数据分析学习 third week (7.29~8.4)
概率分布简介
简单地介绍下常用概率分布的理论知识。
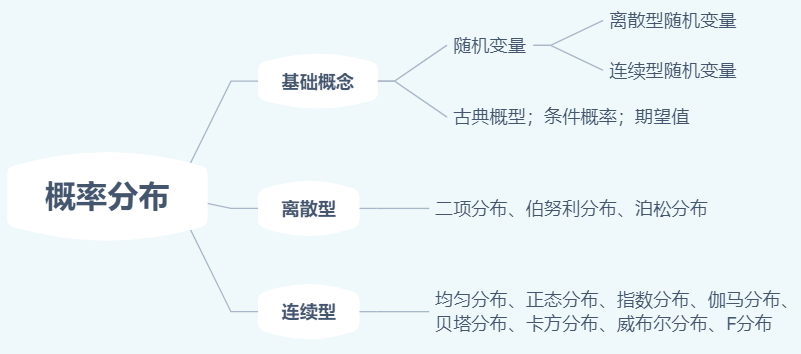
基础概念
1.概率
概率直观上是指一个事件发生可能性大小的数量指标
概率的统计定义:在不变的条件下,重复进行$n$次试验,事件$A$发生的频率稳定在某一个常数$p$附近摆动,且一般来说,$n$越大,摆动幅度越小,则称常数$p$为事件$A $的概率,记作$P(A)=p$.
2.古典概型
当试验结果为有限$n$个样本点,且每个样本点的发生具有相等的可能性,如果事件A由$n_{A}$个样本点组成,则事件$A$的概率
$P(A)=\frac{n_{A}}{n}$
称有限等可能实验中事件$A $的概率$P(A)$为古典概率.
4.随机变量
定义:在样本空间$\Omega$上的实值函数$X=X(\omega), \omega \in \Omega$,称$X(\omega)$为随机变量,简记$X$.
4.1 离散型随机变量
离散型(discrete)随机变量即在一定区间内变量取值为有限个或可数个。
4.2 连续型随机变量
连续型(continuous)随机变量即在一定区间内变量取值有无限个,或数值无法一一列举出来。
定义:如果对随机变量$X$的分布函数$F(x)$,存在一个非负可积函数$f(x)$,使得对任意实数$x$,都有
$F(X)=\int_{-\infty}^{x} f(t) d t,-\infty<x<+\infty$
称$X$为连续型随机变量,函数$f(x)$称为$X$的概率密度。
4.3 期望
离散型
如果$X$是离散随机变量,具有概率质量函数$p(x)$,那么X的期望值定义为$E(X)=\sum_{x : p(x)>0} x p(x)$。换句话说,$X$的期望是$X$可能取的值的加权平均,每个值被$X$取此值的概率所加权。
连续型
我们也可以定义连续随机变量的期望值。如果$X$是具有概率密度函数$f(x)$的连续随机变量,那么$X$的期望就定义为$E(X)=\int_{\alpha}^{\beta} \frac{x}{\beta-\alpha} d x=\frac{\beta^{2}-\alpha^{2}}{2(\beta-\alpha)}=\frac{\beta+\alpha}{2}$。换句话说,在$(\alpha, \beta)$上均匀分布的随机变量的期望值正是区间的中点。
常用概率分布
1.二项分布
$n$重伯努利试验
定义:把一随机试验独立重复作若干,即各次试验所联系的事件之间相互独立,且同一事件在各个实验中出现的概率相同,称为独立重复试验。
如果每次试验只有两个结果$A$和$\overline{A}$,则称这种试验为伯努利试验。将伯努利试验独立重复$n$次,称为$n$重伯努利试验。
设在每次试验中,概率$P(A)=p(0<p<1)$,则在$n$重伯努利试验中事件$A$发生$k$次的概率,又称为二项概率公式:$C_{n}^{k} p^{k}(1-p)^{n-k}, k=0,1,2, \cdots, n$。
二项分布
如果随机变量$X$有分布律
$P\{X=k\}=C_{n}^{k} p^{k}(1-p)^{n-k}, k=0,1,2, \cdots, n$
其中$0<p<1,q=1-p$,则称X服从参数为$n,p$的二项分布,记作$X~B(n,p)$.
二项分布就是重复$n$次独立的伯努利试验。在$n$次伯努利试验中,若每次试验成功率$p(0<p<1)$,则在$n$次独立重复试验中成功的总次数$X$服从二项分布。
当$n=1$时,二项分布为$0-1$分布,记$B(1,p)$
期望:$E(gX)=np$,方差:$D(X)=np(1-p)$
2.泊松分布
泊松分布的概率函数为:
$P(X=k)=\frac{\lambda^{k}}{k !} e^{-\lambda}, k=0,1, \cdots$
泊松分布的参数$\lambda$是单位时间(或单位面积)内随机事件的平均发生次数。 泊松分布适合于描述单位时间内随机事件发生的次数。
泊松分布的期望和方差均为$\lambda$特征函数为$\psi(t)=\exp \left\{\lambda\left(e^{i t}-1\right)\right\}$
泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等
3.均匀分布
在概率论和统计学中,均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。 均匀分布由两个参数$a$和$b$定义,它们是数轴上的最小值和最大值,通常缩写为$U(a,b)$.
概率密度函数:
$f(x)=\left\{\begin{array}{ll}{\frac{1}{b-a},} & {a<x<b} \\ {0} & {其他]}\end{array}\right.$
在两个边界$a$和$b$处的$f(x)$的值通常是不重要的,因为它们不改变任何$f(x) d x$的积分值。 概率密度函数有时为0,有时为$\frac{1}{b-a}$。 在傅里叶分析的概念中,可以将$f(a)$或$f(b)$的值取为$\frac{1}{2(b-a)}$,因为这种均匀函数的许多积分变换的逆变换都是函数本身。
分布函数:
$F(x)=\left\{\begin{array}{ll}{0,} & {x<a} \\ {\frac{1}{b-a},} & {a \leq x<b} \\ {1,} & {b \leq x}\end{array}\right.$
令$X_{1}, \ldots, X_{n}$是服从于$U(0,1)$的样本。 令$X(k)$为该样本的第$k$次统计量。 那么$X(k)$的概率分布是参数为$k$和$n-k+1$的β分布。期望值是:
$E\left(X_{(k)}\right)=\frac{k}{n+1}$
方差是:
$V\left(X_{(k)}\right)=\frac{k(n-k+1)}{(n+1)^{2}(n+2)}$
4.指数分布
在概率理论和统计学中,指数分布(也称为负指数分布)是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。 这是伽马分布的一个特殊情况。 它是几何分布的连续模拟,它具有无记忆的关键性质。
随机变量$X$概率密度函数:
$f(x)=\left\{\begin{array}{ll}{\lambda e^{-\lambda x},} & {x>0} \\ {0,} & {x \leq 0}\end{array} \quad \lambda>0\right.$
设$X \sim E(\lambda)$,则$X$的分布函数:
$F(x)=\left\{\begin{array}{ll}{1-e^{-\lambda x},} & {x>0}, \\ {0,} & {x \leq 0}, \end{array} \lambda>0\right.$
期望值:$E(X)=\frac{1}{\lambda}$
方差:$D(X)=\operatorname{Var}(X)=\frac{1}{\lambda^{2}}$
指数分布是一种连续概率分布。指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进机场的时间间隔、中文维基百科新条目出现的时间间隔等
5.正态分布
若随机变量$X$服从一个位置参数为$\mu$、尺度参数为$\sigma$的概率分布,且其概率密度函数为
$f(x)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)$
则这个随机变量就称为正态随机变量,正态随机变量服从的分布就称为正态分布,记作$X \sim N\left(\mu, \sigma^{2}\right)$,读作
服从$N\left(\mu, \sigma^{2}\right)$,或$X$服从正态分布。
参数含义
正态分布有两个参数,即期望(均数)$\mu$和标准差$\sigma$,$\sigma^2$为方差。
$\mathrm{f}(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}$
正态分布具有两个参数$\mu$和$\sigma^2$的连续型随机变量的分布,第一参数$\mu$是服从正态分布的随机变量的均值,第二个参数$\sigma^2$是此随机变量的方差,所以正态分布记作$\mathrm{N}(\mu, \sigma 2)$.
$\mu$是正态分布的位置参数,描述正态分布的集中趋势位置。概率规律为取与$\mu$邻近的值的概率大,而取离$\mu$越远的值的概率越小。正态分布以$X=\mu$为对称轴,左右完全对称。正态分布的期望、均数、中位数、众数相同,均等于$\mu$。
当$\mu=0, \sigma=1$时,正态分布就成为标准正态分布
$f(x)=\frac{1}{\sqrt{2 \pi}} e^{(-\frac{x^{2}}{2} )}$
概率论中最重要的分布
正态分布有极其广泛的实际背景,生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。例如,在生产条件不变的情况下,产品的强力、抗压强度、口径、长度等指标;同一种生物体的身长、体重等指标;同一种种子的重量;测量同一物体的误差;弹着点沿某一方向的偏差;某个地区的年降水量;以及理想气体分子的速度分量,等等。一般来说,如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分布(见中心极限定理)。从理论上看,正态分布具有很多良好的性质 ,许多概率分布可以用它来近似;还有一些常用的概率分布是由它直接导出的,例如对数正态分布、t分布、F分布等
6.$\chi^{2}$分布
若n个相互独立的随机变量ξ₁、ξ₂、……、ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这$n$个服从标准正态分布的随机变量的平方和$Q=\sum_{i=1}^{n} \xi_{i}^{2}$构成一新的随机变量,其分布规律称为$\chi^{2}$分布(chi-square distribution),其中参数
称为自由度,正如正态分布中均数或方差不同就是另一个正态分布一样,自由度不同就是另一个$\chi^{2}$分布。记为$Q\sim \chi^{2}(v)$或者$Q \sim \chi_{v}^{2}$(其中$v=n-k,k$为限制条件数)。
卡方分布是由正态分布构造而成的一个新的分布,当自由度
很大时,$\chi^{2}$分布近似为正态分布。
7.Beta分布
在概率论中,贝塔分布,也称B分布,是指一组定义在$(0,1)$区间的连续概率分布,有两个参数$\alpha, \beta>0$。
B分布的概率分布函数为:
$f(x ; \alpha, \beta)=\frac{x^{\alpha-1}(1-x)^{\beta-1}}{\int_{0}^{1} u^{\alpha-1}(1-u)^{\beta-1} d u}=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha) \Gamma(\beta)} x^{\alpha-1}(1-x)^{\beta-1}=\frac{1}{B(\alpha, \beta)} x^{\alpha-1}(1-x)^{\beta-1}$
其中$\Gamma(z)$是$\Gamma$函数。随机变量$X$服从参数为$\alpha, \beta$的Β分布通常写作$X \sim \operatorname{Be}(\alpha, \beta)$
性质:
1. 参数为$\alpha, \beta$贝塔分布的众数是:
$\frac{\alpha-1}{\alpha+\beta-2}$
2.期望值和方差分别是:
$\mu=\mathrm{E}(X)=\frac{\alpha}{\alpha+\beta}$
$\operatorname{Var}(X)=\mathrm{E}(X-\mu)^{2}=\frac{\alpha \beta}{(\alpha+\beta)^{2}(\alpha+\beta+1)}$
3.偏度是:
$\frac{\mathrm{E}(X-\mu)^{3}}{\left[\mathrm{E}(X-\mu)^{2}\right]^{3 / 2}}=\frac{2(\beta-\alpha) \sqrt{\alpha+\beta+1}}{(\alpha+\beta+2) \sqrt{\alpha \beta}}$
4.峰度是:
$\frac{\mathrm{E}(X-\mu)^{4}}{\left[\mathrm{E}(X-\mu)^{2}\right]^{2}}-3=\frac{6\left[\alpha^{3}-\alpha^{2}(2 \beta-1)+\beta^{2}(\beta+1)-2 \alpha \beta(\beta+2)\right]}{\alpha \beta(\alpha+\beta+2)(\alpha+\beta+3)}$
或:
$\frac{6\left[(\alpha-\beta)^{2}(\alpha+\beta+1)-\alpha \beta(\alpha+\beta+2)\right]}{\alpha \beta(\alpha+\beta+2)(\alpha+\beta+3)}$
数据分析学习 third week (7.29~8.4)的更多相关文章
- Python数据分析学习目录
python数据分析学习目录 Anaconda的安装和更新 矩阵NumPy pandas数据表 matplotlib-2D绘图库学习目录
- Python数据分析学习(二):Numpy数组对象基础
1.1数组对象基础 .caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { bord ...
- 数据分析学习(zhuan)
http://www.zhihu.com/question/22119753 http://www.zhihu.com/question/20757000 ********************** ...
- spart快速大数据分析学习提纲(一)
Spart是什么 Spart是一个用来实现快速而而通用的集群计算平台. 在速度方面,Spart扩展了广泛使用的Mapreduce计算模型,而且高效的支持更多的计算模式,包括交互式查询和流处理.Spar ...
- Python数据分析学习-re正则表达式模块
正则表达式 为高级的文本模式匹配.抽取.与/或文本形式的搜索和替换功能提供了基础.简单地说,正则表达式(简称为 regex)是一些由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符,于 ...
- Python数据分析学习之Numpy
Numpy的简单操作 import numpy #导入numpy包 file = numpy.genfromtxt("文件路径",delimiter=" ",d ...
- 【数据分析学习】Pandas学习记录
import pandas as pd path = r'F:\数据分析专用\数据分析与机器学习\food_info.csv' with open(path, 'r') as f: data = pd ...
- 【数据分析学习】016-numpy数据结构
通常对数据的矩阵进行操作,就用numpy操作,打开txt文件 使用help()去查询文档,可以看到官方的注释 import numpy path = r'F:\数据分析专用\数据分析与机器学习\wor ...
- 重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL.推出KSQL 是为了降低流式处理的门槛,为处理 ...
随机推荐
- 隐写术工具之binwalk
0x00Binwalk介绍 Binwalk是用于搜索给定二进制镜像文件以获取嵌入的文件和代码的工具. 具体来说,它被设计用于识别嵌入固件镜像内的文件和代码. Binwalk使用libmagic库,因此 ...
- kubernetes系列(十二) - 存储之Secret
1. Secret简介 2. Secret类型 3. Service Account 4. Opaque 4.1 Opaque类型说明 4.2 Opaque创建方式 4.2.1 命令行创建 4.2.2 ...
- 配置类需要标注@Configuration却不知原因?那这次就不能给你涨薪喽
专注Java领域分享.成长,拒绝浅尝辄止.关注公众号[BAT的乌托邦]开启专栏式学习,拒绝浅尝辄止.本文 https://www.yourbatman.cn 已收录,里面一并有Spring技术栈.My ...
- day46 mysql进阶
目录 一.约束条件 1 default默认值 2 unique唯一 2.1 单列唯一 2.2 联合唯一 3 primary key主键 3.1 主键的基本使用 3.2 主键的特性 4 auto_inc ...
- Django框架01 / http协议、web框架本质
Django框架01 / http协议.web框架本质 目录 Django框架01 / http协议.web框架本质 1.http协议 1.1 http协议简介 1.2 什么是http协议 1.3 H ...
- 使用Python来写mock代码(桩代码)-其实很简单
1.Mock基本用法 使用Mock能创建你能访问(模拟)的属性和方法 指定类或者函数的返回值和断言方式 创建handle_mock_01.py文件 # 1. 导入mock模块 from unittes ...
- Ethical Hacking - NETWORK PENETRATION TESTING(11)
Securing your Network From the Above Attacks. Now that we know how to test the security of all known ...
- Python Ethical Hacking - VULNERABILITY SCANNER(5)
EXPLOITATION - XSS VULNS XSS - CROSS SITE SCRIPTING VULNS Allow an attacker to inject javascript cod ...
- 记录一次升级ant-design-vue的遇见的bug
记录一次升级ant-design-vue的遇见的bug 使用版本: "version": "2.5.2" "ant-design-vue": ...
- ant design pro 实战 : 使用 ztree
应当指出,antd 是有 ztree 组件的,但是太简单,无法满足复杂的业务需求. 所以我还是决定使用zTree. 用 npm | cnpm 或者 yarn | tyarn 安装,这一步略. 在 js ...