重要 | Spark分区并行度决定机制
最近经常有小伙伴在本公众号留言,核心问题都比较类似,就是虽然接触Spark有一段时间了,但是搞不明白一个问题,为什么我从HDFS上加载不同的文件时,打印的分区数不一样,并且好像spark.default.parallelism这个参数时不是一直起作用?其实笔者之前的文章已有相关介绍,想知道为什么,就必须了解Spark在加载不同的数据源时分区决定机制以及调用不用算子时并行度决定机制以及分区划分。
其实之前的文章《Spark的分区》、《通过spark.default.parallelism谈Spark并行度》已有所介绍,笔者今天再做一次详细的补充,建议大家在对Spark有一定了解的基础上,三篇文章结合一起看。
大家都知道Spark job中最小执行单位为task,合理设置Spark job每个stage的task数是决定性能好坏的重要因素之一,但是Spark自己确定最佳并行度的能力有限,这就要求我们在了解其中内在机制的前提下,去各种测试、计算等来最终确定最佳参数配比。
Spark任务在执行时会将RDD划分为不同的stage,一个stage中task的数量跟最后一个RDD的分区数量相同。之前已经介绍过,stage划分的关键是宽依赖,而宽依赖往往伴随着shuffle操作。对于一个stage接收另一个stage的输入,这种操作通常都会有一个参数numPartitions来显示指定分区数。最典型的就是一些ByKey算子,比如groupByKey(numPartitions: Int),但是这个分区数需要多次测试来确定合适的值。首先确定父RDD中的分区数(通过rdd.partitions().size()可以确定RDD的分区数),然后在此基础上增加分区数,多次调试直至在确定的资源任务能够平稳、安全的运行。
对于没有父RDD的RDD,比如通过加载HDFS上的数据生成的RDD,它的分区数由InputFormat切分机制决定。通常就是一个HDFS block块对应一个分区,对于不可切分文件则一个文件对应一个分区。
对于通过SparkContext的parallelize方法或者makeRDD生成的RDD分区数可以直接在方法中指定,如果未指定,则参考spark.default.parallelism的参数配置。下面是默认情况下确定defaultParallelism的源码:
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
通常,RDD的分区数与其所依赖的RDD的分区数相同,除非shuffle。但有几个特殊的算子:
1. coalesce和repartition算子
笔者先放两张关于该coalesce算子分别在RDD和DataSet中的源码图:(DataSet是Spark SQL中的分布式数据集,后边说到Spark时再细讲)
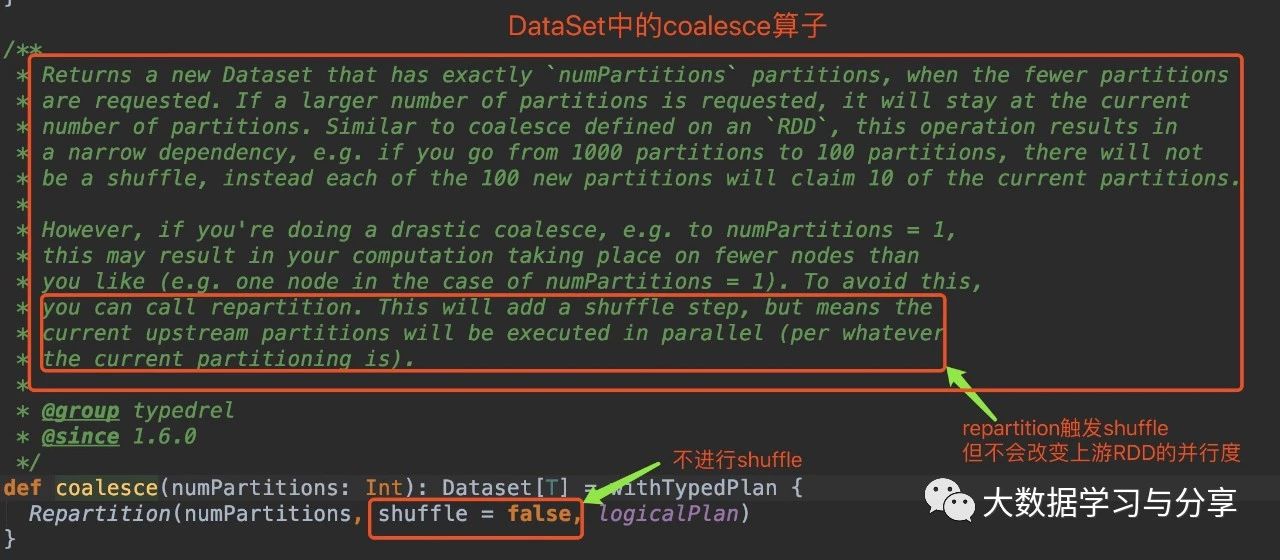
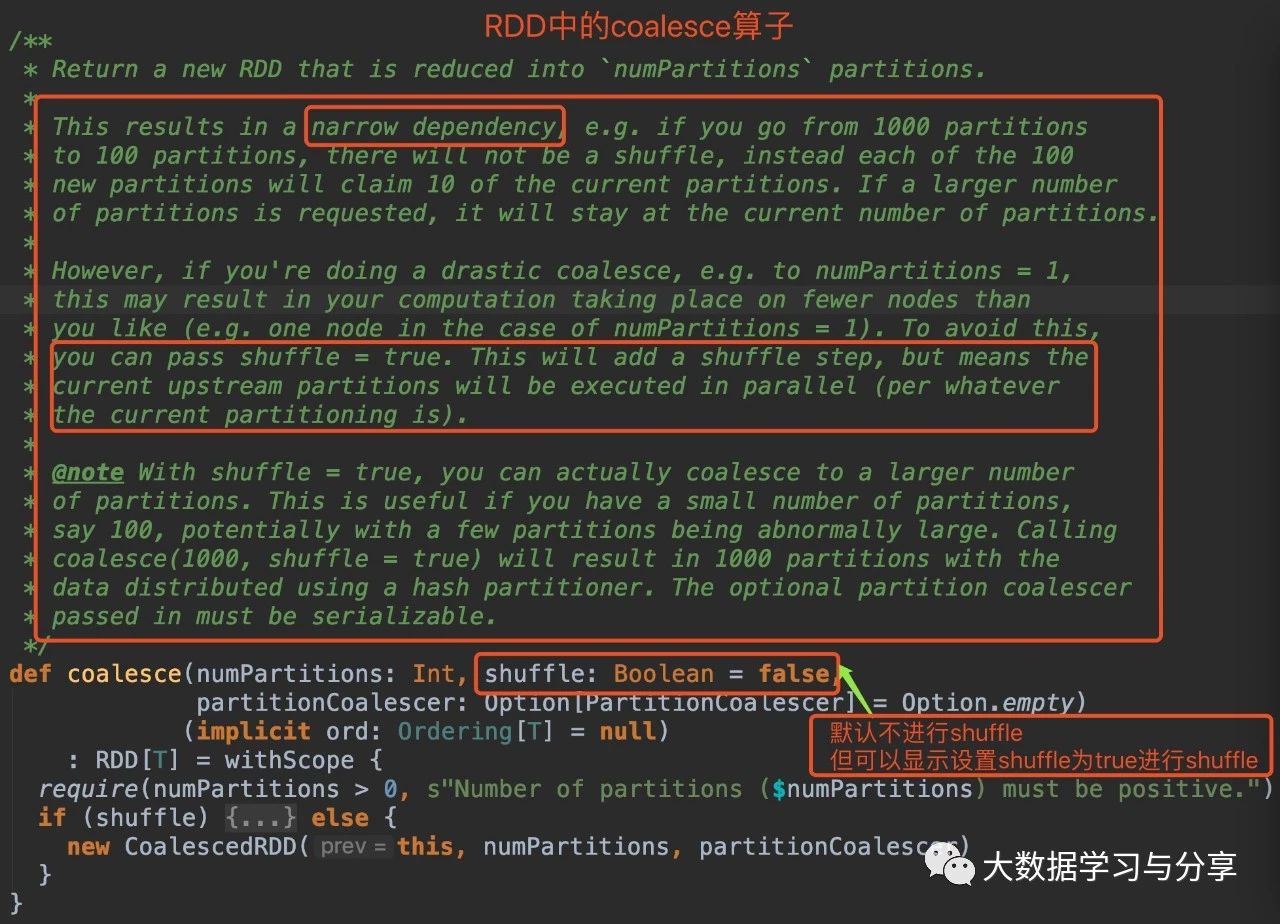
通过coalesce源码分析,无论是在RDD中还是DataSet,默认情况下coalesce不会产生shuffle,此时通过coalesce创建的RDD分区数小于等于父RDD的分区数。
笔者这里就不放repartition算子的源码了,分析起来也比较简单,图中我有所提示。但笔者建议,如下两种情况,请使用repartition算子:
1)增加分区数repartition触发shuffle,shuffle的情况下可以增加分区数。
coalesce默认不触发shuffle,即使调用该算子增加分区数,实际情况是分区数仍然是当前的分区数。
2)极端情况减少分区数,比如将分区数减少为1调整分区数为1,此时数据处理上游stage并行度降,很影响性能。此时repartition的优势即不改变原来stage的并行度就体现出来了,在大数据量下,更为明显。但需要注意,因为repartition会触发shuffle,而要衡量好shuffle产生的代价和因为用repartition增加并行度带来的效益。
2. union算子
还是直接看源码:
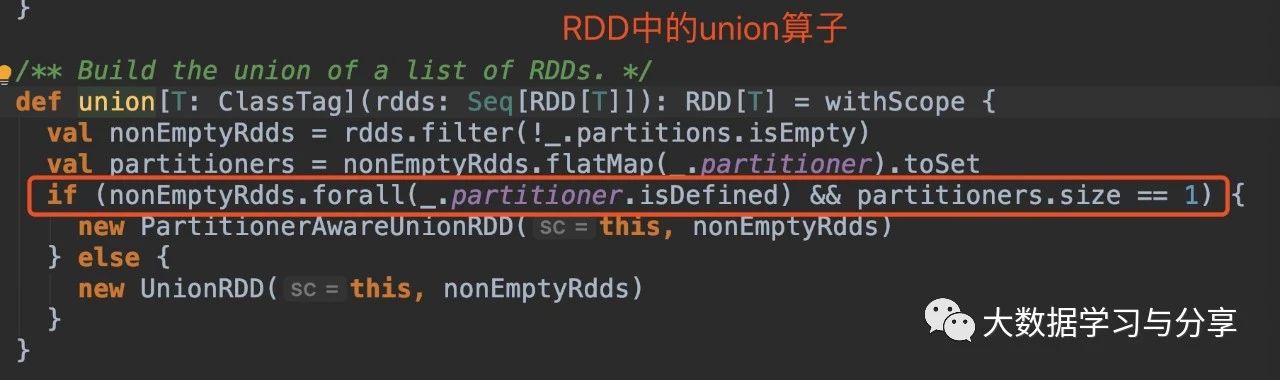

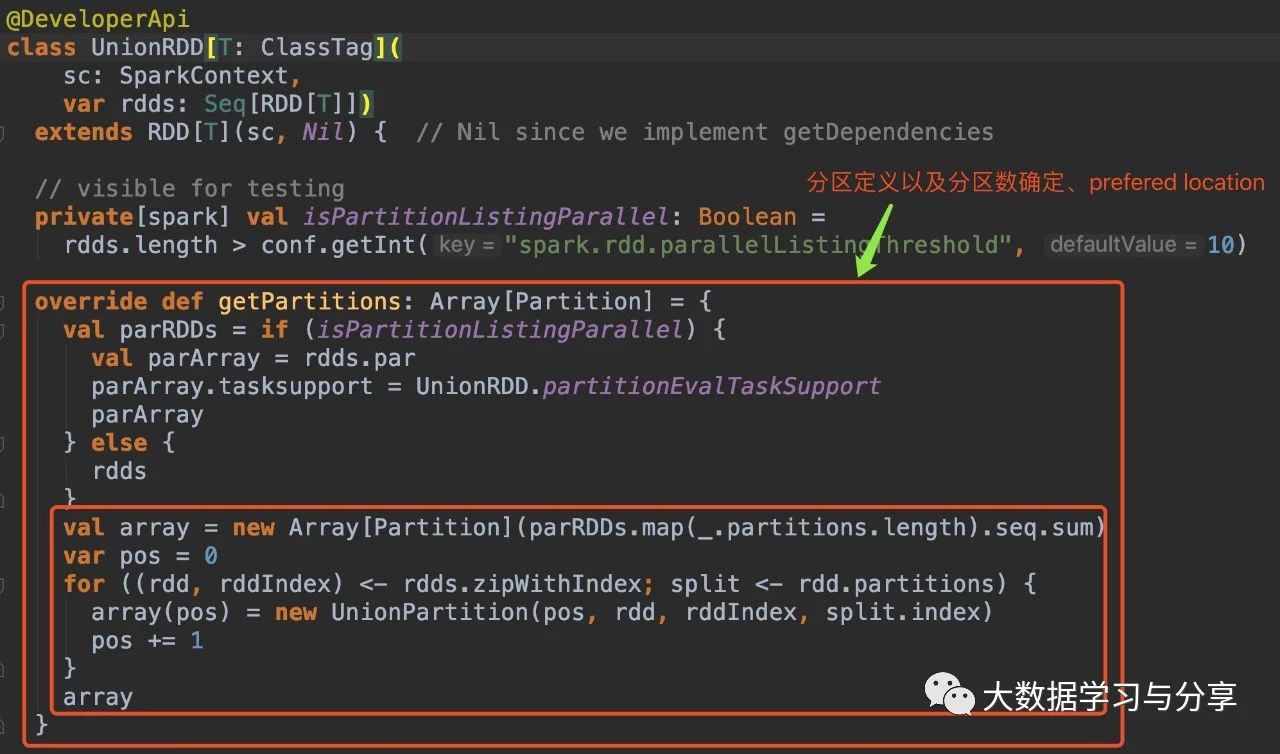
通过分析源码,RDD在调用union算子时,最终生成的RDD分区数分两种情况:1)union的RDD分区器已定义并且它们的分区器相同
多个父RDD具有相同的分区器,union后产生的RDD的分区器与父RDD相同且分区数也相同。比如,n个RDD的分区器相同且是defined,分区数是m个。那么这n个RDD最终union生成的一个RDD的分区数仍是m,分区器也是相同的
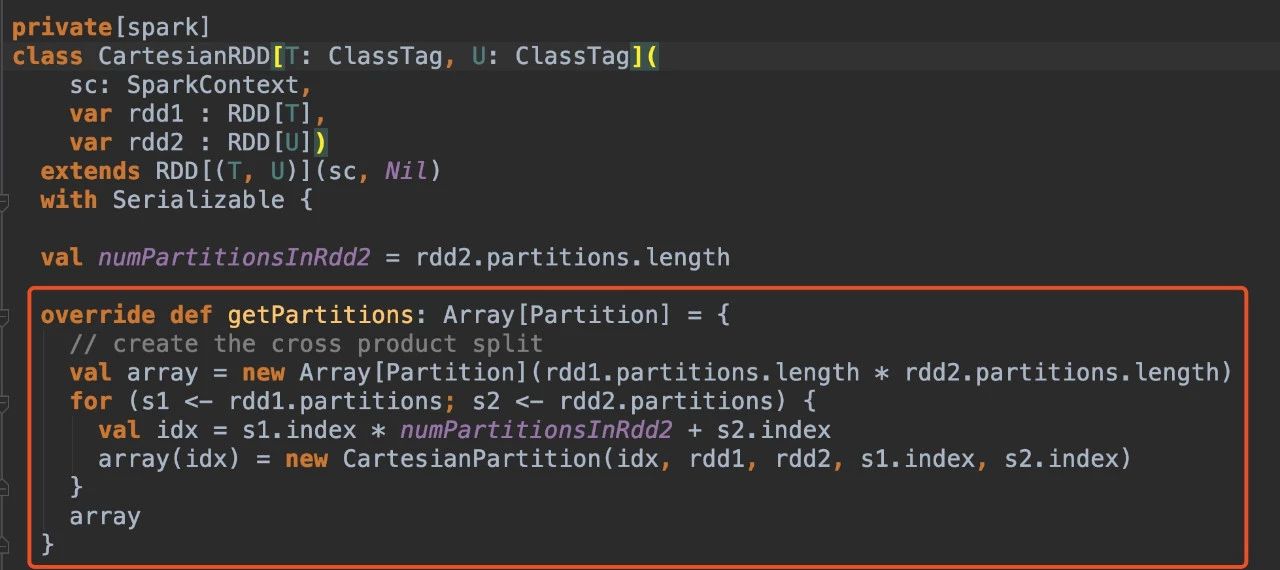
2)不满足第一种情况,则通过union生成的RDD的分区数为父RDD的分区数之和4.cartesian算子
通过上述coalesce、repartition、union算子介绍和源码分析,很容易分析cartesian算子的源码。通过cartesian得到RDD分区数是其父RDD分区数的乘积。
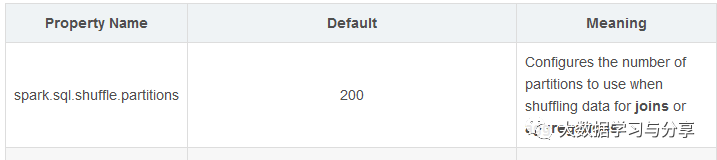
在Spark SQL中,任务并行度参数则要参考spark.sql.shuffle.partitions,笔者这里先放一张图,详细的后面讲到Spark SQL时再细说:
看下图在Spark流式计算中,通常将SparkStreaming和Kafka整合,这里又分两种情况:
1. Receiver方式生成的微批RDD即BlockRDD,分区数就是block数
2. Direct方式生成的微批RDD即kafkaRDD,分区数和kafka分区数一一对应
等说到Spark流式处理时再详细阐述。
关注微信公众号:大数据学习与分享,获取更对技术干货
重要 | Spark分区并行度决定机制的更多相关文章
- Hive和Spark分区策略
1.概述 离线数据处理生态系统包含许多关键任务,最大限度的提高数据管道基础设施的稳定性和效率是至关重要的.这边博客将分享Hive和Spark分区的各种策略,以最大限度的提高数据工程生态系统的稳定性和效 ...
- [Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是從后往前划分的,执行的时候是從前往后执行的,每 ...
- 【Spark 深入学习-08】说说Spark分区原理及优化方法
本节内容 ------------------ · Spark为什么要分区 · Spark分区原则及方法 · Spark分区案例 · 参考资料 ------------------ 一.Spark为什 ...
- Spark学习之路 (十七)Spark分区
一.分区的概念 分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务 ...
- Spark cache、checkpoint机制笔记
Spark学习笔记总结 03. Spark cache和checkpoint机制 1. RDD cache缓存 当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出 ...
- Spark(十一)Spark分区
一.分区的概念 分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务 ...
- 打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是从后往前划分的,执行的时候是從前往后执行的,每 ...
- spark分区
spark默认的partition的分区数是和本机CPU的核数保持一致: bucket的数量和reduce的数量一致:buket的概念是map会将计算获得数据放到各个buket中,每个bucket和一 ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
随机推荐
- rs485转以太网转换器
rs485转以太网转换器ZLAN5103 实现RS485转以太网(即485转网口)主要一个硬件转换器和一个软件驱动.硬件转换器分为两种:串口服务器(串口联网服务器.串口通信服务器).串口联网模块.RS ...
- DFS深度优先搜索算法
Lake Counting(POJ No.2386) 有一个大小为N*M的园子,雨后积起了水.八连通的积水被认为是在一起的.请求出园子里共有多少个水洼?(八连通是指下图中相对w的*部分) * * * ...
- Go 安装配置golint
原文链接:http://zhoubotong.site/post/3.html一. Golint介绍 Golint 是一个源码检测工具用于检测代码规范 Golint 不同于gofmt, Gofmt用于 ...
- jmeter_04_常用取样器
目录 常用取样器详解 http取样器 1.1 基本配置 1.2 高级配置 jdbc取样器 2.1 JDBC Connection Configuration 2.1.1 **Variable Name ...
- spring boot:使用async异步线程池发送注册邮件(spring boot 2.3.1)
一,为什么要使用async异步线程池? 1,在生产环境中,有一些需要延时处理的业务场景: 例如:发送电子邮件, 给手机发短信验证码 大数据量的查询统计 远程抓取数据等 这些场景占用时间较长,而用户又没 ...
- laravel服务容器 转
laravel框架底层解析 本文参考陈昊<Laravel框架关键技术解析>,搭建一个属于自己的简化版服务容器.其中涉及到反射.自动加载,还是需要去了解一下. laravel服务容器 建立项 ...
- 《Kafka笔记》3、Kafka高级API
目录 1 Kafka高级API特性 1.1 Offset的自动控制 1.1.1 消费者offset初始策略 1.1.2 消费者offset自动提交策略 1.2 Acks & Retries(应 ...
- JS 身份证号码验证
function checkIdcard(idcard) { var Errors = new Array( "验证通过!", "身份证号码位数不对!", &q ...
- 没事学学KVM(五)虚拟机基础管理
1.今天学习一下KVM的开机自启功能.开机启动,即随宿主机启动而启动 virsh autostart vm-name 开机自启的前提是libvirt功能也是开机启动的:systemctl enable ...
- 关于隐私保护的英文论文的阅读—— How to read English thesis
首先 开始我读论文时 也是恨不得吃透每个单词 但是后来转念一想 没必要每个单词都弄懂 因为 一些程度副词 修饰性的形容词等 这些只能增强语气罢了 对文章主题的理解并没有天大的帮助 而读文章应该首先把握 ...