笔记四:python乱码深度剖析二
一:学习内容
- 获取更改系统编码
- 判断字符的编码类型
- 文件存储和读取的编码
二:获取更改系统编码
1. 获取系统编码
import sys
print sys.getdefaultencoding()

2. 更改系统编码
#encoding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('UTF-8')
print 1,sys.getdefaultencoding()
print 2,type(u"我")
print 3,type("我")
print 4,u"我"
print 5,"我"
print 6,u"我".encode('utf-8')
print 7,u"我".decode('utf-8')
print 8,"我".encode('utf-8').decode('utf-8')
print 9,"我".decode('utf-8').encode('gbk')
print 10,"我".encode('gbk')
运行结果为:

问题一:为什么要reload sys模块
在site.py文件里有这么一段代码:
if hasattr(sys, "setdefaultencoding"):
del sys.setdefaultencoding
在sys加载后,setdefaultencoding方法被删除了,所以我们要通过重新导入sys来设置系统编码。
问题二:为什么print 4,u"我"可以打印正常,print 5,"我"打印乱码
字符串的打印,python的逻辑为:如果是unicode字符串,则可以自动编码为终端所用编码,然后正确显示出来。所以u"我"实际上将"我"进行了decode成了unicode字符,然后python将unicode字符串自动化编码为gbk(我的cmd的编码)

而print 5,”我”,字符串编码为utf-8类型(文件保存的类型),输出到cmd为gbk类型的终端上,则无法显示。
问题三:为什么print 8,"我".encode('utf-8').decode('utf-8')可以打印正常,print 6,u"我".encode('utf-8')打印乱码
因为我是str类型,在encode前,python自动会用默认编码(setdefaultencoding)进行decode为unicode类型,但是如果默认编码为ascii,是不支持decode的。

可以看到文件里修改了默认编码为utf-8,所以"我".encode('utf-8').decode('utf-8')这句首先会decode('utf-8')为unicode类型,然后在encode('utf-8').decode('utf-8'),此时”我”已经变成了unicode类型,如果是unicode字符串,则可以自动编码为终端所用编码(这是问题一中提到的),这样就能输出到cmd终端了。
然后我们再说为什么print 6,u"我".encode('utf-8')会乱码呢,上面已经讲了在encode('utf-8')之前会decode('utf-8')为unicode类型,然后在执行.encode('utf-8'),此时”我”会被编码成utf-8,然后print输出到cmd的gbk终端,由于编码不统一,就会乱码。
三:判断字符的编码类型
1. chardet.detect(字符内容)
#encoding=utf-8
import chardet
import urllib
TestData = urllib.urlopen('http://www.baidu.com/').read()
print chardet.detect(TestData)

发现打印的字符编码类型为utf-8。
2. import chardet如果报错ImportError: No Module named chardet,则需要下载安装该模块,步骤为:
第一步:在https://pypi.python.org/pypi/chardet#downloads下载chardet-2.1.1.tar.gz

第二步:解压 chardet-2.1.1.tar.gz文件到\Lib\site-packages下
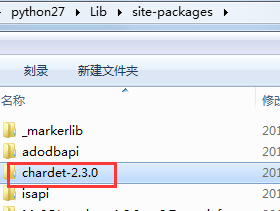
第三步:安装 chardet模块,进入到python的\Lib\site-packages\chardet-2.3.0路径下,执行python setup.py install

这样就完成chardet模块安装了,此时你可以在去运行上面的文件。
四:文件存储和读取的编码
1. 计算机内存中,统一使用unicode编码,当需要保存到硬盘或需要传输的时候,就转换为UTF-8编码
2. 用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把unicode转换为UTF-8保存到文件

3. 浏览网页的时候,服务器会把动态生成的unicode内容转换为UTF-8在传输到浏览器
很多网页源码上会有类似<meta charset='utf-8'/>的信息,表示该网页正是用的UTF-8编码
小记:
a. 在utf-8文件中,则这个字符串就是utf-8编码的,它的编码取决与当前的文本编码。
b. GB2312文本的编码就是GB2312。
c. 在同一个文本中进行两种编码的输出等操作就必须进行编码的转换,先用decode将文本原来的编码转换成unicode,再用encode将编码转换成需要转换成的编码。
d. 实例练习:
手工创建一个文件如a.txt,以ansi编码保存即gbk,然后取出数据变成utf-8编码保存到b.txt文件中,查看b.txt文件编码为utf-8
#encoding=utf-8
f=open('C:\\Users\\yumeiling\\Desktop\\a.txt','r')
data=f.read()
temp = data.decode('gbk')
f.close()
f=open('C:\\Users\\yumeiling\\Desktop\\b.txt','w')
temps=temp.encode('utf-8')
f.write(temps) #写入utf-8字符,并进行保存
f.close()
运行结果为:查看b.txt文件
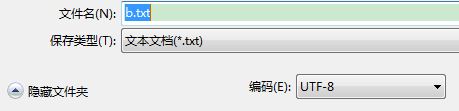
这样执行后,发现生成了b.txt文件,文件的编码为改成了utf-8编码。
笔记四:python乱码深度剖析二的更多相关文章
- 笔记三:python乱码深度剖析一
一:学习内容 python编码转换 python乱码原因深入解析 二:python编码转换 1. Python内部字符串一般都是Unicode编码,代码中字符串的默认编码与代码文件本身的编码是一致的. ...
- libevent源码深度剖析二
libevent源码深度剖析二 ——Reactor模式 张亮 前面讲到,整个libevent本身就是一个Reactor,因此本节将专门对Reactor模式进行必要的介绍,并列出libevnet中的几个 ...
- libevent学习笔记(参考libevent深度剖析)
最近自学libevent事件驱动库,参考的资料为libevent2.2版本以及张亮提供的<Libevent源码深度剖析>, 参考资料: http://blog.csdn.net/spark ...
- [Android] Toast问题深度剖析(二)
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 作者: QQ音乐技术团队 题记 Toast 作为 Android 系统中最常用的类之一,由于其方便的api设计和简洁的交互体验,被我们所广泛采用 ...
- Python学习笔记(四)Python函数的参数
Python的函数除了正常使用的必选参数外,还可以使用默认参数.可变参数和关键字参数. 默认参数 基本使用 默认参数就是可以给特定的参数设置一个默认值,调用函数时,有默认值得参数可以不进行赋值,如: ...
- Django深度剖析-二
WEBserver处理过程 先写个大家熟悉的socketserver例子 #! /usr/bin/env python # encoding: utf-8 """ @Au ...
- ASP.NET乱码深度剖析
写在前面 在Web开发中,乱码应该算一个常客了.今天还好好的一个页面,第二天过来打开一看,中文字符全变“外星文”了.有时为了解决这样的问题,需要花上很长的时间去调试,直至抓狂,笔者也曾经历过这样的时期 ...
- python笔记 利用python 自动生成条形码 二维码
1. ean13标准条形码 from pystrich.ean13 import EAN13Encoder encode = EAN13Encoder(') encode.save('d:/barco ...
- 学习笔记之Python人机交互小项目二:名片管理系统
继上次利用列表相关知识做了简单的人机交互的小项目名字管理系统后,当学习到字典时,老师又让我们结合列表和字典的知识,结合一起做一个名片管理系统,这里分享给在学习Python的伙伴! 1.不使用函数 1 ...
随机推荐
- Python学习-37.Python中的正则表达式
作为一门现代语言,正则表达式是必不可缺的,在Python中,正则表达式位于re模块. import re 这里不说正则表达式怎样去匹配,例如\d代表数字,^代表开头(也代表非,例如^a-z则不匹配任何 ...
- grunt管理js/css
1.安装node 2.npm安装 3.运行grunt,可能遇到下面的问题 可以运行npm install -g grunt 然后再运行grunt 可以看到已经压缩成功了:
- Backup--还原选项之STANDBY
很多DBA对还原时制定RECOVERY 与 NORECOVERY选项都很熟悉,但是对于STANDBY就有点茫然了,今天一起来学习下吧. --============================== ...
- ClsoSee(v2) Alpha测试中!这是一个临时的帮助页面...
Clso See 测试中,最新的更新信息会显示在这里,欢迎您随时关注新版本动态. 您可以单击这里让程序打开本地帮助文件(新说明.txt) 等程序完成后,会制作专门的帮助页面. 因为采用了键盘Hook技 ...
- telerik:RadGrid 表格中删除数据
<telerik:RadGrid OnItemCommand=" Height="490px" Culture="zh-CN" CssClass ...
- delete job definition
$badjobTake2 = Get-SPTimerJob -ID "job-service-instance-f2de35ab-bca3-4e53-b51a-98d3b06a6930&qu ...
- app开发技术调研
l 面向消费者与公众的应用系统,主要分为3种主流的渠道: 1. web应用 2. 基于腾讯微信开放api构建的微信app 3. 移动端app ll 在移动端app方面,通过调研,现主流的 ...
- scapy IPv6 NS NA报文构造
NS 报文构造: #! /bin/python from scapy.all import * a=IPv6(src='2a01:4f8:161:5300::40', dst='ff02::1:ff0 ...
- python 带参与不带参装饰器的使用与流程分析/什么是装饰器/装饰器使用注意事项
一.什么是装饰器 装饰器是用来给函数动态的添加功能的一种技术,属于一种语法糖.通俗一点讲就是:在不会影响原有函数的功能基础上,在原有函数的执行过程中额外的添加上另外一段处理逻辑 二.装饰器功能实现的技 ...
- Topological Sor-207. Course Schedule
There are a total of n courses you have to take, labeled from 0 to n - 1. Some courses may have prer ...