SparkSql自定义数据源之读取的实现
一.sparksql读取数据源的过程
1.spark目前支持读取jdbc,hive,text,orc等类型的数据,如果要想支持hbase或者其他数据源,就必须自定义

2.读取过程
(1)sparksql进行 session.read.text()或者 session.read .format("text") .options(Map("a"->"b")).load("")

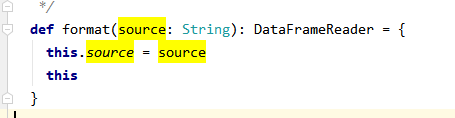

read.方法:创建DataFrameReader对象
format方法:赋值DataFrameReade数据源类型
options方法:赋值DataFrameReade额外的配置选项

进入 session.read.text()方法内,可以看到format为“text”
(2)进入load方法
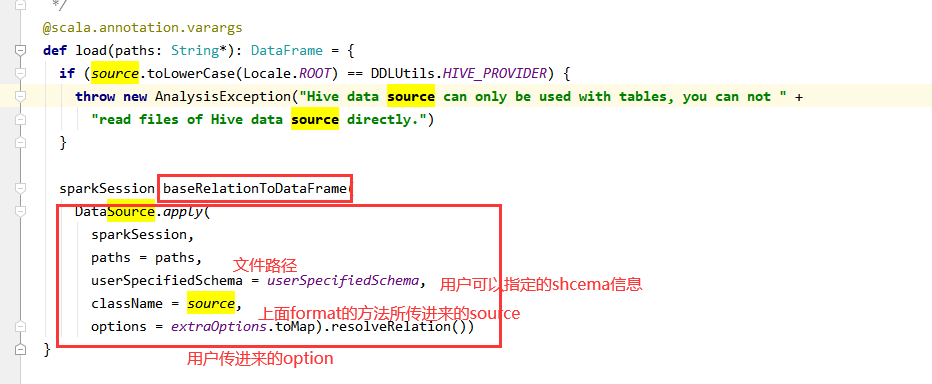
load原来是:sparkSession.baseRelationToDataFrame这个方法最终创建dataframe
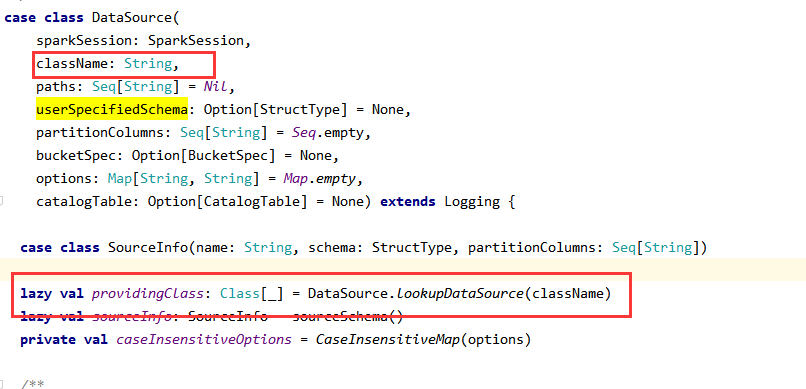
(3)进入DataSource的resolveRelation()方法
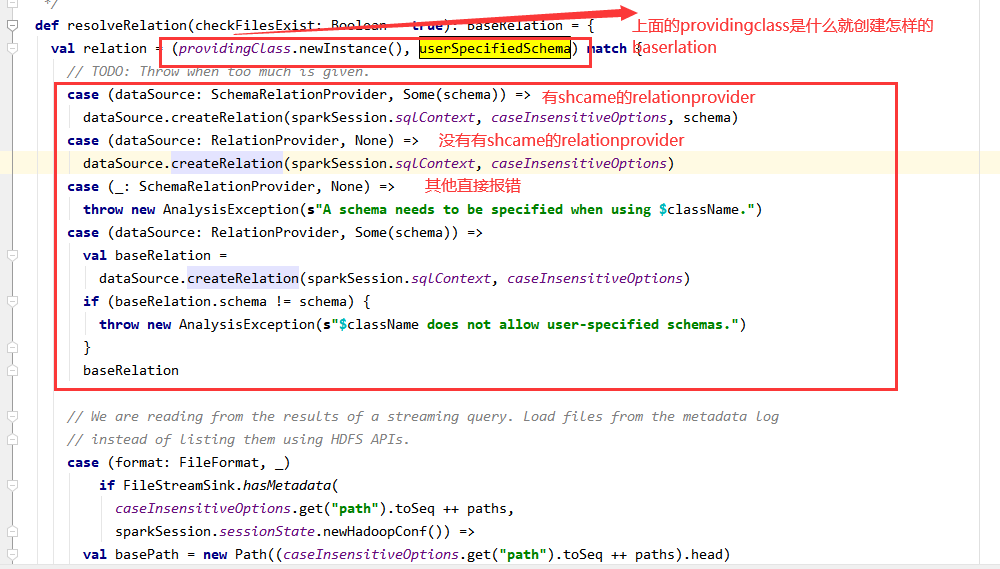
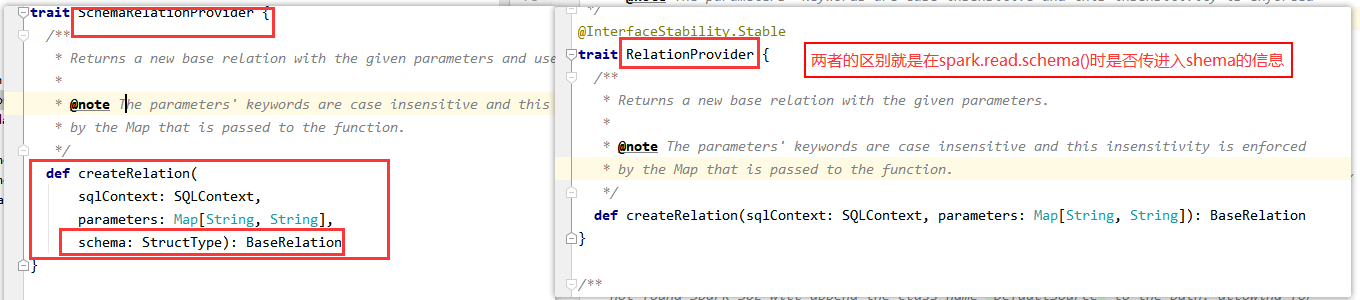
此段就是:providingClass这个类是哪一个接口的实现类,分为有shema与没有传入schema的两种
(3)providingClass是format传入的数据源类型,也就是前面的source
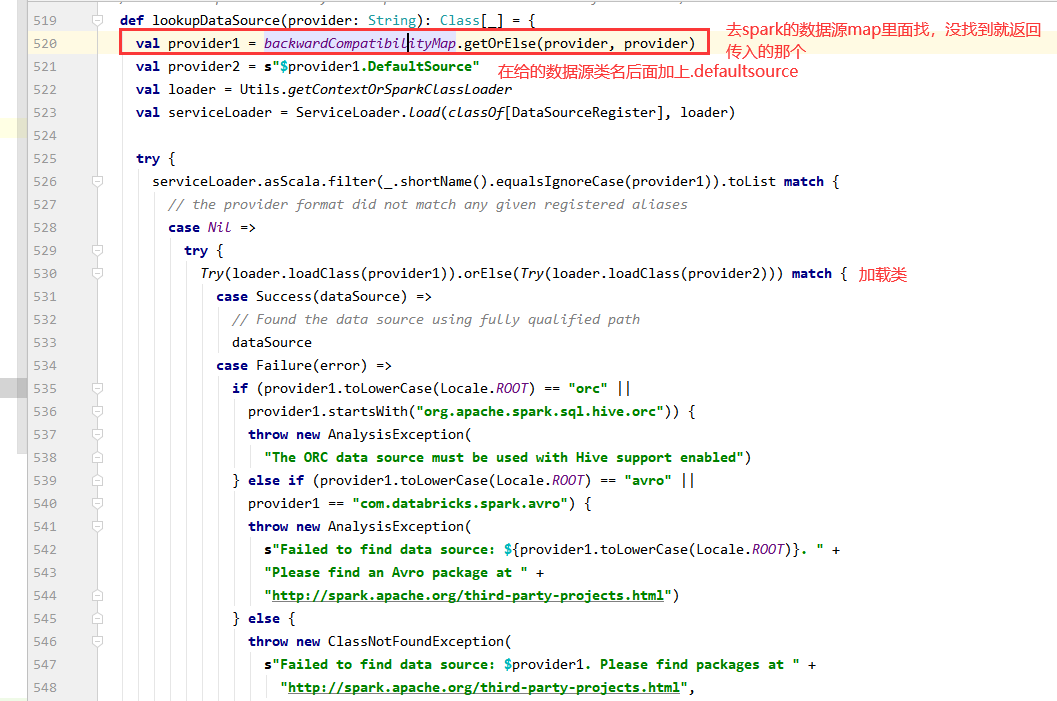
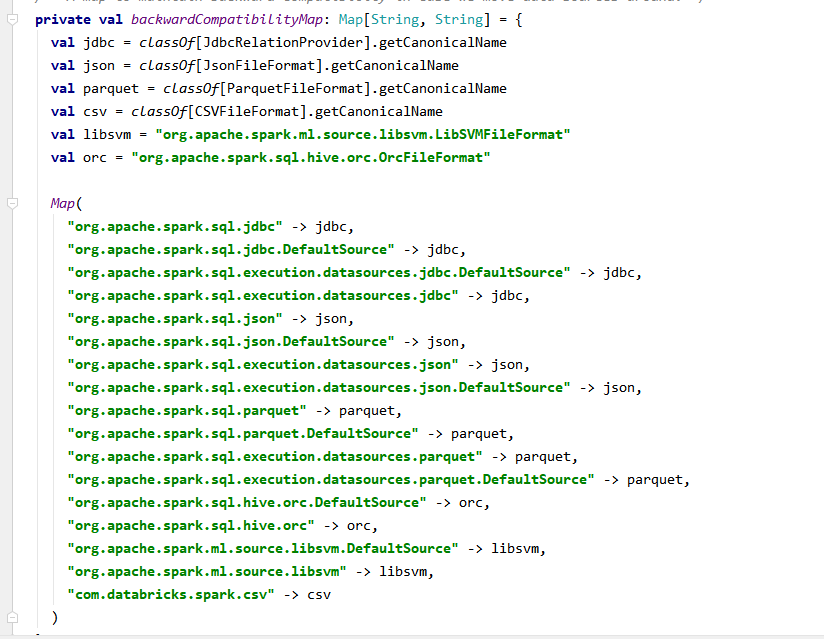
spark提供的所有数据源的map
4.得出结论只要写一个类,实现RelationProvider下面这个方法,在方法里面返回一个baserelation
def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation
我们在实现baserelation里面的逻辑就可以了

5.看看spark读取jdbc类
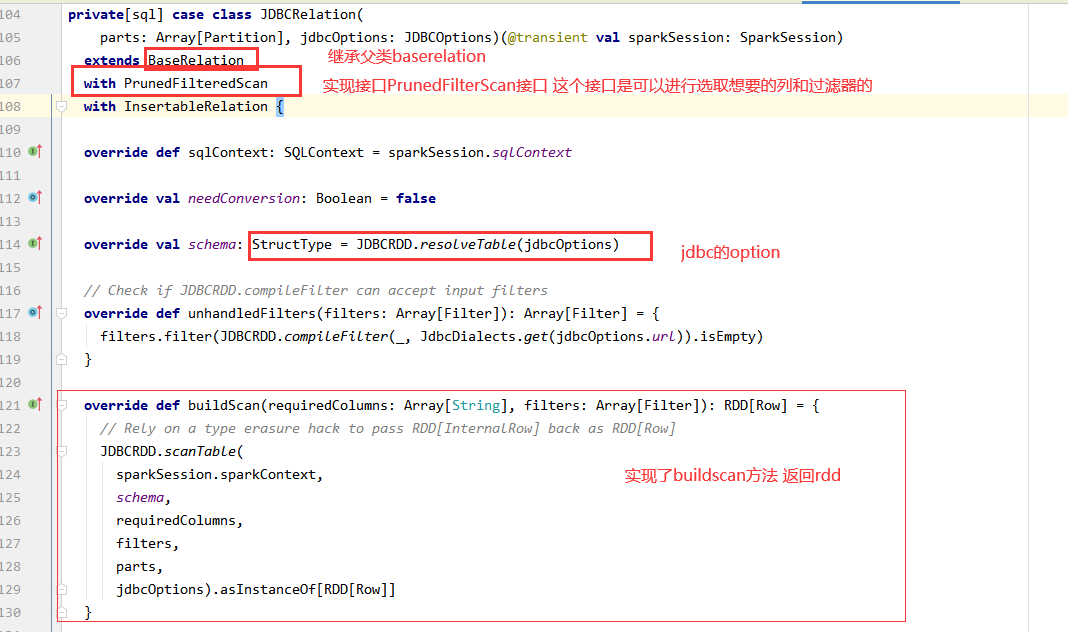
需要一个类,实现xxxScan这中类,这种类有三种,全局扫描tableScan,PrunedFilteredScan(列裁剪与谓词下推),PrunedScan ,
实现buildscan方法返回row类型rdd,结合baserelation有shcame这个变量 ,就凑成了dataframe
6.jdbcRdd.scanTable方法,得到RDD
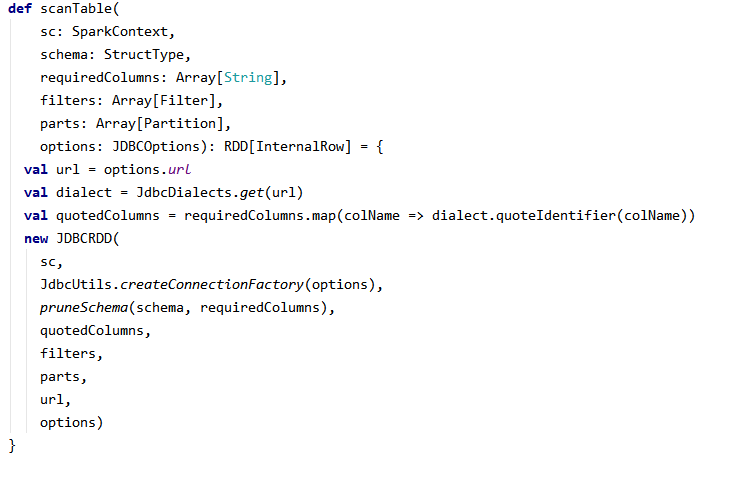
7.查看jdbcRDD的compute方法,是通过jdbc查询sql的方式获取数据
RDD的计算是惰性的,一系列转换操作只有在遇到动作操作是才会去计算数据,而分区作为数据计算的基本单位。在计算链中,无论一个RDD有多么复杂,其最终都会调用内部的compute函数来计算一个分区的数据。
override def compute(thePart: Partition, context: TaskContext): Iterator[InternalRow] = {
var closed = false
var rs: ResultSet = null
var stmt: PreparedStatement = null
var conn: Connection = null
def close() {
if (closed) return
try {
if (null != rs) {
rs.close()
}
} catch {
case e: Exception => logWarning("Exception closing resultset", e)
}
try {
if (null != stmt) {
stmt.close()
}
} catch {
case e: Exception => logWarning("Exception closing statement", e)
}
try {
if (null != conn) {
if (!conn.isClosed && !conn.getAutoCommit) {
try {
conn.commit()
} catch {
case NonFatal(e) => logWarning("Exception committing transaction", e)
}
}
conn.close()
}
logInfo("closed connection")
} catch {
case e: Exception => logWarning("Exception closing connection", e)
}
closed = true
}
context.addTaskCompletionListener{ context => close() }
val inputMetrics = context.taskMetrics().inputMetrics
val part = thePart.asInstanceOf[JDBCPartition]
conn = getConnection()
val dialect = JdbcDialects.get(url)
import scala.collection.JavaConverters._
dialect.beforeFetch(conn, options.asProperties.asScala.toMap)
// H2's JDBC driver does not support the setSchema() method. We pass a
// fully-qualified table name in the SELECT statement. I don't know how to
// talk about a table in a completely portable way.
//坐上每个分区的Filter条件
val myWhereClause = getWhereClause(part)
//最終查询sql语句
val sqlText = s"SELECT $columnList FROM ${options.table} $myWhereClause"
//jdbc查询
stmt = conn.prepareStatement(sqlText,
ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)
stmt.setFetchSize(options.fetchSize)
rs = stmt.executeQuery()
val rowsIterator = JdbcUtils.resultSetToSparkInternalRows(rs, schema, inputMetrics)
//返回迭代器
CompletionIterator[InternalRow, Iterator[InternalRow]](
new InterruptibleIterator(context, rowsIterator), close())
}
SparkSql自定义数据源之读取的实现的更多相关文章
- JDBC 学习笔记(三)—— 数据源(数据库连接池):DBCP数据源、C3P0 数据源以及自定义数据源技术
本文目录: 1.应用程序直接获取连接的缺点(图解) 2.使用数据库连接池优化程序性能(图解) 3.可扩展增强某个类方法的功能的三种方式 4.自定 ...
- Pro自定义数据源原理
1. 概念 Connector:定义连接到一个数据源的连接信息,用于创建datastore. Datastore:代表一个数据源的实例,用于打开一个或多个tables或feature class. ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- FastReport自定义数据源及ListView控件的使用
##1.想批量生成一堆物资信息卡,效果如下图所示,fastreport可以一下全部生成,并且发现不用单独写东西, ##2.发现FastReport官方给出的Demo.exe很友好,基本可以满足要求,想 ...
- C#读取Excel文件:通过OleDb连接,把excel文件作为数据源来读取
转载于:http://developer.51cto.com/art/200908/142392.htm C#读取Excel文件可以通过直接读取和OleDb连接,把excel文件作为数据源来读取: ...
- Aspose.Word邮件合并之自定义数据源
Aspose.Word在进行邮件合并时,默认的几个重载方法对Database支持比较友好,但是也可以通过自定义数据源来实现从集合或者对象中返回数据进行邮件合并. 自定义数据源主要是通过实现IMailM ...
- 20. Spring Boot 默认、自定义数据源 、配置多个数据源 jdbcTemplate操作DB
Spring-Boot-2.0.0-M1版本将默认的数据库连接池从tomcat jdbc pool改为了hikari,这里主要研究下hikari的默认配置 0. 创建Spring Boot项目,选中 ...
- WinForm中使用CrystalReport水晶报表——基础,分组统计,自定义数据源
开篇 本篇文章主要是帮助刚开始接触CrystalReport报表的新手提供一个循序渐进的教程.该教程主要分为三个部分1)CrystalReport的基本使用方法:2)使用CrystalReport对数 ...
- 如何在ASP.NET Core自定义中间件中读取Request.Body和Response.Body的内容?
原文:如何在ASP.NET Core自定义中间件中读取Request.Body和Response.Body的内容? 文章名称: 如何在ASP.NET Core自定义中间件读取Request.Body和 ...
随机推荐
- PyQt(Python+Qt)学习随笔:Qt Designer中的menu菜单及menu bar菜单栏
菜单由menu bar菜单栏和menu菜单两部分构成,分别对应类QMenuBar和QMenu. menuBar是包含一系列下拉菜单项组成,menu包含两种,一种是直接对应Action的,一种是父菜单, ...
- GBK宽字节注入SQL
SQL注入:宽字节注入(GBK双字节绕过) 2015-06-09lyiang 宽字节注入的作用是非常大的,实际上在代码层的防御一般不外乎两种,一是反斜杠转义,而就是replace替换成空字节,之前的替 ...
- 深入理解C#中的异步(一)——APM模式EAP模式
深入理解C#中的异步(一)--APM模式EAP模式 目录 深入理解C#中的异步(一)--APM模式EAP模式 1 使用异步编程的原因 2 异步编程模式 2.1 APM模式 2.1.1 APM模式示例代 ...
- ip 子网掩码、网络地址、广播地址计算
例:已知ip 16.158.165.91/22子网掩码 根据22 得知子网掩码占22位 即:11111111.11111111.11111100.00000000 == 255.255.252. ...
- WPF源代码分析系列一:剖析WPF模板机制的内部实现(一)
众所周知,在WPF框架中,Visual类是可以提供渲染(render)支持的最顶层的类,所有可视化元素(包括UIElement.FrameworkElment.Control等)都直接或间接继承自Vi ...
- 敏捷开发 | DSDM 在非 IT 领域也同样适用?
动态系统开发方法(Dynamic Systems Development Method:DSDM)是在快速应用程序开发(RAD)方法的基础上改进的.作为敏捷方法论的一种,DSDM方法倡导以业务为核心, ...
- hive的调优策略
hive有时执行速度很慢,若hive on spark 的话,在sparkUI上可以清楚看到是否数据倾斜 优化方法: 1.增加reduce数目 hive.exec.reducers.bytes.per ...
- 使用数据泵,在不知道sys用户密码的情况下导出导入
expdp \"/as sysdba\" directory=my_dir logfile=expdp.log dumpfile=expdp_scott.dmp schemas=s ...
- AWT02-ContainerAPI
1.体系 Object -Component -Container Window:窗口容器 Frame:创建窗口 Dialog:创建对话框 Panel:内嵌容器 Applet ScrollPane:含 ...
- 基于nacos注册中心的ribbon定制规则
前面说到基于nacos的注册发现有可以扩展实现我们自己的负载均衡算法(Nacos数据模型),来实现同集群调用,是基于spring.cloud.nacos.discovery.cluster-name参 ...