大数据入门:Hadoop安装、环境配置及检测
@
Hadoop所用安装包和配置文件等我找到最方便使用的方式再上传到博客,如果有需要也欢迎找我分享。
- 这篇博客是建立在我另一篇博客的基础上,建议先浏览博文
大数据入门第一篇:maven项目的搭建
在windows下,
1.导包Hadoop包
我用的是破解版的文件,不需要安装,直接解压到D盘下

2.配置环境变量
- 接下来配置环境变量,相信配置过jdk的同学们对这一步应该不算陌生。
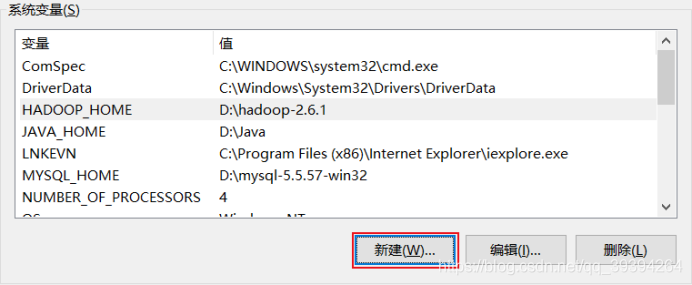
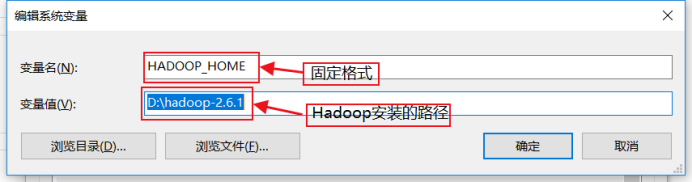
我的电脑——>属性——>高级系统设置——>环境变量——>系统变量——>编辑Path,增加 %HADOOP_HOME%\bin ——>新建一个变量名为 HADOOP_HOME,变量值为 hadoop安装路径的系统变量——>确定操作——>完成
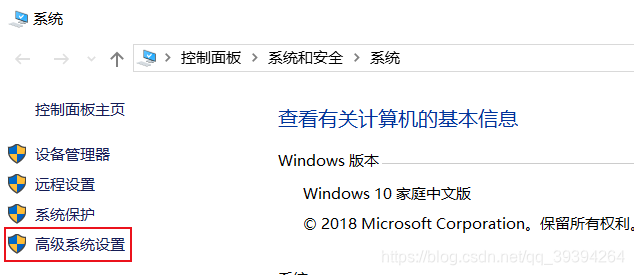
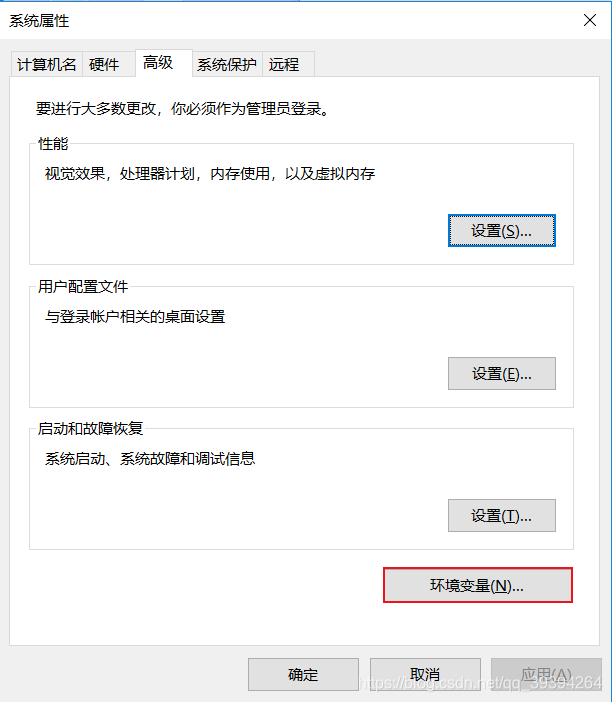
找到系统变量,编辑Path
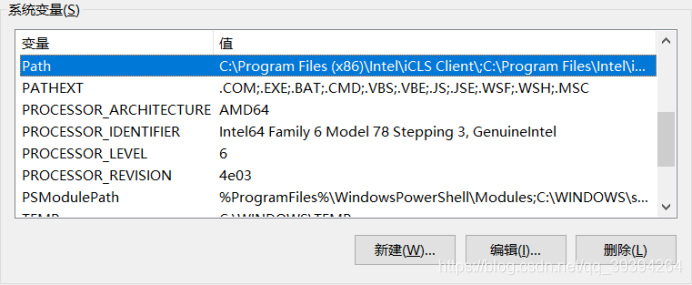
加上 %HADOOP_HOME%\bin即可
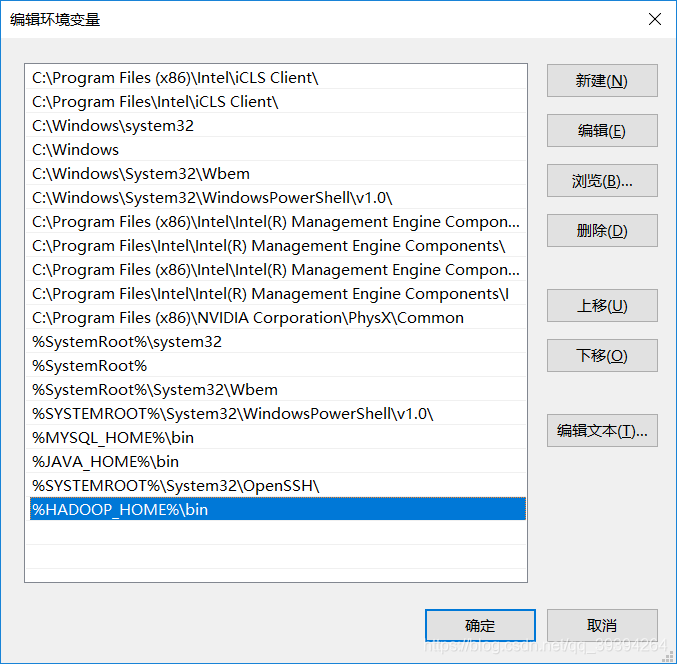
确定之后,新建一个系统变量
然后依次确定刚才的操作,配置环境变量工作完成。
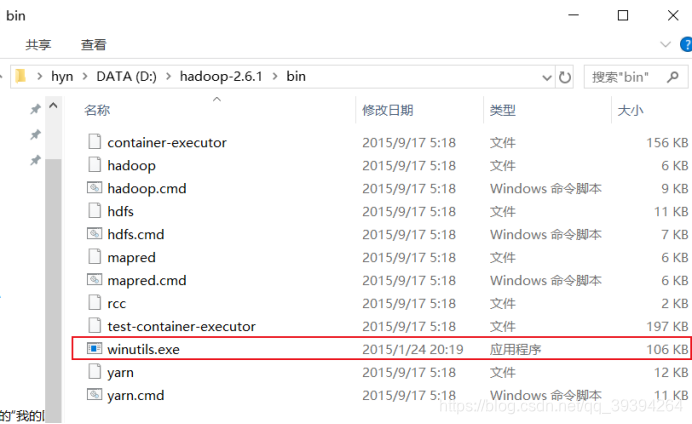
3.把winutil包拷贝到Hadoop bin目录下
4.把Hadoop.dll放到system32下
路径:C:\Windows\System32

5.检测Hadoop是否正常安装
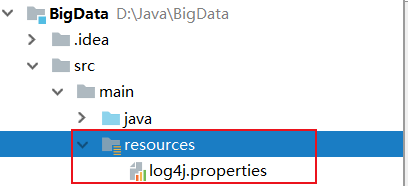
5.1在maven项目中检测,将配置文件放入resource包下
5.2然后通过一个简单的wordcount程序检测Hadoop是否安装成功
先在本地电脑写一个txt文件,内容随便输入,
如:

5.3保存好之后,写程序:
(检测这里将程序复制过去就可以,先不用理解,后续学习)
package com.oracle.demo.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split(" ");
for (String s:strs){
Text outkey = new Text(s);
IntWritable outvalue = new IntWritable(1);
context.write(outkey,outvalue);
}
}
}
public class WcReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable n:values){
count += n.get();
}
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapperClass(com.oracle.demo.mr.WcMapper.class);
job.setReducerClass(com.oracle.demo.mr.WcReduce.class);
FileInputFormat.setInputPaths(job,new Path("E:\\BigData\\input.txt"));
FileOutputFormat.setOutputPath(job,new Path("E:\\BigData\\output"));
job.waitForCompletion(true);
}
}
注意:

运行之后控制台显示:
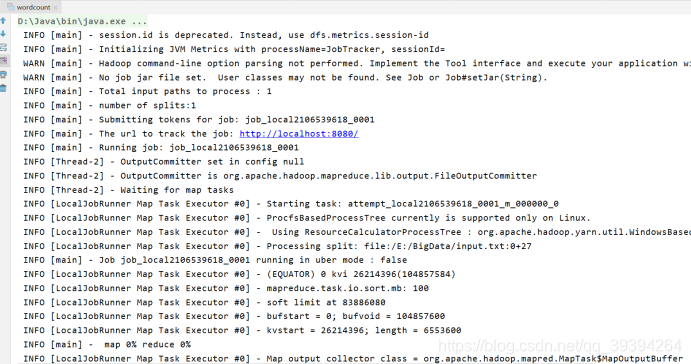
。。。
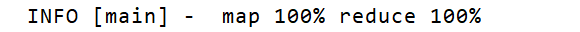
。。。

表示运行成功,没有错误
5.4最后我们打开输出文件查看:
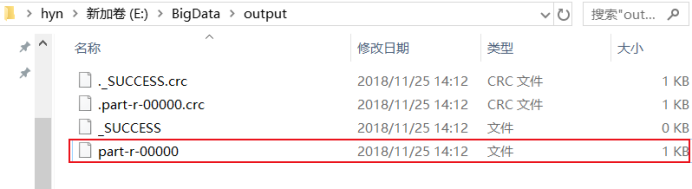
结果是:
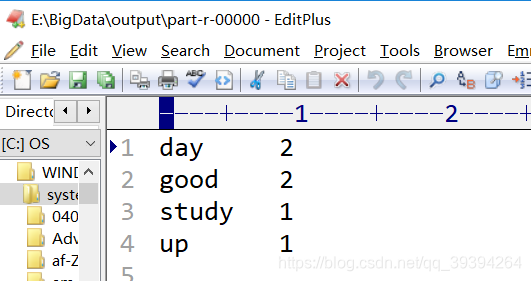
此刻,表示Hadoop安装成功,大功告成了。
6.容易出现的错误:
6.1.导包错误
6.2.输出文件存在
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/E:/BigData/output already exists
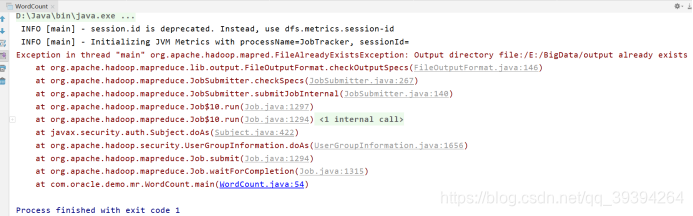
如何解决:之前运行的输出文件删除即可。
6.3.环境搭建或配置等错误

这篇博客是我自己安装完之后写出来的,如果过程中有什么疏漏或者疑问,欢迎和我交流。安装过程中也许会遇到一些自己解决不了的错误,不要急躁,慢慢找方法解决就好了,希望你能成为一个优秀的程序员。
大数据入门:Hadoop安装、环境配置及检测的更多相关文章
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据学习——hadoop安装
上传centOS6.7-hadoop-2.6.4.tar.gz 解压 tar -zxvf centOS6.7-hadoop-2.6.4.tar.gz hadoop相关修改配置 1 修改 /root/a ...
- 大数据学习之路—环境配置——IP设置(虚拟机修改Ip的内在原因及实现)
一.IP原理 关于IP我的理解, (1)主要去理解IP地址的作用,IP地址包括网络相关部分和主机的相关部分.即:用一段特殊的数据,来标识网络特征和主机的特征. 至于具体的技术实现,日后可以慢慢体会和了 ...
- 大数据学习之路——环境配置(2)——mysql 在linux 系统上安装配置
1.安装参考网址: https://blog.csdn.net/IronWring_Fly/article/details/103637801 设置新秘密: mysqladmin -u root ...
- 大数据开发keras框架环境配置小结
系统安装问题 win10+ubuntu16.04 在win10在需要security boot设置成disable,否则安装完后无法设置启动项. 安装完ubuntu重启,系统会直接进入win10,需要 ...
- 大数据之Hadoop技术入门汇总
今天,小编对Hadoop入门学习知识进行了汇总,帮助大家更好地入手大数据.小编关于Hadoop入门总共发写了12篇原创文章,文章是参照尚硅谷大数据视频教程来进行撰写的. 今天,小编带你解锁正确的阅读顺 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
随机推荐
- Pwn With longjmp
前言 这个是 seccon-ctf-quals-2016 的一个题,利用方式还是挺特殊的记录一下. 题目链接 http://t.cn/RnfeHLv 正文 首先看看程序的安全措施 haclh@ubun ...
- import依赖范围的使用
<!-- <parent> <groupId>org.springframework.boot</groupId> <artifactId>spr ...
- [翻译] OCMaskedTextField
OCMaskedTextField https://github.com/OmerCora/OCMaskedTextField Simple class to display dynamically ...
- Linux 软硬链接详解
软链接 软链接: 类似于windows的快捷方式,—>文本文件,但是包含了真实文件的地址 源文件删除,则软连接也删除 软链接可以放在任何文 ...
- 《C++ Primer Plus》读书笔记之十—类和动态内存分配
第12章 类和动态内存分配 1.不能在类声明中初始化静态成员变量,这是因为声明描述了如何分配内存,但并不分配内存.可以在类声明之外使用单独的语句进行初始化,这是因为静态类成员是单独存储的,而不是对象的 ...
- Hybris阶段总结(1)何为hybris
按照谷歌出来的结果,大体意思是“Hybris Commerce是一套完善的电子商务解决方案,基于开放标准构建,功能强大,且具有模块化的特点,旨在为满足企业的商务需求提供坚实的基础”. 当然对于我这样 ...
- spring4声明式事务—02 xml配置方式
1.配置普通的 controller,service ,dao 的bean. <!-- 配置 dao ,service --> <bean id="bookShopDao& ...
- Hadoop HBase概念学习系列之物理视图(又名为物理模型)(九)
虽然,从HBase的概念视图来看,每个表格是由很多行组成的,但是在物理存储上面,它是按照列来保存的,这一点在进行数据设计和程序开发的时候必须牢记. 在物理存储上面,它是按照列来保存的 需要注意的是,在 ...
- October 06th 2017 Week 40th Friday
The greatest ideal man can set before himself is self-perfection. 一个人最高的理想是自我完善. To be better than t ...
- ZT 查找字符串中连续最长的数字串
查找字符串中连续最长的数字串 有俩方法,1)比较好理解一些.2)晦涩 1) /* 功能:在字符串中找出连续最长的数字串,并把这个串的长度返回, 并把这个最长数字串付给其中一个函数参数outputstr ...