用Python爬取网易云音乐热评
用Python爬取网易云音乐热评
本文旨在记录Python爬虫实例:网易云热评下载
由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者。
要看懂本文,需要具备一点点网络相关知识。不过没有关系,不懂的概念自行百度,基本都能解决。
1. 基本知识
1.1 爬虫是什么
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,
沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用
简言之,就是向目标网站发起请求获得响应并提取相应数据的自动化程序。
1.2 爬虫的基本流程
1:向服务器发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器的响应。
2:获取响应内容
如果服务器正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML、JSON、二进制文件(如图片、视频等类型)。
3:解析内容
得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是JSON,可以直接转成JOSN对象进行解析,可能是二进制数据,可以保存或者进一步处理
4:保存内容
保存形式多样,可以保存成文本,也可以保存至数据库,或者保存成特定格式的文件。————————————————
原文链接:https://blog.csdn.net/qq_29186489/java/article/details/78587634
1.3 Request与Response
Request中包含哪些内容?
1:请求方式
主要是GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。
2:请求URL
URL全称是统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一来确定
3:请求头
包含请求时的头部信息,如User-Agent、Host、Cookies等信息
4:请求体
请求时额外携带的数据,如表单提交时的表单数据Response中包含哪些内容?
1:响应状态
有多种响应状态,如200代表成功,301代表跳转,404代表找不到页面,502代表服务器错误等
2:响应头
如内容类型、内容长度、服务器信息、设置cookies等等
3:响应体
最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等。
示例代码:from fake_useragent import UserAgent
import requests
ua=UserAgent()
#请求的网址
url="http://www.baidu.com"
#请求头
headers={"User-Agent":ua.random}
#请求网址
response=requests.get(url=url,headers=headers)
#响应体内容
print(response.text)
#响应状态信息
print(response.status_code)
#响应头信息
print(response.headers)
能抓到怎样的数据?
1:网页文本
如HTML文档、JSON格式文本等
2:图片文件
获取的是二进制文件,保存为图片格式
3:视频
同为二进制文件,保存为视频格式即可
4:其他
只要能够请求到的,都能够获取到
————————————————
原文链接:https://blog.csdn.net/qq_29186489/java/article/details/78587634
2.准备工作
2.1 网页数据请求及响应
这里,已有众多网友给出了请求方式的具体请求方式。
new-june博客中详细给出了请求查看方式以及提交表单中两个加密参数的破解。
实际上 Rotation给出了整个爬取过程,本文也是在其代码基础上完成的。
简单来说,就是通过使用浏览器的开发者工具,找到数据请求方式以及目标数据的来源,从而进行程序化请求与数据处理。
2.2 本文思路
首先,发送请求(request),获取歌单中每一首歌名及其ID(正则表达式:re);其次,获取每首歌的热评内容(json),评论用户昵称,点赞数;将获得的数据写入Excel文件中(openpyxl)。
2.3 Python环境准备
王树义以Anacoda为例,详细的给出了其安装过程。Anacoda中已经集成了众多开发环境,本文在其中的Spyder环境中进行程序开发。
根据思路,本文需要以下模块:
request
re
json
openpyxl
3. 程序解读
3.1 加载相关模块
import re
import requests
import json
import openpyxl
3.2 生成表格文件
wb=openpyxl.Workbook()
sheet=wb.active
sheet为excel中第一个sheet名
3.3 歌名及ID获取函数
def get_all_hotsongs():
"""抓取歌单中所有歌曲"""
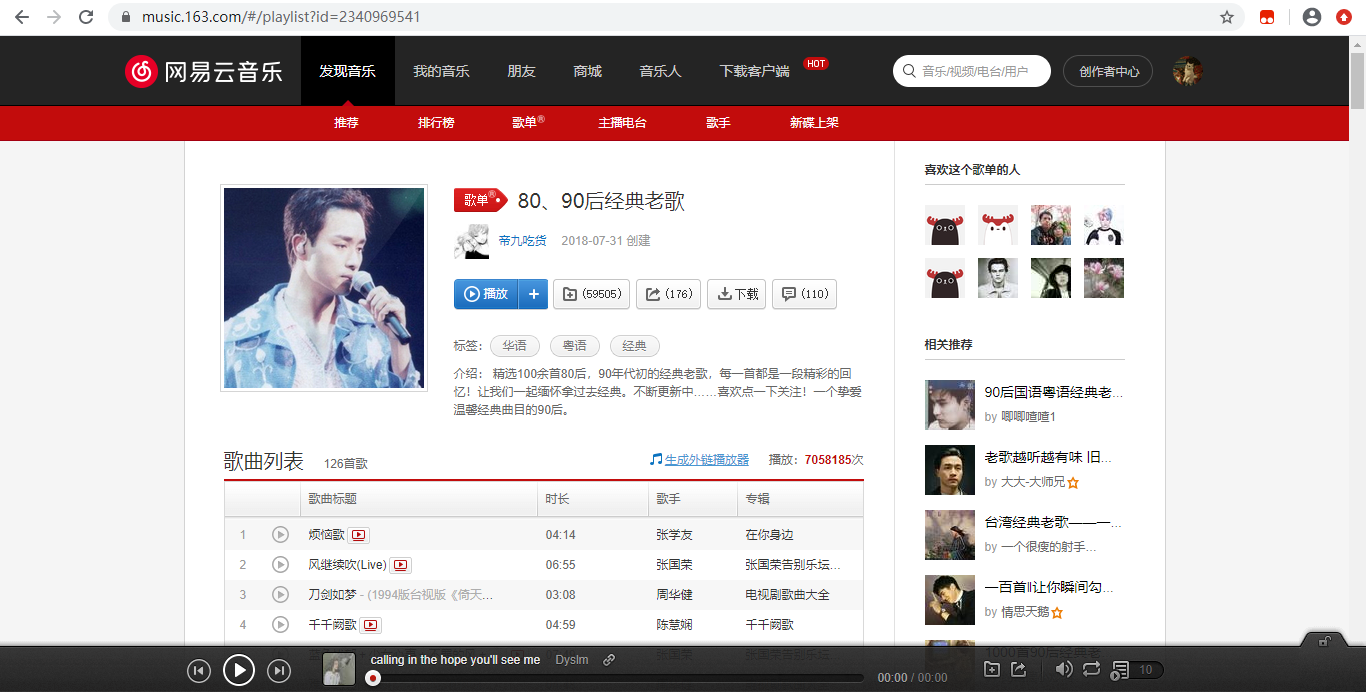
url = 'https://music.163.com/playlist?id=2340969541' #此链接可替换为任意歌单链接,需要注意的是,直接从浏览器复制后需要去掉url中的/#
#构造模拟请求信息
headers = {
'Cookie':'__e_=1515461191756; _ntes_nnid=af802a7dd2cafc9fef605185da6e73fb,1515461190617; _ntes_nuid=af802a7dd2cafc9fef605185da6e73fb; JSESSIONID-WYYY=HMyeRdf98eDm%2Bi%5CRnK9iB%5ChcSODhA%2Bh4jx5t3z20hhwTRsOCWhBS5Cpn%2B5j%5CVfMIu0i4bQY9sky%5CsvMmHhuwud2cDNbFRD%2FHhWHE61VhovnFrKWXfDAp%5CqO%2B6cEc%2B%2BIXGz83mwrGS78Goo%2BWgsyJb37Oaqr0IehSp288xn5DhgC3Cobe%3A1515585307035; _iuqxldmzr_=32; __utma=94650624.61181594.1515583507.1515583507.1515583507.1; __utmc=94650624; __utmz=94650624.1515583507.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmb=94650624.4.10.1515583507',
'Host':'music.163.com',
'Refere':'http://music.163.com/',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
r = requests.get(url,headers=headers)
#使用正则表达式匹配正文响应,获取歌名及歌曲ID
reg1 = r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>'
result_contain_songs_ul = re.compile(reg1).findall(r.text)
result_contain_songs_ul = result_contain_songs_ul[0]
reg2 = r'<li><a href="/song\?id=\d*?">(.*?)</a></li>'
reg3 = r'<li><a href="/song\?id=(\d*?)">.*?</a></li>'
hot_songs_name = re.compile(reg2).findall(result_contain_songs_ul)
hot_songs_id = re.compile(reg3).findall(result_contain_songs_ul)
#返回歌曲名 歌曲id
return hot_songs_name,hot_songs_id
3.4 获取热评函数
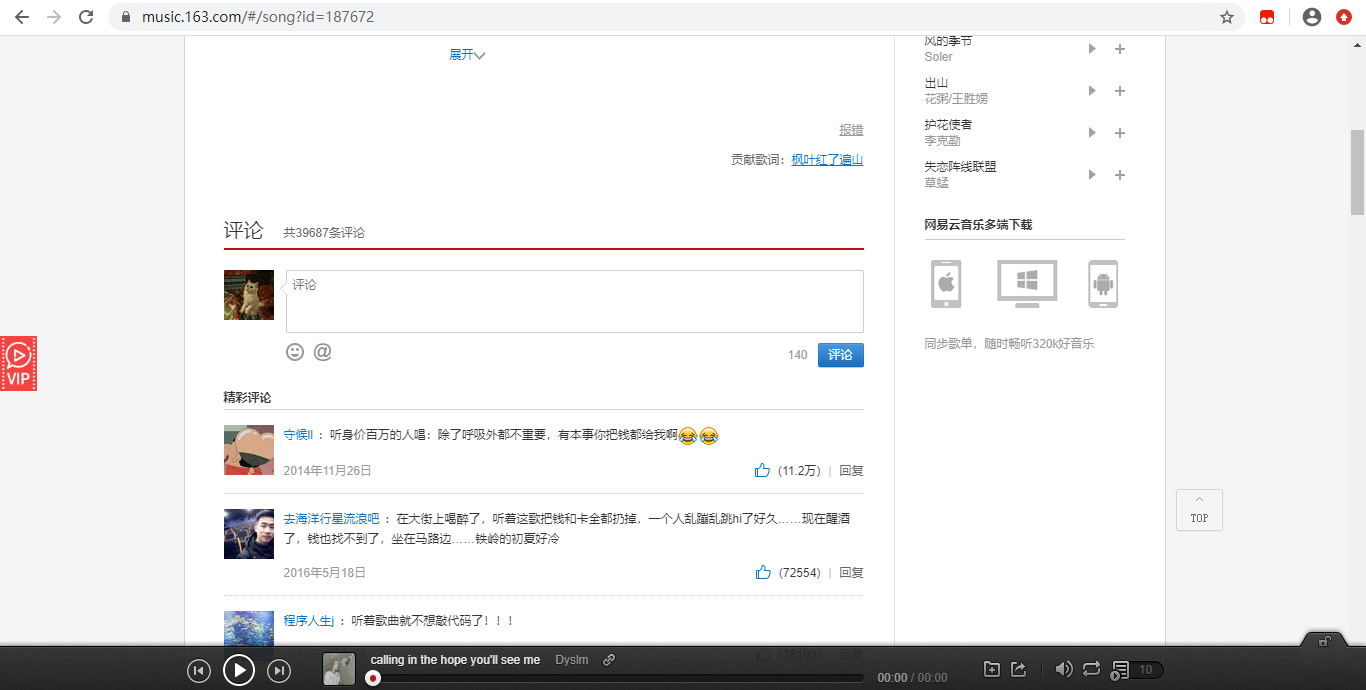
def get_hotcommnets(hot_songs_name,hot_songs_id):
"""抓取歌曲热评"""
#评论请求url
url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_'+hot_songs_id+'?csrf_token='
#请求头构造
headers = {
'Host':'music.163.com',
'Proxy-Connection':'keep-alive',
'Origin':'http://music.163.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)',
'Content-Type':'application/x-www-form-urlencoded',
'Accept':'*/*',
'Referer':'http://music.163.com/song?id='+hot_songs_id+'',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh,zh-TW;q=0.9,en-US;q=0.8,en;q=0.7',
'Cookie':'__e_=1515461191756; _ntes_nnid=af802a7dd2cafc9fef605185da6e73fb,1515461190617; _ntes_nuid=af802a7dd2cafc9fef605185da6e73fb; _iuqxldmzr_=32; __utmc=94650624; __utmz=94650624.1515628584.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; JSESSIONID-WYYY=TO%2BtUvrTWONNwB%2BgzDpfjFDiggKiS%2FfpMYNam%2BWGooHNka%2BwMhdsT%5CY%2Fn%2FpSMJwo4skFIK1T%2FNjd95lbGHWMQr5d5qcMRPB9SVKWK8UuBs1OGugZ4lFwipwjwWbCepSw%5CjWv31i1Qt%5CWWwtrFzzktj8CdCzniAw%5CgFCElUJnsQygY0MA%3A1515635604215; __utma=94650624.61181594.1515583507.1515630648.1515633862.4; __utmb=94650624.2.10.1515633862'
}
#评论第一页请求表单提交参数
data = {
'params':'cG5yxYo1s0E9Eqv4QWJLM0fdPiJr0+GfKwqcGPulhOtGJ16gEBopaMhe6XeVNKDigMlpCaV7vrDNQLIOPIaTpAjlcJv+hjdCek6nL0ODfHt9ZEmtkTmU4r/+SA6Vno+o+c4EaPvhghNUXRMdVM/LltKvVanwOSvVhcqUPw9qij1d1akcxweLOWf1hKh2/q/m',
'encSecKey':'a6c21ac04a44dca0e68174f9dfa85537a2694ecf7b43bdcd46a90836209a3d68008b430b54751bc0f56b12b6da38a265afcef1edbf687d70d1eb853144e920fea28e19a8c6145b7bad33e40d077e8a689b4bf67b367db815278af4ef227b02d85e609007106b7fc4a547bf96a1b90b0eda85bca6cc79ca6fc6559d00060d4184'
}
#获取响应
response = requests.post(url,data=data,headers=headers)
#格式化响应正文hotComments热评节点
hotcomments = json.loads(response.text)['hotComments']
#遍历热评内容 保存到当前excel
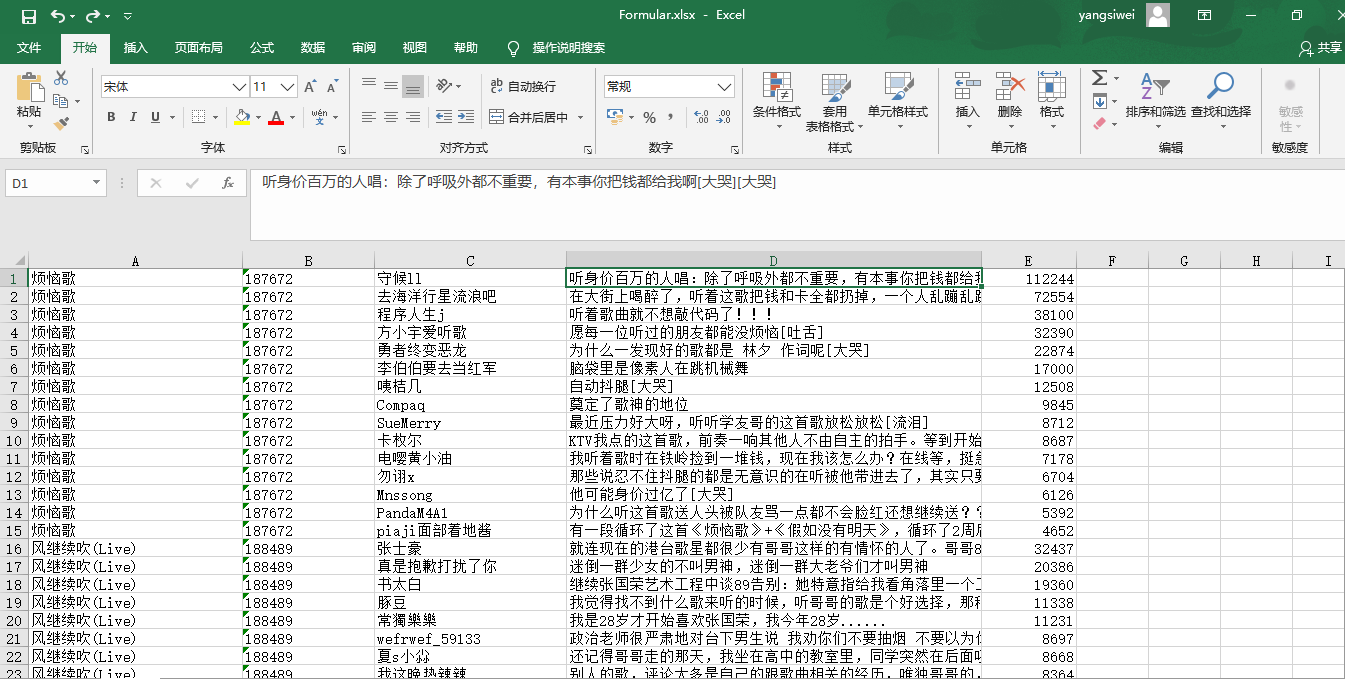
for i in range(len(hotcomments)):
user_name = hotcomments[i]['user']['nickname'] #获取用户昵称
comment = hotcomments[i]['content'] #获取热评内容
like_num = hotcomments[i]['likedCount'] #获取点赞数
x=[hot_songs_name,hot_songs_id,user_name,comment,like_num]
#将上述信息连续按行写入excel
sheet.append(x)
3.5 函数调用
#调用方法 获得歌曲名 歌曲id
hot_songs_name,hot_songs_id = get_all_hotsongs()
#循环遍历抓取所有热评
num = 0
while num < len(hot_songs_name):
print('正在抓取网易云音乐第%d首歌曲热评...'%(num+1))
get_hotcommnets(hot_songs_name[num],hot_songs_id[num])
print('第%d首歌曲热评抓取成功'%(num+1))
num+=1
wb.save(filename = 'Formular.xlsx')
4.结果验证
5. 附
代码实测可用,博客园中markdown缩进不友好,换行可能会导致代码出错,请注意。
用Python爬取网易云音乐热评的更多相关文章
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- python爬取网易云音乐歌单音乐
在网易云音乐中第一页歌单的url:http://music.163.com/#/discover/playlist/ 依次第二页:http://music.163.com/#/discover/pla ...
- xpath+多进程爬取网易云音乐热歌榜。
用到的工具,外链转换工具 网易云网站直接打开源代码里面并没有对应的歌曲信息,需要对url做处理, 查看网站源代码路径:发现把里面的#号去掉会显示所有内容, 右键打开的源代码路径:view-source ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- python爬虫+词云图,爬取网易云音乐评论
又到了清明时节,用python爬取了网易云音乐<清明雨上>的评论,统计词频和绘制词云图,记录过程中遇到一些问题 爬取网易云音乐的评论 一开始是按照常规思路,分析网页ajax的传参情况.看到 ...
- 爬取网易云音乐评论!python 爬虫入门实战(六)selenium 入门!
说到爬虫,第一时间可能就会想到网易云音乐的评论.网易云音乐评论里藏了许多宝藏,那么让我们一起学习如何用 python 挖宝藏吧! 既然是宝藏,肯定是用要用钥匙加密的.打开 Chrome 分析 Head ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
随机推荐
- taro 进阶指南
taro 进阶指南 配置 https://nervjs.github.io/taro/docs/config.html https://nervjs.github.io/taro/docs/confi ...
- linux DRM 之 GEM 笔记
原文链接:https://www.cnblogs.com/yaongtime/p/14418357.html 在GPU上的各类操作中涉及到多种.多个buffer的使用. 通常我们GPU是通过图像API ...
- C++算法代码——选举学生会
题目来自:https://www.luogu.com.cn/problem/P1271 题目描述 学校正在选举学生会成员,有 n(n\le 999)n(n≤999) 名候选人,每名候选人编号分别从 1 ...
- 整合mybatis plus
第一步:导入jar包 导入页面模板引擎,这里我们用的是freemarker <!--mp--> <dependency> <groupId>com.baomidou ...
- 微信小程序(五)-常见组件(标签)
常见组件(标签) https://developers.weixin.qq.com/miniprogram/dev/component/ 1.view 代替以前的div标签 2.text 1.文本标签 ...
- MySQL 事务的隔离级别
转载:https://developer.aliyun.com/article/743691?accounttraceid=80d4fddb3dc64b97a71118659e106221tozz 简 ...
- JAVA网络编程基本功之Servlet与Servlet容器
Servlet与Servlet容器关系 Servlet 比较这两个的区别, 就得先搞清楚Servlet 的含义, Servlet (/ˈsərvlit/ ) 翻译成中文就是小型应用程序或者小服务程序, ...
- 大话Spark(6)-源码之SparkContext原理剖析
SparkContext是整个spark程序通往集群的唯一通道,他是程序的起点,也是程序的终点. 我们的每一个spark个程序都需要先创建SparkContext,接着调用SparkContext的方 ...
- c++ vector对象
下面随笔讲解c++ vector对象. vector对象 为什么需要vector? 封装任何类型的动态数组,自动创建和删除. 数组下标越界检查. 封装的如ArrayOfPoints也提供了类似功能,但 ...
- 剑指 Offer 57 - II. 和为s的连续正数序列 + 双指针 + 数论
剑指 Offer 57 - II. 和为s的连续正数序列 Offer_57_2 题目描述 方法一:暴力枚举 package com.walegarrett.offer; /** * @Author W ...