Ceph实现数据的'不拆分'
前言
之前看过一个朋友一篇文章,讲述的是Vsan为什么使用的是两副本,而ceph则大多数情况下需要三副本,当时个人观点是这个并不是关键点,但是在仔细考虑了问题的出发点以后,这个也可以说是其中的一个点
一个集群数据丢失可以从多方面去看
- 发生丢失数据的事件,这个来说,出现这个事件的概率是一致的,同等硬件情况下没有谁的系统能够说在两副本情况下把这个出现坏盘概率做的比其他系统更低
- 发生坏盘事件以后,数据丢失波及的范围,这个就是那个朋友提出的一个观点,对于Vsan来说因为文件的不拆分,也就是在丢了的情况下,只是局部数据的丢失,而ceph的数据因为拆分到整个集群,基本上说就是全军覆没了,这一点没有什么争议
一般来说,ceph都是配置的分布式文件系统,也就是数据以PG为组合,以对象为最小单元的形式分布到整个集群当中去,通过控制crush能够增加一定的可用概率,但是有没有办法实现真的丢盘的情况下,数据波及没有那么广,答案当然是有的,只是需要做一些更细微的控制,前端的使用的接口也需要做一定的改动,本篇将讲述这个如何去实现,以及前端可能需要的变动
方案实现
首先来一张示意图,来介绍大致的实现方式,下面再给出操作步骤
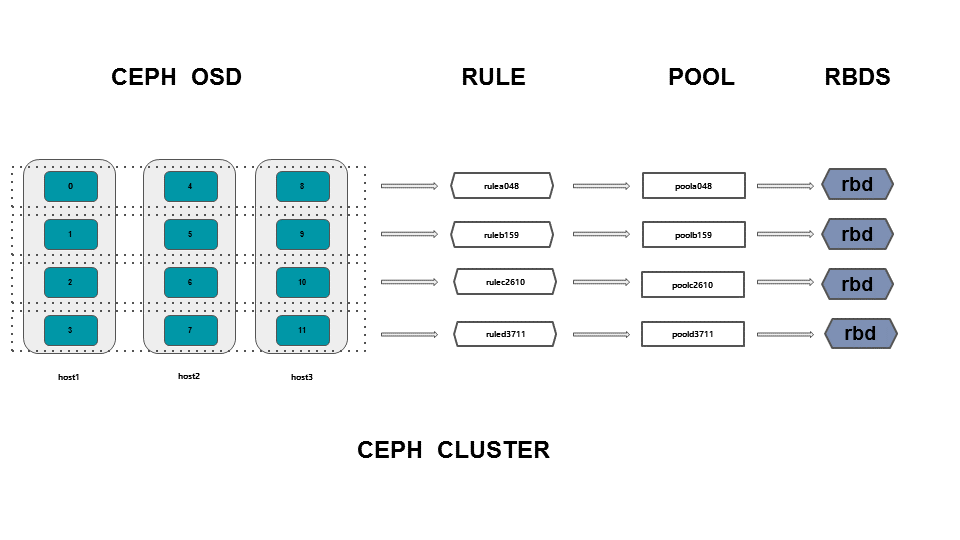
主要包括三步
- 横向划条带
- 创建对应规则
- 根据规则创建相关存储池
横向划条带
创建虚拟根
ceph osd crush add-bucket default-a root
ceph osd crush add-bucket default-b root
ceph osd crush add-bucket default-c root
ceph osd crush add-bucket default-d root
创建虚拟主机
ceph osd crush add-bucket host1-a host
ceph osd crush add-bucket host2-a host
ceph osd crush add-bucket host3-a host
ceph osd crush add-bucket host1-b host
ceph osd crush add-bucket host2-b host
ceph osd crush add-bucket host3-b host
ceph osd crush add-bucket host1-c host
ceph osd crush add-bucket host2-c host
ceph osd crush add-bucket host3-c host
ceph osd crush add-bucket host1-d host
ceph osd crush add-bucket host2-d host
ceph osd crush add-bucket host3-d host
将虚拟主机挪到虚拟根里面
ceph osd crush move host1-a root=default-a
ceph osd crush move host2-a root=default-a
ceph osd crush move host3-a root=default-a
ceph osd crush move host1-b root=default-b
ceph osd crush move host2-b root=default-b
ceph osd crush move host3-b root=default-b
ceph osd crush move host1-c root=default-c
ceph osd crush move host2-c root=default-c
ceph osd crush move host3-c root=default-c
ceph osd crush move host1-d root=default-d
ceph osd crush move host2-d root=default-d
ceph osd crush move host3-d root=default-d
将osd塞入到指定的bucker内
ceph osd crush create-or-move osd.0 1.83 host=host1-a
ceph osd crush create-or-move osd.4 1.83 host=host2-a
ceph osd crush create-or-move osd.8 1.83 host=host3-a
ceph osd crush create-or-move osd.1 1.83 host=host1-b
ceph osd crush create-or-move osd.5 1.83 host=host2-b
ceph osd crush create-or-move osd.9 1.83 host=host3-b
ceph osd crush create-or-move osd.2 1.83 host=host1-c
ceph osd crush create-or-move osd.6 1.83 host=host2-c
ceph osd crush create-or-move osd.10 1.83 host=host3-c
ceph osd crush create-or-move osd.3 1.83 host=host1-d
ceph osd crush create-or-move osd.7 1.83 host=host2-d
ceph osd crush create-or-move osd.11 1.83 host=host3-d
以上的这么多的操作可以用比较简单的命令实现
ceph osd crush set osd.0 1.83 host=host1-a root=default-a
ceph osd crush set osd.1 1.83 host=host1-b root=default-b
ceph osd crush set osd.2 1.83 host=host1-c root=default-c
ceph osd crush set osd.3 1.83 host=host1-d root=default-d
ceph osd crush set osd.4 1.83 host=host2-a root=default-a
ceph osd crush set osd.5 1.83 host=host2-b root=default-b
ceph osd crush set osd.6 1.83 host=host2-c root=default-c
ceph osd crush set osd.7 1.83 host=host2-d root=default-d
ceph osd crush set osd.8 1.83 host=host3-a root=default-a
ceph osd crush set osd.9 1.83 host=host3-b root=default-b
ceph osd crush set osd.10 1.83 host=host3-c root=default-c
ceph osd crush set osd.11 1.83 host=host3-d root=default-d
查看现在的树
[root@host1 ceph]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-8 5.44080 root default-d
-18 1.81360 host host1-d
3 1.81360 osd.3 up 1.00000 1.00000
-19 1.81360 host host2-d
7 1.81360 osd.7 up 1.00000 1.00000
-20 1.81360 host host3-d
11 1.81360 osd.11 up 1.00000 1.00000
-7 5.44080 root default-c
-15 1.81360 host host1-c
2 1.81360 osd.2 up 1.00000 1.00000
-16 1.81360 host host2-c
6 1.81360 osd.6 up 1.00000 1.00000
-17 1.81360 host host3-c
10 1.81360 osd.10 up 1.00000 1.00000
-6 5.44080 root default-b
-12 1.81360 host host1-b
1 1.81360 osd.1 up 1.00000 1.00000
-13 1.81360 host host2-b
5 1.81360 osd.5 up 1.00000 1.00000
-14 1.81360 host host3-b
9 1.81360 osd.9 up 1.00000 1.00000
-5 5.44080 root default-a
-9 1.81360 host host1-a
0 1.81360 osd.0 up 1.00000 1.00000
-10 1.81360 host host2-a
4 1.81360 osd.4 up 1.00000 1.00000
-11 1.81360 host host3-a
8 1.81360 osd.8 up 1.00000 1.00000
-1 0 root default
-2 0 host host1
-3 0 host host2
-4 0 host host3
下面老的一些bucket可以清理掉
ceph osd pool delete rbd rbd --yes-i-really-really-mean-it
ceph osd crush rule rm replicated_ruleset
ceph osd crush remove host1
ceph osd crush remove host2
ceph osd crush remove host3
ceph osd crush remove default
创建对应规则
ceph osd crush rule create-simple rule048 default-a host
ceph osd crush rule create-simple rule159 default-b host
ceph osd crush rule create-simple rule2610 default-c host
ceph osd crush rule create-simple rule3711 default-d host
检查下规则
[root@host1 ceph]# ceph osd crush rule dump|grep "rule_name\|item_name"
"rule_name": "rule048",
"item_name": "default-a"
"rule_name": "rule159",
"item_name": "default-b"
"rule_name": "rule2610",
"item_name": "default-c"
"rule_name": "rule3711",
"item_name": "default-d"
根据规则创建相关存储池
[root@host1 ceph]# ceph osd pool create poola048 64 64 replicated rule048
pool 'poola048' created
[root@host1 ceph]# ceph osd pool create poolb159 64 64 replicated rule159
pool 'poolb159' created
[root@host1 ceph]# ceph osd pool create poolc2610 64 64 replicated rule2610
pool 'poolc2610' created
[root@host1 ceph]# ceph osd pool create poold3711 64 64 replicated rule3711
pool 'poold3711' created
检查存储池
[root@host1 ceph]# ceph osd dump|grep pool
pool 1 'poola048' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 145 flags hashpspool stripe_width 0
pool 2 'poolb159' replicated size 2 min_size 1 crush_ruleset 1 object_hash rjenkins pg_num 64 pgp_num 64 last_change 147 flags hashpspool stripe_width 0
pool 3 'poolc2610' replicated size 2 min_size 1 crush_ruleset 2 object_hash rjenkins pg_num 64 pgp_num 64 last_change 149 flags hashpspool stripe_width 0
pool 4 'poold3711' replicated size 2 min_size 1 crush_ruleset 3 object_hash rjenkins pg_num 64 pgp_num 64 last_change 151 flags hashpspool stripe_width 0
到这里基本的环境就配置好了,采用的是副本2,但是虚拟组里面留了三个osd,这个后面会解释
如何使用
假设现在前端需要8个image用来使用了,那么我们创建的时候,就将这个8个平均分布到上面的四个存储里面去,这里是因为是划成了四个条带,在实际环境当中,可以根据需要进行划分,在选择用哪个存储的时候可以去用轮询的算法,进行轮询,也可以自定义去选择在哪个存储池创建,这个都是可以控制的
创建image
rbd -p poola048 create image1 --size 1G
rbd -p poola048 create image2 --size 1G
rbd -p poolb159 create image3 --size 1G
rbd -p poolb159 create image4 --size 1G
rbd -p poolc2610 create image6 --size 1G
rbd -p poolc2610 create image7 --size 1G
rbd -p poold3711 create image8 --size 1G
rbd -p poold3711 create image9 --size 1G
如何跟virsh对接
如果你熟悉virsh配置文件的话,可以看到rbd相关的配置文件是这样的
<source protocol='rbd' name='volumes/volume-f20fd994-e600-41da-a6d8-6e216044dbb1'>
<host name='192.168.10.4' port='6789'/>
</source>
在cinder的相关配置当中虽然我们指定了volume这个存储池值是一个定值,在这个配置文件当中也就读取了这个值,那么需要改造的接口就是在创建云盘的时候,不去将cinder的存储池固定死,volumes/volume-f20fd994-e600-41da-a6d8-6e216044dbb1这样的值可以是上面的poola048/image1,也可以是poolc2610/image6,这个地方就是需要改动的地方,将整个值包含存储池的值作为一个变量,这个改动应该属于可改的
分析
按上面的进行处理以后,那么再出现同时坏了两个盘的情况下,数据丢失的波及范围跟Vsan已经是一致了,因为数据打散也只是在这个三个里面打散了,真的出现磁盘损坏波及的也是局部的数据了
问题:
1、分布范围小了性能怎么样
比完全分布来说性能肯定降低了一些,但是如果说对于负载比较高的情况,每个盘都在跑的情况下,这个性能是一定的,底层的磁盘提供的带宽是一定的,这个跟VSAN一样的
并且这个上面所示的是极端的情况下的,缩小到3个OSD一组条带,也可以自行放宽到6个一个条带,这个只是提供了一种方法,缩小了波及范围
2、副本2为什么留3个osd一个条带
比副本数多1的话,这样在坏了一个盘也可以迁移,所以一般来说,至少比副本数多1的故障域
3、如何扩容
扩容就增加条带即可,并且可以把老的存储池规则指定到新的磁盘的条带上面
4、这个方法还可以用故障域增加可用性么
可以的,可以从每个故障域里面抽出OSD即可,只要保证底层的数据不重叠,实际是两个不同的需求
总结
本篇是提供了一种可能性,在实际运行环境当中,可以根据自己的环境进行设计,设计的方法就是,假设一个数据的全部副本都丢了的情况,允许的数据波及范围是多少,如果拆分两份就是波及二分之一,我的测试环境是分成了四个条带,也就是只影响四分之一的数据
变更记录
| Why | Who | When |
|---|---|---|
| 创建 | 武汉-运维-磨渣 | 2017-03-22 |
| 补充OSD设置crush的简单方法 | 武汉-运维-磨渣 | 2017-04-19 |
Ceph实现数据的'不拆分'的更多相关文章
- SQL数据字符串的拆分
一.概述: MSSQL字符串的拆分没有封装太多常用的方式,所以如果向数据库中插入用特殊字符分割字符串(比如CB0$CB2$CB3,CB0$CB2$CB3)时就可能需要数据库能够分割字符串,SQL中拆分 ...
- R之data.table -melt/dcast(数据合并和拆分)
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 30.0px "Helvetica Neue"; color: #323333 } p. ...
- SQL Server查询中对于单列数据','分割的数据进行的拆分操作,集合的每一个行变多行
1.cross apply cross apply 我们可以把它看作成是inner join 来使用 2.outer apply outer apply我们可以把它看做是left join 来使用 注 ...
- Oracle数据行拆分多行
工作和学习中常常会遇到一行要分割成多行数据的情况,在此整理一下做下对比. 单行拆分 如果表数据只有一行,则可以直接在原表上直接使用connect by+正则的方法,比如: select regexp_ ...
- 利用excel拆分数据
要求:将sheet1中的数据按照公司名称拆分到不同的工作表 使用VBA: 1:打开sheet1的查看代码 2:运行 ·········································· ...
- (Sql Server)数据的拆分和合并
(Sql Server)数据的拆分和合并 背景: 今天遇到了数据合并和拆分的问题,尝试了几种写法.但大致可分为两类:一.原始写法.二.Sql Server 2005之后支持的写法.第一种写法复杂而且效 ...
- Ceph源码解析:读写流程
转载注明出处,整理也是需要功夫的,http://www.cnblogs.com/chenxianpao/p/5572859.html 一.OSD模块简介 1.1 消息封装:在OSD上发送和接收信息. ...
- ceph 简介
Ceph 存储集群 数据的存储 伸缩性和高可用性 CRUSH 简介 集群运行图 高可用监视器 高可用性认证 智能程序支撑超大规模 动态集群管理 关于存储池 PG 映射到 OSD 计算 PG ID 互联 ...
- Ceph 架构以及原理分析
一.架构 Ceph在一个统一的系统中独特地提供对象,块和文件存储. Ceph高度可靠,易于管理且免费. Ceph的强大功能可以改变您公司的IT基础架构以及管理大量数据的能力. Ceph提供了非凡的可扩 ...
随机推荐
- 【编程学习】浅谈哈希表及用C语言构建哈希表!
哈希表:通过key-value而直接进行访问的数据结构,不用经过关键值间的比较,从而省去了大量处理时间. 哈希函数:选择的最主要考虑因素--尽可能避免冲突的出现 构造哈希函数的原则是: ①函数本身便于 ...
- Python自动化准备工作(pycharm安装)
一.安装Python 1.下载python-3.7.0-amd64.exe后双击 2.勾选Add Python3.7 to PATH可不用配置环境变量 3.点击下一步,可以按默认路径,也可以自己选择路 ...
- PHP之Trait详解 转
php从以前到现在一直都是单继承的语言,无法同时从两个基类中继承属性和方法,为了解决这个问题,php出了Trait这个特性 用法:通过在类中使用use 关键字,声明要组合的Trait名称,具体的Tra ...
- utf-8和utf-8-sig的区别
前言:在写入csv文件中,出现了乱码的问题. 解决:utf-8 改为utf-8-sig 区别如下: 1."utf-8" 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有 ...
- 视频和音频的 DOM
视频和音频的 DOM HTML5 DOM 为 <audio> 和 <video> 元素提供了方法.属性和事件. HTML5 Audio/Video 方法 方法 描述 addTe ...
- Codeforces Round 665 赛后解题报告(暂A-D)
Codeforces Round 665 赛后解题报告 A. Distance and Axis 我们设 \(B\) 点 坐标为 \(x(x\leq n)\).由题意我们知道 \[\mid(n-x)- ...
- ElasticSearch实战系列九: ELK日志系统介绍和安装
前言 本文主要介绍的是ELK日志系统入门和使用教程. ELK介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件.新增了一 ...
- JavaWeb宿舍管理系统(附 演示、源码下载地址)
宿舍管理是高校管理的重要组成部分,一套优秀的管理系统不仅可以降低宿舍管理的难度,也能在一定程度上减少学校管理费用的支出,能是建设现代化高校管理体系的重要标志. 本篇文章将带你从运行环境搭建.系统设计. ...
- Bitmap缩放(一)
使用矩阵进行压缩,通过缩放图片尺寸,来达到压缩图片的效果,和采样率的原理一样.先用位图的option将位图压缩一半,再用matrix缩放0.3f public class MainActivity e ...
- Kerberos与票据的爱情故事
0x01.Kerberos认证原理 Kerberos是一种认证机制.目的是通过密钥系统为客户端/服务器应用程序提供强大的可信任的第三方认证服务: 保护服务器防止错误的用户使用,同时保护它的用户使用正确 ...