示可能存在一个boost,格式为^加一个数字 q=Term(field) | <LPAREN> q=Query(field) <RPAREN> (<CARAT> boost=<NUMBER>)? ) { //如果存在boost,则设定查询对象的boost if (boost != null) { float f = (float)1.0; try { f = Float.valueOf(boost.image).floatValue(); q.setBoost(f); } catch (Exception ignored) { } } return q; } } |
|
Query Term(String field) : { Token term, boost=null, fuzzySlop=null, goop1, goop2; boolean prefix = false; boolean wildcard = false; boolean fuzzy = false; Query q; } { ( ( //如果term仅结尾包含*则是prefix查询。 //如果以*开头,或者中间包含*,或者结尾包含*(如果仅结尾包含,则prefix优先)则为wildcard查询。 term=<TERM> | term=<STAR> { wildcard=true; } | term=<PREFIXTERM> { prefix=true; } | term=<WILDTERM> { wildcard=true; } | term=<NUMBER> ) //如果term后面是~,则是fuzzy查询 [ fuzzySlop=<FUZZY_SLOP> { fuzzy=true; } ] [ <CARAT> boost=<NUMBER> [ fuzzySlop=<FUZZY_SLOP> { fuzzy=true; } ] ] { //如果是wildcard查询,则调用getWildcardQuery, // *:*得到MatchAllDocsQuery,将返回所有的文档 // 目前不支持最前面带通配符的查询(虽然词法分析和语法分析都能通过),否则报ParseException // 最后生成WildcardQuery //如果是prefix查询,则调用getPrefixQuery,生成PrefixQuery //如果是fuzzy查询,则调用getFuzzyQuery,生成FuzzyQuery //如果是普通查询,则调用getFieldQuery String termImage=discardEscapeChar(term.image); if (wildcard) { q = getWildcardQuery(field, termImage); } else if (prefix) { q = getPrefixQuery(field, discardEscapeChar(term.image.substring(0, term.image.length()-1))); } else if (fuzzy) { float fms = fuzzyMinSim; try { fms = Float.valueOf(fuzzySlop.image.substring(1)).floatValue(); } catch (Exception ignored) { } if(fms < 0.0f || fms > 1.0f){ throw new ParseException("Minimum similarity for a FuzzyQuery has to be between 0.0f and 1.0f !"); } q = getFuzzyQuery(field, termImage,fms); } else { q = getFieldQuery(field, termImage); } } //包含边界的range查询,取得[goop1 TO goop2],调用getRangeQuery,生成TermRangeQuery | ( <RANGEIN_START> ( goop1=<RANGEIN_GOOP>|goop1=<RANGEIN_QUOTED> ) [ <RANGEIN_TO> ] ( goop2=<RANGEIN_GOOP>|goop2=<RANGEIN_QUOTED> ) <RANGEIN_END> ) [ <CARAT> boost=<NUMBER> ] { if (goop1.kind == RANGEIN_QUOTED) { goop1.image = goop1.image.substring(1, goop1.image.length()-1); } if (goop2.kind == RANGEIN_QUOTED) { goop2.image = goop2.image.substring(1, goop2.image.length()-1); } q = getRangeQuery(field, discardEscapeChar(goop1.image), discardEscapeChar(goop2.image), true); } //不包含边界的range查询,取得{goop1 TO goop2},调用getRangeQuery,生成TermRangeQuery | ( <RANGEEX_START> ( goop1=<RANGEEX_GOOP>|goop1=<RANGEEX_QUOTED> ) [ <RANGEEX_TO> ] ( goop2=<RANGEEX_GOOP>|goop2=<RANGEEX_QUOTED> ) <RANGEEX_END> ) [ <CARAT> boost=<NUMBER> ] { if (goop1.kind == RANGEEX_QUOTED) { goop1.image = goop1.image.substring(1, goop1.image.length()-1); } if (goop2.kind == RANGEEX_QUOTED) { goop2.image = goop2.image.substring(1, goop2.image.length()-1); } q = getRangeQuery(field, discardEscapeChar(goop1.image), discardEscapeChar(goop2.image), false); } //被""括起来的term,得到phrase查询,调用getFieldQuery | term=<QUOTED> [ fuzzySlop=<FUZZY_SLOP> ] [ <CARAT> boost=<NUMBER> ] { int s = phraseSlop; if (fuzzySlop != null) { try { s = Float.valueOf(fuzzySlop.image.substring(1)).intValue(); } catch (Exception ignored) { } } q = getFieldQuery(field, discardEscapeChar(term.image.substring(1, term.image.length()-1)), s); } ) { if (boost != null) { float f = (float) 1.0; try { f = Float.valueOf(boost.image).floatValue(); } catch (Exception ignored) { } // avoid boosting null queries, such as those caused by stop words if (q != null) { q.setBoost(f); } } return q; } } |
此处需要详细解析的是getFieldQuery:
|
protected Query getFieldQuery(String field, String queryText) throws ParseException { //需要用analyzer对文本进行分词 TokenStream source; try { source = analyzer.reusableTokenStream(field, new StringReader(queryText)); source.reset(); } catch (IOException e) { source = analyzer.tokenStream(field, new StringReader(queryText)); } CachingTokenFilter buffer = new CachingTokenFilter(source); TermAttribute termAtt = null; PositionIncrementAttribute posIncrAtt = null; int numTokens = 0; boolean success = false; try { buffer.reset(); success = true; } catch (IOException e) { } //得到TermAttribute和PositionIncrementAttribute,此两项将决定到底产生什么样的Query对象 if (success) { if (buffer.hasAttribute(TermAttribute.class)) { termAtt = buffer.getAttribute(TermAttribute.class); } if (buffer.hasAttribute(PositionIncrementAttribute.class)) { posIncrAtt = buffer.getAttribute(PositionIncrementAttribute.class); } } int positionCount = 0; boolean severalTokensAtSamePosition = false; boolean hasMoreTokens = false; if (termAtt != null) { try { //遍历分词后的所有Token,统计Tokens的个数numTokens,以及positionIncrement的总数,即positionCount。 //当有一次positionIncrement为0的时候,severalTokensAtSamePosition设为true,表示有多个Token处在同一个位置。 hasMoreTokens = buffer.incrementToken(); while (hasMoreTokens) { numTokens++; int positionIncrement = (posIncrAtt != null) ? posIncrAtt.getPositionIncrement() : 1; if (positionIncrement != 0) { positionCount += positionIncrement; } else { severalTokensAtSamePosition = true; } hasMoreTokens = buffer.incrementToken(); } } catch (IOException e) { } } try { //重设buffer,以便生成phrase查询的时候,term和position可以重新遍历。 buffer.reset(); source.close(); } catch (IOException e) { } if (numTokens == 0) return null; else if (numTokens == 1) { //如果分词后只有一个Token,则生成TermQuery String term = null; try { boolean hasNext = buffer.incrementToken(); term = termAtt.term(); } catch (IOException e) { } return newTermQuery(new Term(field, term)); } else { //如果分词后不只有一个Token if (severalTokensAtSamePosition) { //如果有多个Token处于同一个位置 if (positionCount == 1) { //并且处于同一位置的Token还全部处于第一个位置,则生成BooleanQuery,处于同一位置的Token之间是OR的关系 BooleanQuery q = newBooleanQuery(true); for (int i = 0; i < numTokens; i++) { String term = null; try { boolean hasNext = buffer.incrementToken(); term = termAtt.term(); } catch (IOException e) { } Query currentQuery = newTermQuery(new Term(field, term)); q.add(currentQuery, BooleanClause.Occur.SHOULD); } return q; } else { //如果有多个Token处于同一位置,但不是第一个位置,则生成MultiPhraseQuery。 //所谓MultiPhraseQuery即其可以包含多个phrase,其又一个ArrayList<Term[]> termArrays,每一项都是一个Term的数组,属于同一个数组的Term表示在同一个位置。它有函数void add(Term[] terms)一次添加一个数组的Term。比如我们要搜索"microsoft app*",其表示多个phrase,"microsoft apple","microsoft application"都算。此时用QueryParser.parse("/"microsoft MultiPhraseQuery mpq = newMultiPhraseQuery(); mpq.setSlop(phraseSlop); List<Term> multiTerms = new ArrayList<Term>(); int position = -1; for (int i = 0; i < numTokens; i++) { String term = null; int positionIncrement = 1; try { boolean hasNext = buffer.incrementToken(); assert hasNext == true; term = termAtt.term(); if (posIncrAtt != null) { positionIncrement = posIncrAtt.getPositionIncrement(); } } catch (IOException e) { } if (positionIncrement > 0 && multiTerms.size() > 0) { //如果positionIncrement大于零,说明此Term和前一个Term已经不是同一个位置了,所以原来收集在multiTerms中的Term都算作同一个位置,添加到MultiPhraseQuery中作为一项。并清除multiTerms,以便重新收集相同位置的Term。 if (enablePositionIncrements) { mpq.add(multiTerms.toArray(new Term[0]),position); } else { mpq.add(multiTerms.toArray(new Term[0])); } multiTerms.clear(); } //将此Term收集到multiTerms中。 position += positionIncrement; multiTerms.add(new Term(field, term)); } //当遍历完所有的Token,同处于最后一个位置的Term已经收集到multiTerms中了,把他们加到MultiPhraseQuery中作为一项。 if (enablePositionIncrements) { mpq.add(multiTerms.toArray(new Term[0]),position); } else { mpq.add(multiTerms.toArray(new Term[0])); } return mpq; } } else { //如果不存在多个Token处于同一个位置的情况,则直接生成PhraseQuery PhraseQuery pq = newPhraseQuery(); pq.setSlop(phraseSlop); int position = -1; for (int i = 0; i < numTokens; i++) { String term = null; int positionIncrement = 1; try { boolean hasNext = buffer.incrementToken(); assert hasNext == true; term = termAtt.term(); if (posIncrAtt != null) { positionIncrement = posIncrAtt.getPositionIncrement(); } } catch (IOException e) { } if (enablePositionIncrements) { position += positionIncrement; pq.add(new Term(field, term),position); } else { pq.add(new Term(field, term)); } } return pq; } } } |
Lucene学习总结之八:Lucene的查询语法,JavaCC及QueryParser的更多相关文章
- Lucene学习总结之八:Lucene的查询语法,JavaCC及QueryParser 2014-06-25 14:25 722人阅读 评论(1) 收藏
一.Lucene的查询语法 Lucene所支持的查询语法可见http://lucene.apache.org/java/3_0_1/queryparsersyntax.html (1) 语法关键字 + ...
- Lucene学习之四:Lucene的索引文件格式(3)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2010/02/02/1661436.html ,略有删改和备注. 四.具体格式 4.2. 反向信 ...
- Lucene学习之四:Lucene的索引文件格式(2)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623599.html 略有删减和补充 四.具体格式 上面曾经交代过,L ...
- Lucene学习之四:Lucene的索引文件格式(1)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623597.html Lucene的索引里面存了些什么,如何存放的,也即 ...
- Lucene的查询语法,JavaCC及QueryParser(1)
http://www.cnblogs.com/forfuture1978/archive/2010/05/08/1730200.html 一.Lucene的查询语法 Lucene所支持的查询语法可见h ...
- Lucene查询语法详解
Lucene查询 Lucene查询语法以可读的方式书写,然后使用JavaCC进行词法转换,转换成机器可识别的查询. 下面着重介绍下Lucene支持的查询: Terms词语查询 词语搜索,支持 单词 和 ...
- kibana使用(ELK)、Lucene 查询语法
Lucene查询 Lucene查询语法以可读的方式书写,然后使用JavaCC进行词法转换,转换成机器可识别的查询. 下面着重介绍下Lucene支持的查询: Terms词语查询 词语搜索,支持 单词 和 ...
- query_string查询支持全部的Apache Lucene查询语法 低频词划分依据 模糊查询 Disjunction Max
3.3 基本查询3.3.1词条查询 词条查询是未经分析的,要跟索引文档中的词条完全匹配注意:在输入数据中,title字段含有Crime and Punishment,但我们使用小写开头的crime来搜 ...
- Lucene学习总结之七:Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
随机推荐
- D3.js data() 方法详解
Binding data(数据绑定) D3各种图表的作用体现在将数据(Data)转换成可视化的过程. 比如将一个月的气温数据,通过树形图来展现,能够直观的看到气温走势,下个月还需不需要穿秋裤 :) 我 ...
- django的model对象转化成dict
今天发现一个掉渣天的方法,Django的forms包里面有一个方法:model_to_dict(),它可以将一个model对象转化成dict. In [1]: from apps.dormitory. ...
- 关于String s = new String("xyz"); 创建几个对象的问题
引用自这位朋友:http://blog.sina.com.cn/s/blog_6a6b14100100zn6r.html 你知道在java中除了8中基本类型外,其他的都是类对象以及其引用.所以 &qu ...
- 执行yiic webapp命令时报错:php.exe不是内部或外部命令,也不是可运行的程序
在执行 yiic webapp ../abc 命令时报错: “php.exe”不是内部或外部命令,也不是可运行的程序 或批处理文件. 这是因为yiic批处理程序找不到php.exe的执行路径引起的. ...
- LeetCode_Container With Most Water
Given n non-negative integers a1, a2, ..., an, where each represents a point at coordinate (i, ai). ...
- c++中经常需要访问对象中的成员的三种方式
可以有3种方法: 通过对象名和成员运算符访问对象中的成员; 通过指向对象的指针访问对象中的成员; 通过对象的引用变量访问对象中的成员. 一.通过对象名和成员运算符访问对象中的成员 例如在程序中可以写出 ...
- android 缓存Bitmap - 开发文档翻译
由于本人英文能力实在有限,不足之初敬请谅解 本博客只要没有注明“转”,那么均为原创,转贴请注明本博客链接链接 Loading a single bitmap into your user interf ...
- 一个简陋的 CSS 样式
有些网友对 Smart Framewok 中的 Sample 示例的样式比较感兴趣.由于本人对前端不太精通,但为了满足网友们的需求,只好献丑了. 以下这个简陋的 CSS 样式: ? 1 2 3 4 5 ...
- 原生AJAX如何异步提交数据?
AJAX概述 AJAX:Asynchronous Javascript And XML,异步的JS和XML.2001,Google为了改进搜索的用户体验,提出了GoogleSugguest效果,正式提 ...
- vps安全设置
适合新手及才接触VPS的朋友们看一下.主要是关于VPS安全方面相关内容的 禁止ROOT登陆 保证安全性. 使用DDoS deflate简单防攻击. iftop Linux流量监控工具: 每日自己主动备 ...