hadoop详细了解5个进程的作用
1.job的本质是什么?
2.任务的本质是什么?
3.文件系统的Namespace由谁来管理,Namespace的作用是什么?
4.Namespace 镜像文件(Namespace image)和操作日志文件(edit log)文件的作用是什么?
5.Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,为什么?
6.客户端读写某个数据时,是否通过NameNode?
7.namenode,datanode,Namespace image,Edit log之间的关系是什么?
8.一旦某个task失败了,JobTracker如何处理?
9.JobClient JobClient在获取了JobTracker为Job分配的id之后,会在JobTracker的系统目录(HDFS)下为该Job创建一个单独的目录,目录的名字即是Job的id,该目录下
会包含文件job.xml、job.jar等文件,这两个文件的作用是什么?
10.JobTracker根据什么就能得到这个Job目录?
11.JobTracker提交作业之前,为什么要检查内存?
12.每个TaskTracker产生多个java 虚拟机(JVM)的原因是什么?

概述:
<ignore_js_op>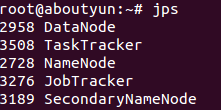
Hadoop是一个能够对大量数据进行分布式处理的软件框架,实现了Google的MapReduce编程模型和框架,能够把应用程序分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行。在MapReduce中,一个准备提交执行的应用程序称为“作业(job)”,而从一个作业划分出 得、运行于各个计算节点的工作单元称为“任务(task)”。此外,Hadoop提供的分布式文件系统(HDFS)主要负责各个节点的数据存储,并实现了 高吞吐率的数据读写。
在分布式存储和分布式计算方面,Hadoop都是用从/从(Master/Slave)架构。在一个配置完整的集群上,想让Hadoop这头大 象奔跑起来,需要在集群中运行一系列后台(deamon)程序。不同的后台程序扮演不用的角色,这些角色由NameNode、DataNode、 Secondary NameNode、JobTracker、TaskTracker组成。其中NameNode、Secondary NameNode、JobTracker运行在Master节点上,而在每个Slave节点上,部署一个DataNode和TaskTracker,以便 这个Slave服务器运行的数据处理程序能尽可能直接处理本机的数据。对Master节点需要特别说明的是,在小集群中,Secondary NameNode可以属于某个从节点;在大型集群中,NameNode和JobTracker被分别部署在两台服务器上。
我们已经很熟悉这个5个进程,但是在使用的过程中,我们经常遇到问题,那么该如何入手解决这些问题。那么首先我们需了解的他们的原理和作用。
1.Namenode介绍
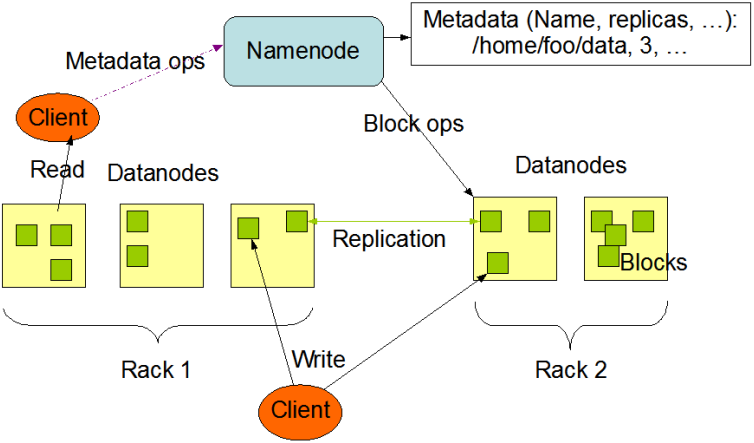
2、Datanode介绍
3、Secondary NameNode介绍
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的 快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
3.1NameNode的目录结构如下:
3.2Secondary NameNode的目录结构如下:

4、JobTracker介绍
4.1JobClient

在Hadoop中,作业是使用Job对象来抽象的,对于Job,我首先不得不介绍它的一个大家伙JobClient——客户端的实际工作者。JobClient除了自己完成一部分必要的工作外,还负责与JobTracker进行交互。所以客户端对Job的提交,绝大部分都是JobClient完成的,从上图中,我们可以得知JobClient提交Job的详细流程主要如下:

4.2JobTracker
上面谈到了客户端的JobClient对一个作业的提交所做的工作,那么这里,就要好好的谈一谈JobTracker为作业的提交到底干了那些个事情——一.为作业生成一个Job;二.接受该作业。
我们都知道,客户端的JobClient把作业的所有相关信息都保存到了JobTracker的系统目录下(当然是HDFS了),这样做的一个最大的好处就是客户端干了它所能干的事情同时也减少了服务器端JobTracker的负载。下面就来看看JobTracker是如何来完成客户端作业的提交的吧!哦。对了,在这里我不得不提的是客户端的JobClient向JobTracker正式提交作业时直传给了它一个改作业的JobId,这是因为与Job相关的所有信息已经存在于JobTracker的系统目录下,JobTracker只要根据JobId就能得到这个Job目录。
<ignore_js_op>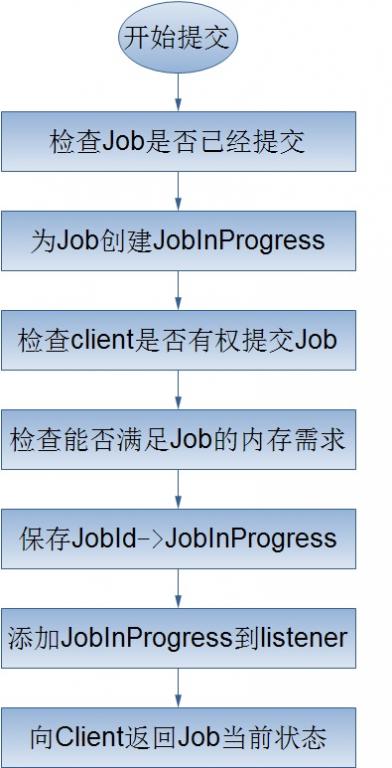
对于上面的Job的提交处理流程,我将简单的介绍以下几个过程:
1.创建Job的JobInProgress
JobInProgress对象详细的记录了Job的配置信息,以及它的执行情况,确切的来说应该是Job被分解的map、reduce任务。在JobInProgress对象的创建过程中,它主要干了两件事,一是把Job的job.xml、job.jar文件从Job目录copy到JobTracker的本地文件系统(job.xml->*/jobTracker/jobid.xml,job.jar->*/jobTracker/jobid.jar);二是创建JobStatus和Job的mapTask、reduceTask存队列来跟踪Job的状态信息。
2.检查客户端是否有权限提交Job
JobTracker验证客户端是否有权限提交Job实际上是交给QueueManager来处理的。
3.检查当前mapreduce集群能够满足Job的内存需求
客户端提交作业之前,会根据实际的应用情况配置作业任务的内存需求,同时JobTracker为了提高作业的吞吐量会限制作业任务的内存需求,所以在Job的提交时,JobTracker需要检查Job的内存需求是否满足JobTracker的设置。
上面流程已经完毕,可以总结为下图:
<ignore_js_op>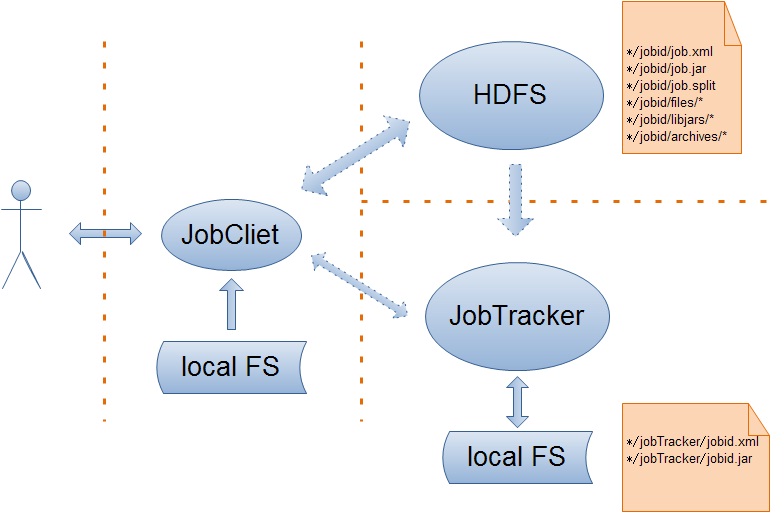
--------------------------------------------------------------------------------------------------------------------------
5、TaskTracker介绍
TaskTracker与负责存储数据的DataNode相结合,其处理结构上也遵循主/从架构。JobTracker位于主节点,统领 MapReduce工作;而TaskTrackers位于从节点,独立管理各自的task。每个TaskTracker负责独立执行具体的task,而 JobTracker负责分配task。虽然每个从节点仅有一个唯一的一个TaskTracker,但是每个TaskTracker可以产生多个java 虚拟机(JVM),用于并行处理多个map以及reduce任务。TaskTracker的一个重要职责就是与JobTracker交互。如果 JobTracker无法准时地获取TaskTracker提交的信息,JobTracker就判定TaskTracker已经崩溃,并将任务分配给其他 节点处理。
5.1TaskTracker内部设计与实现
Hadoop采用master-slave的架构设计来实现Map-Reduce框架,它的JobTracker节点作为主控节点来管理和调度用户提交的作业,TaskTracker节点作为工作节点来负责执行JobTracker节点分配的Map/Reduce任务。整个集群由一个JobTracker节点和若干个TaskTracker节点组成,当然,JobTracker节点也负责对TaskTracker节点进行管理。在前面一系列的博文中,我已经比较系统地讲述了JobTracker节点内部的设计与实现,而在本文,我将对TaskTracker节点的内部设计与实现进行一次全面的概述。
TaskTracker节点作为工作节点不仅要和JobTracker节点进行频繁的交互来获取作业的任务并负责在本地执行他们,而且也要和其它的TaskTracker节点交互来协同完成同一个作业。因此,在目前的Hadoop-0.20.2.0实现版本中,对工作节点TaskTracker的设计主要包含三类组件:服务组件、管理组件、工作组件。服务组件不仅负责与其它的TaskTracker节点而且还负责与JobTracker节点之间的通信服务,管理组件负责对该节点上的任务、作业、JVM实例以及内存进行管理,工作组件则负责调度Map/Reduce任务的执行。这三大组件的详细构成如下:

下面来详细的介绍这三类组件:
服务组件
TaskTracker节点内部的服务组件不仅用来为TaskTracker节点、客户端提供服务,而且还负责向TaskTracker节点请求服务,这一类组件主要包括HttpServer、TaskReportServer、JobClient三大组件。
1.HttpServer
TaskTracker节点在其内部使用Jetty Web容器来开启http服务,这个http服务一是用来为客户端提供Task日志查询服务,二是用来提供数据传输服务,即在执行Reduce任务时是通过TaskTracker节点提供的该http服务来获取属于自己的map输出数据。这里需要详细介绍的是与该服务相关的配置参数,集群管理者可以通过TaskTracker节点的配置文件来配置该服务地址和端口号,对应的配置项为:mapred.task.tracker.http.address。同时,为了能够灵活的控制该该服务的吞吐量,管理者还可以设置该http服务的内部工作线程数量,对应的配置为:tasktracker.http.threads。
2.Task Reporter
TaskTracker节点在接收到JobTracker节点发送过来的Map/Reduce任务之后,会把它们交给JVM实例来执行,而自己则需要收集这些任务的执行进度信息,这就使得Task在JVM实例中执行的时候需要不断地向TaskTracker节点报告当前的执行情况。虽然TaskTracker节点和JVM实例在同一台机器上,但是它们之间的进程通信却是通过网络I/O来完成的(此处并不讨论这种通信方式的性能),也就是TaskTracker节点在其内部开启一个端口来专门为任务实例提供进度报告服务。该服务地址可以通过配置项mapred.task.tracker.report.address来设置,而服务内部的工作线程的数量取2倍于该TaskTracker节点上的Map/Reduce Slot数量中的大者。
hadoop详细了解5个进程的作用的更多相关文章
- 【好文推荐】黑莓OS手册是如何详细阐述底层的进程和线程模型的?
「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」. 当然 ...
- 启动hadoop,没有启动namenode进程。log4j:ERROR setFile(null,true) call faild.
启动hadoop,没有启动namenode进程.log4j:ERROR setFile(null,true) call faild. 解决办法: cd /home/hadoop/hadoop-en ...
- hadoop的五个守护进程【转】
hadoop的五个守护进程 [转自]:http://xubindehao.iteye.com/blog/1395580 一般如果正常启动hadoop,我们可以在master上通过jps命令看到以下5 ...
- Hadoop守护进程的作用(转)
概述: <ignore_js_op> Hadoop是一个能够对大量数据进行分布式处理的软件框架,实现了Google的MapReduce编程模型和框架,能够把应用程序分割成许多的 小的工作单 ...
- Hadoop中HDFS 的相关进程以及工作流程图(详细流程图)
- Hadoop详细配置教程
windows下采用PuTTY或者Xshell连接远程主机 mac用终端连接远程linux主机:ssh user@hostname user 为 linux 服务器的管理员名称 hostname 为 ...
- GIS Tools for Hadoop 详细介绍
2013年Esri美国在开发者大会上演示了GIS数据结合Hadoop分析的一个示例,这个示例赢得了听众的阵阵掌声,我们也许对GIS不是很陌生,但是对Hadoop却不是很清楚,其实Esri是用Java开 ...
- Hadoop详细安装步骤
hadoop安装:(分布式模式)参考地址:http://dblab.xmu.edu.cn/blog/install-hadoop/ http://dblab.xmu.edu.cn/blog/insta ...
- 全网最详细的启动zkfc进程时,出现INFO zookeeper.ClientCnxn: Opening socket connection to server***/192.168.80.151:2181. Will not attempt to authenticate using SASL (unknown error)解决办法(图文详解)
不多说,直接上干货! at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:) at org ...
随机推荐
- Android图片与缩略
/** * 将图片文件原比例缩略.并使其不超过最大宽.高 * @param path : 图片文件 * @param requestW : 缩略后最大宽度 * @param requestH : 缩略 ...
- 【statistics】理想论坛2018-4-25日统计
说明:利用理想论坛爬虫1.07版(http://www.cnblogs.com/xiandedanteng/p/8954115.html) 下载了前十页主贴及子贴,共得到359619条数据,以此数据为 ...
- ThinkPHP3.2 新bug ReadHtmlCache 支持不区分大写和小写的函数
报错提示: Fatal error: Function name must be a string in D:\wwwroot\zbphp.com\ThinkPHP\Library\Behavior\ ...
- Spring+DBUnit+H2----项目单元测试
http://yugouai.iteye.com/blog/1879337 今天够郁闷的,早上调好的代码,到中午调试不同了,分析不出问题,H2的JDBC报错:org.h2.jdbc.JdbcSQLEx ...
- Discuz常见小问题-如何修改顶部导航
1 除了主导航,我们还有一些其他的导航菜单需要设置,比如顶部导航栏,注意系统内置的最好不要修改,如果我不想显示系统内置的,则取消勾选即可.下面我自己做了两个新的顶部导航超链接,分别指向新的站外的地址. ...
- Weixin 之 微信二维码扫描下载 Apk
制作的手机 app 需要上线,生成二维码扫描进行下载,把生成好的apk挂在服务器端,将地址复制下来,通过草料二维码(http://cli.im/)生成一个二维码. 在更多中,你会看到有个app的选项, ...
- 页面载入时通过获取GridView某行某列的值来控制某一列的控件属性
通过获取状态来控制"查看"button的Visible属性值. 在前台GridView中加入 OnRowDataBound="GridView1_RowDataBound ...
- iOS 推断设备为iPhone还是iPad
if ([[UIDevice currentDevice] userInterfaceIdiom] == UIUserInterfaceIdiomPhone) { self.viewControlle ...
- 修改终端下vim的PopupMenu选种项的背景颜色
我平常比较喜欢使用终端下的 VIM,最方便的就是随时可以使用ctrl+z切换到终端下执行命令, 然后再通过fg切换回 VIM.如果再有个透明效果,那就更赞了.不过最近换了一个配色ron 后, 有个比较 ...
- 类的专有方法(__len__)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #http://www.imooc.com/code/6252 #类的专有方法(__len__) #如果一个类 ...