SQL精华总结索引类型优化SQL优化事务大表优化思维导图❤️
索引类型
从数据结构角度:
- B+树索引,
- hash索引,基于哈希表实现,只有全值匹配才有效。以链表的形式解决冲突。查找速度非常快 O(1)
- 全文索引,查找的是文本中的关键词,而不是直接比较索引中的值,类似于搜索引擎做的事情。
- 空间数据索引(R-Tree),MyISAM支持空间索引,可以用作地理数据存储,会从所有维度来索引数据,有效的使用任意维度来组合查询。
从物理存储角度:
聚簇索引,InnoDB同一个结构保存了索引和数据行,叶子节点的data域存放了行的全部数据。
优点:数据访问快。将索引和数据保存在同一个B+树种,因此比非聚簇索引快。可以把相关数据保存到一起。例如根据用户ID来聚集数据,只需从磁盘读取少量数据页就可以获得用户ID的全部邮件。
缺点:插入速度验证依赖于插入顺序,乱序写入会导致频繁的页分裂移动大量数据。更新代价很高,因为要将每个被更新的行移到到新位置。面临页分裂问题,当某个页已满时,存储引擎会讲该页分成两个页面来容纳该行。
尽可能的按主键顺序插入数据,并且尽可能的使用单调增加的聚簇键的值来插入新行。
非聚簇索引,MyISAM索引文件和数据文件是分离的,叶子节点的data域存放的是行数据的地址
优点: 更新代价比聚集索引要小 。
缺点:跟聚集索引一样,非聚集索引也依赖于有序的数据。可能会二次查询(回表) ,当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
从逻辑角度:
- 普通 /单列索引,普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。
INDEX index_name ( column )。 - 唯一索引,唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。
UNIQUE ( column ) - 主键索引,数据表的主键列使用的就是主键索引
PRIMARY KEY ( column) - 联合索引,指多个字段上创建的索引
INDEX index_name ( column1, ... ),使用时最左匹配原则 - 前缀索引,索引字符串的一部分
INDEX index_name ( column(10) ) - 全文索引,查找的是文本中的关键词,而不是直接比较索引中的值,类似于搜索引擎做的事情。
FULLTEXT ( column)
从表现形式角度:
- 主键索引,数据表的主键列使用的就是主键索引。InnoDB中,当没有显式的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。
- 二级 / 辅助索引,除开主键索引之外的都叫二级索引。在MyISAM中二级索引和主键索引的结构大致相同。在InnoDB中二级索引的叶子节点存储的是主键值,通过主键值定位行数据,需要两次索引查找。使用主键值当做指针会让二级索引占更多的空间,但是移动行时无需更新二级索引。
- 覆盖索引,如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, 而无需回表查询。
索引优化SQL排查调优
- 打开慢查询日志,查看慢查询
- 首先在线下环境explain看一下执行计划,是否符合预期,例如查看①key字段是否使用到索引,使用到什么索引。②type字段是否为ALL全表扫描。③row字段扫描的行数是否过大,估计值。MySQL数据单位都是页,使用采样统计方法。④extra字段是否需要额外排序,就是不能通过索引顺序达到排序效果;是否需要使用临时表等。⑤如果是组合索引的话通过key_len字段判断是否被完全使用。
- 了解业务场景。看业务怎么使用这个sql,做针对性优化。
- 排除缓存的干扰。如果线程RT(响应时间)快时慢的话就可能是缓存的问题,因为对表进行更新的话先关缓存都会失效
- 使用覆盖索引。一个索引包含所有需要查询的字段的值。直接根据该索引就可以查到数据,无需回表查询。比如InnoDB二级索引包含主键值,通过二级索引查找主键值就会用到覆盖索引,无需回表
- 使用组合索引。比如根据名称查库存就可以建立联合索引,不需要根据名称查出主键之后在查库存了,但需要考虑业务场景,避免占据较大空间。
- 注意最左前缀原则,按照定义的顺序写sql。如果一个模糊查询只使用到一个组合索引的最左索引,那这样还是能用到这个联合索引,并不需要新建一个单独的索引。
- 选择合适的索引列顺序。当不需要考虑排序和分组时,将选择性最高的列放到索引的最前列通常是很好的。
- 索引下推,mysql5.6之后官方自动优化。比如联合索引(name,age),根据name的like查询并且age在一定区间内查找所有匹配的行数据时,就只有name可以用到索引,age并不会。在优化后,name用到索引之后,会直接再从索引中匹配满足条件的age,之后再回表查询,这样需要回表查询的数据就相比减少了。其实就是充分利用了索引中的数据,尽量在查询出整行数据之前过滤掉无效的数据。
- 使用前缀索引。当要给字符串加索引时,可以使用前缀索引,节省资源占用。如果前缀区分度不高可以倒序存储或者是存储hash。
- 注意隐式类型转换。比如id是字符类型,查询的使用使用int类型会相当于加了类型转换函数,用不上索引。两个表的字符集不一样也会导致,例如utf8mb4(可以超过3字节)和utf8(最多3字节)
- 被频繁更新的字段应该慎重建立索引,不被经常查询的字段没有必要建立索引。
- 遵循索引设计准则三星索引,但一般难以满足,需要依赖实际成本和业务场景。① WHERE 后面参与查询的列可以组成了单列索引或联合索引。② 避免排序,即如果 SQL 语句中出现 order by colulmn,那么取出的结果集就已经是按照 column 排序好的,不需要再生成临时表。③尽量使用覆盖索引
- 注意索引失效场景。
思维导图
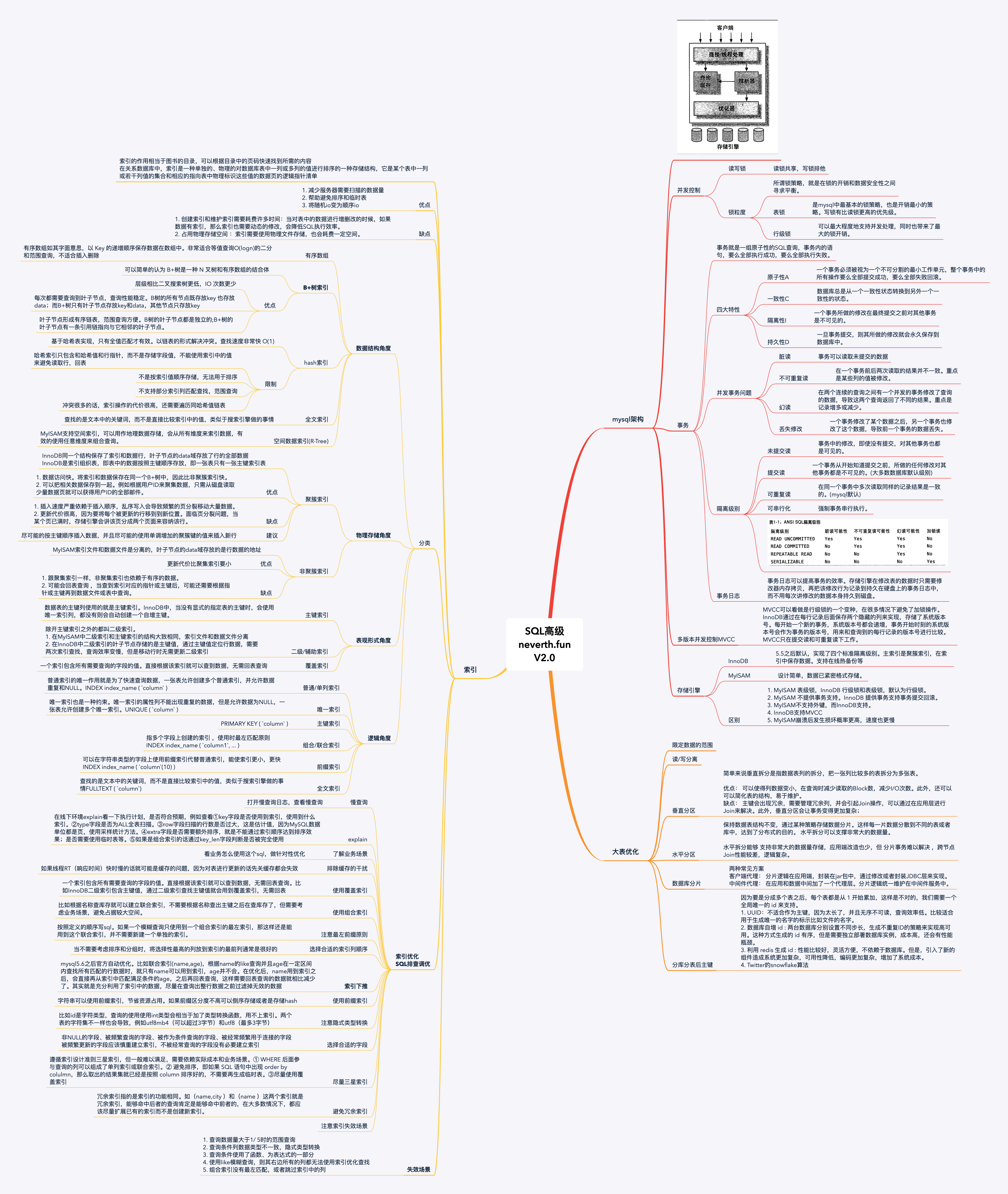
喜欢可以点个赞️️️
SQL精华总结索引类型优化SQL优化事务大表优化思维导图❤️的更多相关文章
- 【SQL server初级】数据库性能优化二:数据库表优化
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第二部分 数据库性能优化二:数据库表优化 优化①:设计规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询 ...
- 优秀后端架构师必会知识:史上最全MySQL大表优化方案总结
本文原作者“ manong”,原创发表于segmentfault,原文链接:segmentfault.com/a/1190000006158186 1.引言 MySQL作为开源技术的代表作之一,是 ...
- MySQL 大表优化方案(长文)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- MySQL 千万级 数据库或大表优化
首先考虑如下因素: 1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数据查询SQL条件:哪些数据项的列名称经常出现在WH ...
- MySQL 上亿大表优化实践
目录 背景 分析 select xxx_record语句 delete xxx_record语句 测试 实施 索引优化后 delete大表优化为小批量删除 总结 背景 XX实例(一主一从)xxx告警中 ...
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
- Hive优化-大表join大表优化
Hive优化-大表join大表优化 5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个 ...
- [原创]Java性能优化权威指南读书思维导图
[原创]Java性能优化权威指南读书思维导图 书名:Java性能优化权威指南 原书名:Java performance 作者: (美)Charlie Hunt Binu John 译者: 柳飞 ...
随机推荐
- 如何将IDM中的进程设置进行备份
有时候我们想用浏览器自带的下载管理器进行下载,但是一点下载却被IDM(Internet Download Manager)自动嗅探捕获并下载,还有人因为重装系统使得之前更改IDM的设置都失效,只得重新 ...
- 下载器Folx教程:智能标签怎么用?
Mac专用下载器Folx的智能标签中内置了图片标签,可以自动分类图片文件,但要如何分类GIF图片呢?其实,我们可以在Folx的标签面板创建动图标签,然后再创建标签专属的下载文件夹,来独立存放GIF格式 ...
- 网络系列之GET与POST请求方式的区别
作为一枚正在学习前端的 小萌新,如果下面哪里有写的不对的话,可以帮我指出来吗,谢谢 1.是基于什么前提的?如果什么前提都没有,不使用任何规范,只考虑语法和理论上的HTTP协议 那么GET和POST几乎 ...
- DFS序专题
牛客专题之DFS序 简介 dfs序: 每个节点在dfs深度优先遍历中的进出栈的时间序列,也就是tarjan算法中的dfn数组. 画个图理解一下: 这棵树的dfs序:1 3 2 4 2 5 6 7 6 ...
- IEEE浮点数标准
IEEE浮点数标准 阅读笔记:Computer System : A Programmmer's Perspective 基本概念 IEEE浮点数标准采用 \[V=(-1)^s\times M\tim ...
- 新手上路之如何选择Java版本
@ 目录 LTS与非LTS LTS 非LTS Java CPU与PSU Java SE.Java EE.Java ME的区别 Java SE Java EE Java ME 每一次JDK上新总有一群人 ...
- 推荐系统实践 0x0a 冷启动问题
什么是冷启动问题 如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动问题.冷启动问题主要分为三类: 用户冷启动 物品冷启动 系统冷启动 下面我们将 ...
- MyBatis-01:环境搭建
MyBatis-01:环境搭建 1.搭建实验数据库 CREATE DATABASE `mybatis`; USE `mybatis`; DROP TABLE IF EXISTS `user`; CRE ...
- 第8.10节 使用__class__查看Python中实例对应的类
一. 语法释义 __class__属性很简单,直接返回实例对应的类.语法如下: 实例. class 当不知道一个实例的类名又想对类的部分内容进行访问时可以使用__class__返回类. 注意:是返回实 ...
- 手写mini版MVC框架
目录 1, Springmvc基本原理流程 2,注解开发 编写测试代码: 目录结构: 3,编写自定义DispatcherServlet中的初始化流程: 3.1 加载配置文件 3.2 扫描相关的类,扫描 ...