对HashMap的理解(一):HashMap的实现
一、HashMap介绍
1. 定义
HashMap实现了Map接口,继承AbstractMap类。其中Map接口定义了键映射到值的规则,而AbstractMap类提供 Map 接口的骨干实现,以最大限度地减少实现此接口所需的工作,其实AbstractMap类已经实现了Map
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
2. 成员变量
transient Node<K,V>[] table; //HashMap的哈希桶数组,非常重要的存储结构,用于存放表示键值对数据的Node元素。 transient Set<Map.Entry<K,V>> entrySet; //HashMap将数据转换成set的另一种存储形式,这个变量主要用于迭代功能。 transient int size; //HashMap中实际存在的Node数量,注意这个数量不等于table的长度,甚至可能大于它,因为在table的每个节点上是一个链表(或RBT)结构,可能不止有一个Node元素存在。 transient int modCount; //HashMap的数据被修改的次数,这个变量用于迭代过程中的Fail-Fast机制,其存在的意义在于保证发生了线程安全问题时,能及时的发现(操作前备份的count和当前modCount不相等)并抛出异常终止操作。 int threshold; //HashMap的扩容阈值,在HashMap中存储的Node键值对超过这个数量时,自动扩容容量为原来的二倍。 final float loadFactor; //HashMap的负载因子,可计算出当前table长度下的扩容阈值:threshold = loadFactor * table.length。
table是哈希桶数组,存放键值对的Node,size表示hashmap中实际存放的Node数量(size大于等于table.length,因为table的每个节点是一个链表或红黑树)
threshold是hashmap的扩容阈值(threshold = table.length * loadFactor),当hashmap中存储的Node数量(size)超过threshold时,自动扩容为原来的两倍
loadFactor是hashmap的负载因子,默认值为0.75f
3. 默认值
//默认的初始容量为16,必须是2的幂次
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //最大容量即2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30; //默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f; //当put一个元素时,其链表长度达到8时将链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8; //链表长度小于6时,解散红黑树
static final int UNTREEIFY_THRESHOLD = 6; //默认的最小的扩容量64,为避免重新扩容冲突,至少为4 * TREEIFY_THRESHOLD=32,即默认初始容量的2倍
static final int MIN_TREEIFY_CAPACITY = 64;
4. 构造函数
HashMap共有4个构造函数,如下:
// 默认构造函数。
HashMap() // 指定“容量大小”的构造函数
HashMap(int capacity) // 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor) // 包含“子Map”的构造函数
HashMap(Map<? extends K, ? extends V> map)
实现:
package java.util;
import java.io.*; public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{ // 默认的初始容量是16,必须是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16; // 最大容量(必须是2的幂且小于2的30次方,传入容量过大将被这个值替换)
static final int MAXIMUM_CAPACITY = 1 << 30; // 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 存储数据的Entry数组,长度是2的幂。
// HashMap是采用拉链法实现的,每一个Entry本质上是一个单向链表
// table就是HashMap的存储结构,显然这是一个数组,数组的每一个元素都是一个条目(Entry),Entry是HashMap中的一个内部类,它有如下4个属性:final K key;V value;Entry<K,V> next;final int hash。分别为键、值、指向下一个链表结点的指针、散列(哈希)值。
transient Entry<K,V>[] table; //Node<K,V>[] // HashMap的大小,它是HashMap保存的键值对的数量
transient int size; // HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子)
int threshold; // 加载因子实际大小
final float loadFactor; // HashMap被改变的次数
transient volatile int modCount; // 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// HashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor); // 找出“大于initialCapacity”的最小的2的幂
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1; // 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
init();
} // 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
} // 默认构造函数。
public HashMap() {
// 设置“加载因子”
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
} // 包含“子Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}
HashMap的构造函数主要有两个参数:初始容量,加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中桶的数量,初始容量是创建哈希表时的容量,加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。系统默认负载因子为0.75,一般情况下我们是无需修改的。
二、HashMap数据结构
HashMap采取 数组 + 链表 + 红黑树 的存储方式来实现。即数组(散列桶)中的每一个元素都是链表,如下图:
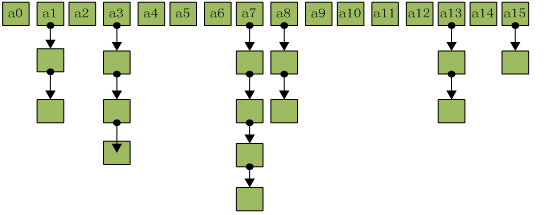
可以看出HashMap底层实现还是数组,只是数组的每一项都是一条链。通过数组来存放链表的第一个节点。其中参数initialCapacity就代表了该数组的长度。
更清晰的图:
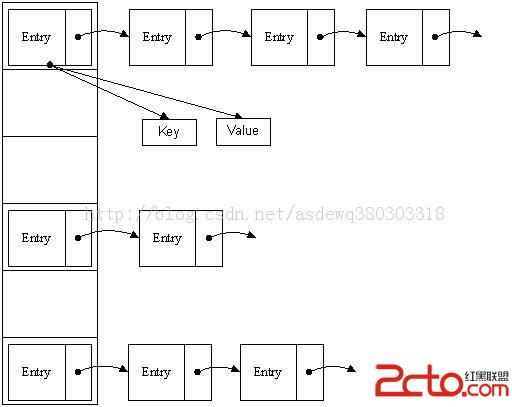
三、put方法
put方法的源码:
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());------------------------(1)
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length);-------------------(2)
//从i处开始迭代 e,找到 key 保存的位置(迭代处)
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
} // 若“该key”对应的键值对不存在,则将“key-value”添加到table中
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
} void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}
HashMap保存数据的过程:
1. 判断key是否为null,若为null,则hash = 0。所以key=null总是存放在table[]数组的第一个元素。
2. 若key不为空,则先计算key的hash值,然后根据hash值判断在table数组中的索引位置
(1). 若table数组在该位置处有元素,则比较是否存在相同的key
a. 若存在则覆盖原来key的value;
b. 若不存在
I. p为链表节点,则将该节点保存在链头(最先添加的节点在链尾)
II. p为链表节点但长度为临界长度 - 1,插入成功后就要转换成红黑树
III. p为红黑树节点,则将该节点插入红黑树
(2). 若table数组在该位置处没有元素,则调用addEntry()方法直接添加。
关于addEntry()方法:
系统总是将新的Entry对象添加到bucketIndex处(第33行)。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链(第36行),
但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。
put()方法这里有两点注意;
1. 先看迭代处。此处迭代原因就是为了防止存在相同的key值,若发现两个hash值(key)相同时,HashMap的处理方式是用新value替换旧value,这里并没有处理key,这就解释了HashMap中没有两个相同的key。
2. 再看(1)、(2)处。这里是HashMap的精华所在。计算下标的过程,主要分三个阶段:计算hashcode、高位运算和取模运算。
首先是hash方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里通过key.hashCode()计算出key的哈希值,然后将哈希值h右移16位,再与原来的h做异或^运算——这一步是高位运算。设想一下,如果没有高位运算,那么hash值将是一个int型的32位数。而从2的-31次幂到2的31次幂之间,有将近几十亿的空间,如果我们的HashMap的table有这么长,内存早就爆了。所以这个散列值不能直接用来最终的取模运算,而需要先加入高位运算,将高16位和低16位的信息"融合"到一起,也称为"扰动函数"。这样才能保证hash值所有位的数值特征都保存下来而没有遗漏,从而使映射结果尽可能的松散。
最后,对于HashMap的table而言,数据分布需要均匀(最好每项都只有一个元素,这样就可以直接找到),不能太紧也不能太松,太紧会导致查询速度慢,太松则浪费空间。计算hash值后,怎么才能保证table元素分布均与呢?我们会想到取模,但是由于取模的消耗较大,HashMap是这样处理的:
根据 n-1 做与操作的取模运算。这里也能看出为什么HashMap要限制table的长度为2的n次幂,因为这样,n-1可以保证二进制展示形式是(以16为例)0000 0000 0000 0000 0000 0000 0000 1111。在做"与"操作时,就等同于截取hash二进制值得后四位数据作为下标。这里也可以看出"扰动函数"的重要性了,如果高位不参与运算,那么高16位的hash特征几乎永远得不到展现,发生hash碰撞的几率就会增大,从而影响性能。
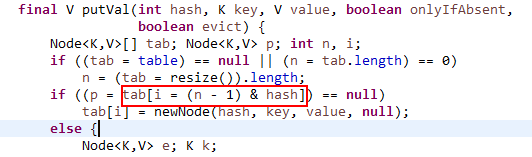
在构造函数中存在:capacity <<= 1;这样做总是能够保证HashMap的底层数组长度为2的n次方。当length为2的n次方时,h&(length - 1)就相当于对length取模,而且速度比直接取模快得多,这是HashMap在速度上的一个优化。
对于indexFor方法,该方法仅有一条语句:h&(length - 1),这句话除了上面的取模运算外还有一个非常重要的责任:均匀分布table数据和充分利用空间。
这里我们假设length为16(2^n)和15,hash为5、6、7。
|
length = 16 |
||||
|
h |
length – 1 |
h & (length – 1) |
h&(length–1) 对应十进制 |
Mod(h,length – 1) |
|
5 |
15 |
0101 & 1111 = 00101 |
5 |
5 |
|
6 |
15 |
0110 & 1111 = 00110 |
6 |
6 |
|
7 |
15 |
0111 & 1111 = 00111 |
7 |
7 |
|
length = 15 |
||||
|
5 |
14 |
0101 & 1110 = 00100 |
4 |
5 |
|
6 |
14 |
0110 & 1110 = 00110 |
6 |
6 |
|
7 |
14 |
0111 & 1110 = 00110 |
6 |
7 |
可以看出,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。当n=15时,6和7的结果一样,这样表示他们在table存储的位置是相同的,也就是产生了碰撞,6、7就会在一个位置形成链表,这样就会导致查询速度降低。下面看hash为0-15的情况。
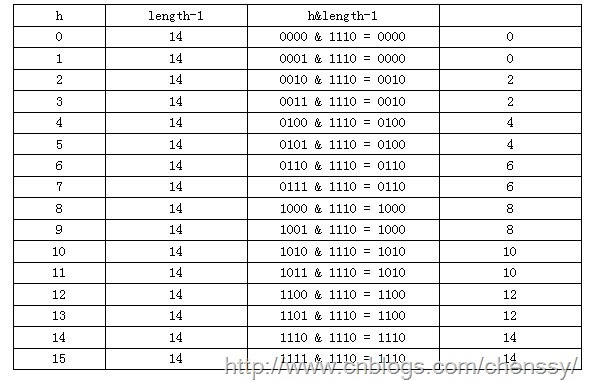
从上面的图表中我们看到总共发生了8此碰撞,同时发现浪费的空间非常大,有1、3、5、7、9、11、13、15处没有记录,也就是没有存放数据。这是因为他们在与14进行&运算时,得到的结果最后一位永远都是0,即0001、0011、0101、0111、1001、1011、1101、1111位置处是不可能存储数据的,空间减少,进一步增加碰撞几率,这样就会导致查询速度慢。而当length = 16时,length – 1 = 15 即1111,那么进行低位&运算时,值总是与原来hash值相同,而进行高位运算时,其值等于其低位值。所以说当length = 2^n时,不同的hash值发生碰撞的概率比较小,这样就会使得数据在table数组中分布较均匀,查询速度也较快。
总结put的流程:当我们想一个HashMap中添加一对key-value时,系统会首先计算key的hash值 [ hash(int h)方法 ],然后根据hash值确认在table中存储的位置 [ indexFor(int h, int length) 方法 ]。若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。如果两个hash值相等且key值相等,则用新的Entry的value覆盖原来节点的value。如果两个hash值相等但key值不等 ,则将该节点插入该链表的链头。
四、get方法
通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可。
public V get(Object key) {
// 若为null,调用getForNullKey方法返回相对应的value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 取出 table 数组中指定索引处的值
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
//若搜索的key与查找的key相同,则返回相对应的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
在这里能够根据key快速的取到value除了和HashMap的数据结构密不可分外,还和Entry有莫大的关系,在前面就提到过,HashMap在存储过程中并没有将key,value分开来存储,而是当做一个整体key-value来处理的,这个整体就是Entry对象。同时value也只相当于key的附属而已。在存储的过程中,系统根据key的hashcode来决定Entry在table数组中的存储位置,在取的过程中同样根据key的hashcode取出相对应的Entry对象。
参考:
java提高篇(二三)-----HashMap
Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
漫画:什么是HashMap?
java 8 Hashmap深入解析 —— put get 方法源码
对HashMap的理解(一):HashMap的实现的更多相关文章
- 关于java集合类HashMap的理解
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- 轻松理解 Java HashMap 和 ConcurrentHashMap
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- 对HashMap的理解(三):ConcurrentHashMap
HashMap不是线程安全的.在并发插入元素的时候,有可能出现环链表,让下一次读操作出现死循环.避免HashMap的线程安全问题有很多方法,比如改用HashTable或Collections.sync ...
- 【大厂面试08期】谈一谈你对HashMap的理解?
摘要 HashMap的原理也是大厂面试中经常会涉及的问题,同时也是工作中常用到的Java容器,本文主要通过对以下问题进行分析讲解,来帮助大家理解HashMap的原理. 1.HashMap添加一个键值对 ...
- <<< List<HashMap<String, Object>> 及 HashMap<String, Object> 的用法
//(赋值)最简单的一种hashMap赋值方式 List<HashMap<String, Object>> aMap= new ArrayList<HashMap< ...
- HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别
①HashMap的工作原理 HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象.当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算h ...
- (转)HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别
①HashMap的工作原理 HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象.当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算h ...
- HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别(转)
HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别 文章来源:http://www.cnblogs.com/beatIteWeNerverGiveU ...
- 关于hashmap的理解
首先分析第一个比较重要的方法 put 方法,源码如下 public V put(K key, V value) { if (key == null) return putForNullKey(valu ...
随机推荐
- 中间介(MiddleWare)
引子-Django的生命周期 在学习中间介之前,我们先来回顾一下Django的生命周期:用户发起请求,请求会被发送到urlconf中的url,然后会指向对应的views函数进行处理,views函数处理 ...
- Python 从零搭建 Conf_Web 配置管理平台
作者:Eagle 某船舶行业科技公司,运维工程师,51Reboot学员.通过在51Reboot学习,由运维工程师转至运维开发工程师.完成公司自动化平台的构建,对运维开发有了自己的理解,空闲时间写了这么 ...
- Kali Linux菜单中各工具功能大全
各工具kali官方简介(竖排):https://tools.kali.org/tools-listing 名称 类型 使用模式 功能 功能评价 dmitry 信息收集 whois查询/子域名收集/ ...
- 经典笔试题:用C写一个函数测试当前机器大小端模式
“用C语言写一个函数测试当前机器的大小端模式”是一个经典的笔试题,如下使用两种方式进行解答: 1. 用union来测试机器的大小端 #include <stdio.h> union tes ...
- Http protocal
https://tools.ietf.org/html/rfc2616 1. 状态码:status code 1xxx:信息--请求被接收,继续下一步处理 2xxx:成功--请求行为被 ...
- Keycloak服务器安装和配置
安装地址:https://www.keycloak.org/archive/downloads-4.4.0.html 参考文档:https://www.keycloak.org/docs/latest ...
- Gitlab CI-3.遇到的问题
五.遇到的问题 1. cannot validate certificate for x.x.x.x because it doesn't contain any IP SANs 报错信息:ERROR ...
- Centos7下使用RDO方式安装openstack-r版
一.前言 OpenStack是一个开源的云计算管理平台项目,OpenStack支持几乎所有类型的云环境,项目目标是提供实施简单.可大规模扩展.丰富.标准统一的云计算管理平台.OpenStack通过各种 ...
- nice和renice命令详解
基础命令学习目录首页 进程调度是linux中非常重要的概念.linux内核有一套高效复杂的调度机制,能使效率极大化,但有时为了实现特定的要求,需要一定的人工干预.比如,你希望操作系统能分配更多的CPU ...
- MyForm_参考django的Form组建
fork wupeiqi:https://github.com/fat39/Tyrion 组件说明:https://www.cnblogs.com/wupeiqi/p/5938916.html