【python接口自动化】- logging日志模块
前言:我们之前运行代码时都是将日志直接输出到控制台,而实际项目中常常需要把日志存储到文件,便于查阅,如运行时间、描述信息以及错误或者异常发生时候的特定上下文信息。
logging模块介绍
Python中自带的logging模块提供了标准的日志接口,在debug时使用往往会事半功倍。为什么不直接使用print去输出呢?这种方式对简单的脚本来说有用,对于复杂的系统来说相当于一个花瓶摆设,大量的print输出很容易被遗忘在代码里,并且print是标准输出,这很难从一堆信息里去判断哪些是你需要重点关注的。
logging的优势就在于可以控制日志的级别,把不需要的信息进行过滤,且可以决定它输出到什么地方、如何输出,还可以通过控制等级把特定等级的信息输出到特定的位置等。logging一共分为四个部分:
- Loggers:日志收集器,可供程序直接调用的接口,app通过调用提供的api来记录日志
- Handlers:日志处理器, 决定将日志记录分配至正确的目的地
- Filters:日志过滤器,对日志信息进行过滤, 提供更细粒度的日志是否输出的判断
- Formatters:日志格式器,制定最终记录打印的格式布局
日志等级
logging将logger的等级划分成5个level,由低到高分别是DEBUG、INFO、WARNING、ERROE、CRITICAL,默认是WARNING级别,CRITICAL最高,相关等级说明如下:
| Level | 说明 |
|---|---|
| DEBUG | 输出详细的运行信息,主要用于调试,追踪问题时使用 |
| INFO | 输出正常的运行的信息,一切按预期进行的情况 |
| WARNING | 一些意想不到的或即将会发生的情况,比如警告:内存空间不足,但不影响程序运行 |
| ERROR | 由于某些问题,程序的一些功能会受到影响,还可以继续运行 |
| CRITICAL | 一个严重的错误,表明程序本身可能无法继续运行 |
这些等级的日志中低包含高,比如INFO,会收集INFO及以上等级的日志,DEBUG等级的日志将不进行收集。下面我们来输出这5个等级的日志:
import logging
"""
logging模块默认收集的日志是warning以上等级的
"""
a = 100
logging.debug(a)
logging.info('这是INFO等级的信息')
logging.warning('这是WARNING等级的信息')
logging.error('这是ERROR等级的信息')
logging.critical('这是CRITICAL等级的信息')
输出结果:
C:\software\python\python.exe D:/learn/test.py
WARNING:root:这是WARNING等级的信息
ERROR:root:这是ERROR等级的信息
CRITICAL:root:这是CRITICAL等级的信息
Process finished with exit code 0
日志收集器
日志是怎么被收集和输出的呢?答案就是日志收集器,设置一个收集器,把指等级的日志信息输出到指定的地方,控制台或文件等,其工作过程大致如下:
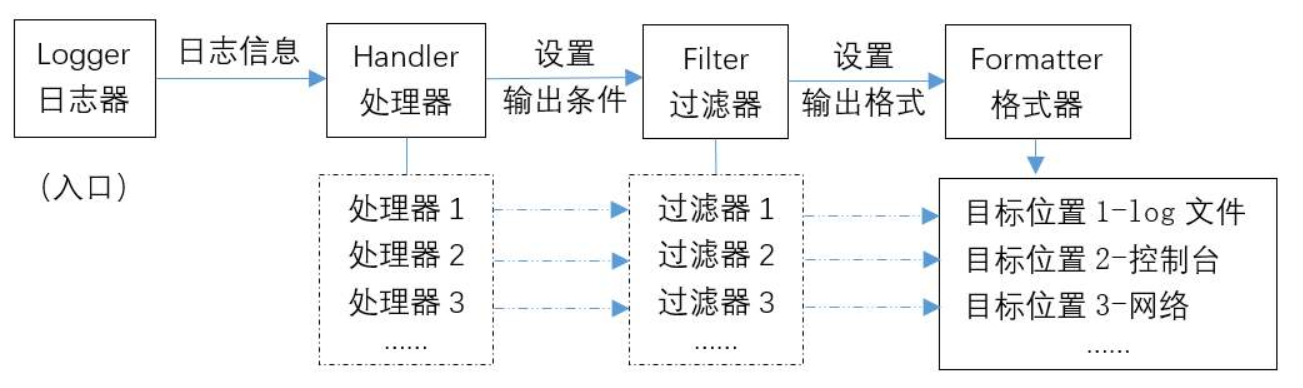
logging中默认的日志收集器是root,收集等级默认是WARNING,我们可以通过setLevel来改变它的收集等级。
# 获取默认的日志收集器root
my_log = logging.getLogger()
# 设置默认的日志收集器等级
my_log.setLevel("DEBUG") # 日志将全部被收集
a = 100
logging.debug(a)
logging.info('这是INFO等级的信息')
logging.warning('这是WARNING等级的信息')
logging.error('这是ERROR等级的信息')
logging.critical('这是CRITICAL等级的信息')
输出结果:
C:\software\python\python.exe D:/learn/test.py
DEBUG:root:100
INFO:root:这是INFO等级的信息
WARNING:root:这是WARNING等级的信息
ERROR:root:这是ERROR等级的信息
CRITICAL:root:这是CRITICAL等级的信息
Process finished with exit code 0
除了使用默认的日志收集器,我们也可以自己创建一个收集器logging.getLogger,如下:
import logging
my_logger = logging.getLogger('my_logger') # 创建logging对象
my_logger.setLevel('INFO') # 设置日志收集等级
a = 100
logging.debug(a)
logging.info('这是INFO等级的信息')
logging.warning('这是WARNING等级的信息')
logging.error('这是ERROR等级的信息')
logging.critical('这是CRITICAL等级的信息')
输出结果:
C:\software\python\python.exe D:/learn/test.py
WARNING:root:这是WARNING等级的信息
ERROR:root:这是ERROR等级的信息
CRITICAL:root:这是CRITICAL等级的信息
Process finished with exit code 0
日志处理器
上面例子中设置的收集器都是输出到控制台,除此我们还可以输出到文件中。
Handlers(处理器)的作用就是将logger发过来的信息进行准确地分配,送往正确的地方。比如,送往控制台、文件或者是两者。它决定了每个日志收集器的行为,是创建收集器之后需要配置的重点区域。每个Handler同样有一个日志级别,一个logger可以拥有多个handler也就是说logger可以根据不同的日志级别将日志传递给不同的handler。当然也可以相同的级别传递给多个handler,这就根据需求来灵活的配置了。
下面实例中设置了两个handler,一个是输出到控制台,一个是输出到文件中。关键代码:
logging.StreamHandler:输出到控制台的处理器logging.FileHandler:输出到文件的处理器addHandler:添加处理器removeHandler:移除处理器
import logging
my_logger = logging.getLogger('my_logger')
my_logger.setLevel('INFO')
# 创建一个输出到控制台的处理器
sh = logging.StreamHandler()
sh.setLevel("ERROR") # 设置处理器的输出等级
my_logger.addHandler(sh) # 将处理器绑定到日志收集器上
# 创建一个输出到文件的处理器
fh = logging.FileHandler("logs.logs", encoding="utf8")
fh.setLevel("INFO")
my_logger.addHandler(fh)
# my_logger.removeHandler(fh) # 移除处理器
a = 100
my_logger.debug(a)
my_logger.info('这是INFO等级的信息')
my_logger.warning('这是WARNING等级的信息')
my_logger.error('这是ERROR等级的信息')
my_logger.critical('这是CRITICAL等级的信息')
运行结果:
C:\software\python\python.exe D:/learn/test.py
这是ERROR等级的信息
这是CRITICAL等级的信息
Process finished with exit code 0

日志过滤器
Filters可以实现比level更复杂的过滤功能,限制只有满足过滤规则的日志才会被输出。比如我们定义了filter = logging.Filter('A.B'),并将这个Filter添加到了一个Handler上,则使用该Handler的Logger中只有名字带A.B前缀的Logger才能输出其日志。下面是一个简单实例:
import logging
# 这是logger1
my_logger = logging.getLogger('A.C,B')
my_logger.setLevel('INFO')
# 这是logger2
my_logger2 = logging.getLogger('A.B')
my_logger2.setLevel('INFO')
# 创建一个处理器,两个logger都使用这个处理器
sh = logging.StreamHandler()
sh.setLevel("ERROR")
my_logger.addHandler(sh)
my_logger2.addHandler(sh)
# 创建一个过滤器绑到处理器上
my_filter = logging.Filter(name='A.B')
sh.addFilter(my_filter) # 把过滤器添加到处理器上
# sh2.removeFilter(my_filter) # 移除过滤器
my_logger.debug('这是logger1-DEBUG等级的信息')
my_logger.info('这是logger1-INFO等级的信息')
my_logger.warning('这是logger1-WARNING等级的信息')
my_logger.error('这是logger1-ERROR等级的信息')
my_logger.critical('这是logger1-CRITICAL等级的信息')
my_logger2.debug('这是logger2-DEBUG等级的信息')
my_logger2.info('这是logger2-INFO等级的信息')
my_logger2.warning('这是logger2-WARNING等级的信息')
my_logger2.error('这是logger2-ERROR等级的信息')
my_logger2.critical('这是logger2-CRITICAL等级的信息')
因为只有logger2满足过滤器的条件,因此只会输出logger2的日志,运行结果如下:
C:\software\python\python.exe D:/learn/test.py
这是logger2-ERROR等级的信息
这是logger2-CRITICAL等级的信息
Process finished with exit code 0
filter方法用于具体控制传递的record记录是否能通过过滤,如果该方法返回值为0表示不能通过过滤,非0表示可以通过过滤。
日志格式器
顾名思义,对日志进行格式化,因为常规的日志输出并不直观美观,通过美化日志的输出格式,可以让我们阅读起来更加舒服。
format常用格式如下:
%(name)s: 打印收集器名称%(levelno)s: 打印日志级别的数值%(levelname)s: 打印日志级别名称%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]%(filename)s: 打印当前执行程序名%(funcName)s: 打印日志的当前函数%(lineno)d: 打印日志的当前行号%(asctime)s: 打印日志的时间%(thread)d: 打印线程ID%(threadName)s: 打印线程名称%(process)d: 打印进程ID%(message)s: 打印日志信息
import logging
my_logger = logging.getLogger('A.C,B')
my_logger.setLevel('INFO')
# 创建一个处理器
sh = logging.StreamHandler()
sh.setLevel("ERROR")
my_logger.addHandler(sh)
# 设置一个格式,并设置到处理器上
formatter = logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
sh.setFormatter(formatter)
my_logger.debug('这是logger1-DEBUG等级的信息')
my_logger.info('这是logger1-INFO等级的信息')
my_logger.warning('这是logger1-WARNING等级的信息')
my_logger.error('这是logger1-ERROR等级的信息')
my_logger.critical('这是logger1-CRITICAL等级的信息')
运行结果:
C:\software\python\python.exe D:/learn/test.py
2020-08-01 18:28:43,645 - [test.py-->line:17] - ERROR: 这是logger1-ERROR等级的信息
2020-08-01 18:28:43,645 - [test.py-->line:18] - CRITICAL: 这是logger1-CRITICAL等级的信息
Process finished with exit code 0
日志滚动
如果你用 FileHandler 存储日志,文件的大小会随着时间推移而不断增大,最终有一天它会占满你所有的磁盘空间。Python 的 logging 模块提供了两个支持日志滚动的 FileHandler 类,分别是 RotatingFileHandler 和 TimedRotatingFileHandler,它就可以解决这个尴尬的问题。
- RotatingFileHandler 的滚动时刻是日志文件的大小达到一定值,当达到指定值的时候,RotatingFileHandler会将日志文件重命名存档,然后打开一个新的日志文件。
- TimedRotatingFileHandler 是当某个时刻到来时就进行滚动,同 RotatingFileHandler 一样,当滚动时机来临时,TimedRotatingFileHandler 会将日志文件重命名存档,然后打开一个新的日志文件。
在实际应用中,我们通常会根据时间进行滚动,以下实例也以时间滚动为例,按大小滚动的同理:
import logging
from logging.handlers import TimedRotatingFileHandler
my_logger = logging.getLogger('A.C,B')
my_logger.setLevel('INFO')
# 创建一个处理器,使用时间滚动的文件处理器
log_file_handler = TimedRotatingFileHandler(filename='log.log', when='D', interval=1, backupCount=10)
# log_file_handler.suffix = "%Y-%m-%d"
# log_file_handler.extMatch = re.compile(r"^\d{4}-\d{2}-\d{2}.log$")
log_file_handler.setLevel("ERROR")
my_logger.addHandler(log_file_handler)
# 设置一个格式,并设置到处理器上
formatter = logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
log_file_handler.setFormatter(formatter)
my_logger.debug('这是logger1-DEBUG等级的信息')
my_logger.info('这是logger1-INFO等级的信息')
my_logger.warning('这是logger1-WARNING等级的信息')
my_logger.error('这是logger1-ERROR等级的信息')
my_logger.critical('这是logger1-CRITICAL等级的信息')
参数说明:
filename:日志文件名;when:是一个字符串,用于描述滚动周期的基本单位,字符串的值及意义如下:- S - Seconds
- M - Minutes
- H - Hours
- D - Days
- midnight - roll over at midnight
- W{0-6} - roll over on a certain day; 0 - Monday
interval: 滚动周期,单位由when指定,比如:when='D',interval=1,表示每天产生一个日志文件;backupCount: 表示日志文件的保留个数;
除了上述参数之外,TimedRotatingFileHandler还有两个比较重要的成员变量,它们分别是suffix和extMatch。suffix是指日志文件名的后缀,suffix中通常带有格式化的时间字符串,filename和suffix由“.”连接构成文件名(例如:filename="test", suffix="%Y-%m-%d.log",生成的文件名为test.2020-08-01.log。extMatch是一个编译好的正则表达式,用于匹配日志文件名的后缀,它必须和suffix是匹配的,如果suffix和extMatch匹配不上的话,过期的日志是不会被删除的。比如,suffix=“%Y-%m-%d.log”, extMatch的只能是re.compile(r"^\d{4}-\d{2}-\d{2}.log$")。默认情况下,在TimedRotatingFileHandler对象初始化时,suffxi和extMatch会根据when的值进行初始化:
S:suffix="%Y-%m-%d_%H-%M-%S",extMatch=r"\^d{4}-\d{2}-\d{2}_\d{2}-\d{2}-\d{2}";
M:suffix="%Y-%m-%d_%H-%M",extMatch=r"^\d{4}-\d{2}-\d{2}_\d{2}-\d{2}";
H:suffix="%Y-%m-%d_%H",extMatch=r"^\d{4}-\d{2}-\d{2}_\d{2}";
D:suffxi="%Y-%m-%d",extMatch=r"^\d{4}-\d{2}-\d{2}";
MIDNIGHT:"%Y-%m-%d",extMatch=r"^\d{4}-\d{2}-\d{2}";
W:"%Y-%m-%d",extMatch=r"^\d{4}-\d{2}-\d{2}";
如果对日志文件名没有特殊要求的话,可以不用设置suffix和extMatch,如果需要,一定要让它们匹配上。
模块封装
一次封装,一劳永逸,之后直接调用即可,封装内容按需即可。
import logging
from logging.handlers import TimedRotatingFileHandler
class MyLogger(object):
@staticmethod
def create_logger():
my_logger = logging.getLogger("my_logger")
my_logger.setLevel("DEBUG")
# 控制台处理器
stream_handler = logging.StreamHandler()
stream_handler.setLevel("ERROR")
my_logger.addHandler(stream_handler)
# 使用时间滚动的文件处理器
log_file_handler = TimedRotatingFileHandler(filename='log.log', when='D', interval=1, backupCount=10)
log_file_handler.setLevel("INFO")
my_logger.addHandler(log_file_handler)
formatter = logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
stream_handler.setFormatter(formatter)
log_file_handler.setFormatter(formatter)
return my_logger
# 调用类的静态方法,创建一个日志收集器
log = MyLogger.create_logger()
log.info("test-info")
log.error("test-error")
运行结果:
C:\software\python\python.exe D:/learn/test.py
2020-08-01 18:29:45,645 - [test.py-->line:28] - ERROR: test-error
Process finished with exit code 0
【python接口自动化】- logging日志模块的更多相关文章
- python中的logging日志模块
日志是程序不可或缺的一部分.它可以记录程序的运行情况,帮助我们更便捷地发现问题,而python中的logging日志模块给我们提供了这个机会. logging给我们提供了五种函数用来输出日志:debu ...
- Python入门之logging日志模块以及多进程日志
本篇文章主要对 python logging 的介绍加深理解.更主要是 讨论在多进程环境下如何使用logging 来输出日志, 如何安全地切分日志文件. 1. logging日志模块介绍 python ...
- python 自动化之路 logging日志模块
logging 日志模块 http://python.usyiyi.cn/python_278/library/logging.html 中文官方http://blog.csdn.net/zyz511 ...
- Python logging(日志)模块
python日志模块 内容简介 1.日志相关概念 2.logging模块简介 3.logging模块函数使用 4.logging模块日志流处理流程 5.logging模块组件使用 6.logging配 ...
- python中的第三方日志模块logging
基本上每个系统都有自己的日志系统,可以使自己写的,也可以是第三方的.下面来简单介绍一下python中第三方的日志模块,入手还是比较简单的,但是也很容易给自己埋雷. 下面是我参考的资料链接 入手demo ...
- Python 中 logging 日志模块在多进程环境下的使用
因为我的个人网站 restran.net 已经启用,博客园的内容已经不再更新.请访问我的个人网站获取这篇文章的最新内容,Python 中 logging 日志模块在多进程环境下的使用 使用 Pytho ...
- python接口自动化(四十)- logger 日志 - 下(超详解)
简介 按照上一篇的计划,这一篇给小伙伴们讲解一下:(1)多模块使用logging,(2)通过文件配置logging模块,(3)自己封装一个日志(logging)类.可能有的小伙伴在这里会有个疑问一个l ...
- 约束、自定义异常、hashlib模块、logging日志模块
一.约束(重要***) 1.首先我们来说一下java和c#中的一些知识,学过java的人应该知道,java中除了有类和对象之外,还有接口类型,java规定,接口中不允许在方法内部写代码,只能约束继承它 ...
- pyhton——logging日志模块的学习
https://www.cnblogs.com/yyds/p/6901864.html 本节内容 日志相关概念 logging模块简介 使用logging提供的模块级别的函数记录日志 logging模 ...
- logging日志模块详细,日志模块的配置字典,第三方模块的下载与使用
logging日志模块详细 简介 用Python写代码的时候,在想看的地方写个print xx 就能在控制台上显示打印信息,这样子就能知道它是什么 了,但是当我需要看大量的地方或者在一个文件中查看的时 ...
随机推荐
- Docker-教你如何通过 Docker 快速搭建各种测试环境
今天给大家分享的主题是,如何通过 Docker 快速搭建各种测试环境,本文列举的,也是作者在工作中经常用到的,其中包括 MySQL.Redis.Elasticsearch.MongoDB 安装步骤,通 ...
- 蒲公英 · JELLY技术周刊 Vol.13 跟 VSCode 学习如何开发大型 IDE 项目
开发一个 IDE 很难么?这或许是件很难的事情,但当我们参考 VSCode 的技术构架来看,整个开发流程就会平滑顺畅很多,从内核开发.代码编辑器.视图结构到插件系统,在这整个技术构架中我们可以看到很多 ...
- Python 字符串改变
在Python中,字符串是不可变类型,即无法直接修改字符串的某一位字符. 因此改变一个字符串的元素需要新建一个新的字符串. 常见的修改方法有以下4种. 方法1:将字符串转换成列表后修改值,然后用joi ...
- linux常用命令 总结
最最常用的快捷键,Tab 键 ,自动补全功能, / 根目录 man 帮助手册:man cd ,查看cd的用法! cd 进入目录:ls -l 列表查看文件详细信息:pwd 当前路径: cp 复制 .rm ...
- 数据可视化之分析篇(九)PowerBI数据分析实践第三弹 | 趋势分析法
https://zhuanlan.zhihu.com/p/133484654 以财务报表分析为例,介绍通用的分析方法论,整体架构如下图所示: (点击查看大图) 我会围绕这五种不同的方法论,逐步阐述他们 ...
- Kafka Eagle V2.0.0新版预览
1.概述 Kafka Eagle是一款用于管理Kafka的监控系统,且完全开源.当前Kafka Eagle发布了2.0.0版本.今天笔者就为大家来介绍一下2.0.0更新了哪些功能. 官网地址:http ...
- Apache Kylin v3.1.0 重点功能推介
Apache Kylin v3.1.0 已于上周正式发布,其中包含了许多值得一试的新功能,本文选择了 Presto 查询下压引擎.Flink 构建引擎.Kylin on Kubernetes 解决方案 ...
- Python Ethical Hacking - TROJANS Analysis(5)
Spoofing File Extention - A trick. Use the Kali Linux Program - Characters 1. Open the program. 2. F ...
- python pytest接口自动化框架搭建(一)
1.首先安装pytest pip install pytest 2.编写单测用例 在pytest框架中,有如下约束: 所有的单测文件名都需要满足test_*.py格式或*_test.py格式. 在单测 ...
- 直接在x86硬件上显示图片(无os)
1 任务 为了学习计算机底层和os,我给自己布置了一个任务:在x86硬件上,使用c和nasm来显示一张bmp图片.完成这个任务,前后估计花了2个月的业余时间. 这个任务涉及了很多知识点,包括:启动区. ...