【小白学AI】八种应对样本不均衡的策略
文章来自:微信公众号【机器学习炼丹术】
1 什么是非均衡
分类(classification)问题是数据挖掘领域中非常重要的一类问题,目前有琳琅满目的方法来完成分类。然而在真实的应用环境中,分类器(classifier)扮演的角色通常是识别数据中的“少数派”,比如:
- 银行识别信用卡异常交易记录
- 垃圾邮件识别
- 检测流水线识别残次品
- 病情监测与识别等等
在这样的应用环境下,作为少数派的群组在数据总体中往往占了极少的比例:绝大多数的信用卡交易都是正常交易,八成以上的邮件都是正常邮件,大多数的流水线产品是合格产品,在进行检查的人群中特定疾病的发病率通常非常低。
如果这样的话,假设99%的正样本+1%的负样本构成了数据集,那么假设模型的预测结果全是正,这样的完全没有分辨能力的模型也可以得到99%的准确率。这个按照样本个数计算准确率的评价指标叫做——Accuracy.
因此我们为了避免这种情况,最常用的评价指标就是F-score,Precision&Recal,Kappa系数。
【F-Score和Kappa系数已经在历史文章中讲解过啦】
2 8种解决办法
解决办法主要有下面10种不同的方法。
- 重采样resampling
- 上采样:简单上采样,SMOT,ADASYN
- 下采样:简单下采样,聚类Cluter,Tomek links
- 调整损失函数
- 异常值检测框架
- 二分类变成多分类
- EasyEnsemble
2.1 重采样(四种方法)
重采样的目的就是让少的样本变多,或者是让多的样本变少。下图很形象的展示出这个过程:
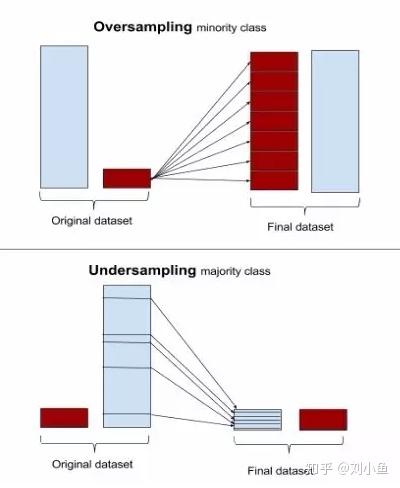
【简单上采样】
就是有放回的随机抽取少数量的样本,饭后不断复制抽取的随机样本,直到少数量的样本与多数量的样本处于同一数量级。但是这样容易造成过拟合问题。
为什么会造成过拟合呢? 最极端的例子就是把一个样本复制100次,这样就有了一个100样本的数据库。模型训练出来很可能得到100%的正确率,但是这模型真的学到东西了吗?
【SMOTE】
- SMOT:Synthetic Minority Over-sampling Technique.(翻译成中文,合成最少个体上采样技术?)
核心思想是依据现有的少数类样本人为制造一些新的少数类样本 SMOTE在先用K近邻算法找到K个近邻,利用这个K个近邻的各项指标,乘上一个0~1之间的随机数就可以组成一个新的少数类样本。容易发现的是,就是SMOTE永远不会生成离群样本
【ADASYN】
- ADASYN:Adaptive Synthetic Sampling Approach(自适应合成样本方法)
ADASYN其实是SMOTE的一种衍生技术,相比SMOT在每一个少数类样本的周围随机的创建样本,ADASYN给每一个少数类的样本分配了权重,在学习难度较高的少数类样本周围创建更多的样本。在K近邻分类器分类错误的那些样本周围生成更多的样本,也就是给他们更大的权重,而并不是随机0~1的权重。
这样的话,就好像,一个负样本周围有正样本,经过这样的处理后,这个负样本周围会产生一些相近的负样本。这样的弊端也是显而易见的,就是对离群点异常敏感。
【简单下采样】
这个很简单,就是随机删除一些多数的样本。弊端自然是,样本数量的减少,删除了数据的信息
【聚类】
这个是一个非常有意思的方法。我们先选取样本之间相似度的评估函数,比方说就用欧氏距离(可能需要对样本的数据做归一化来保证不同特征的同一量纲)。
方法1:假设有10个负样本和100个正样本,对100个正样本做kmeans聚类,总共聚10个类出来,然后每一个类中心作为一个正样本。
方法2:使用K近邻,然后用K个样本的中心来代替原来K个样本。一直这样做,直到正样本的数量等于负样本的数量。
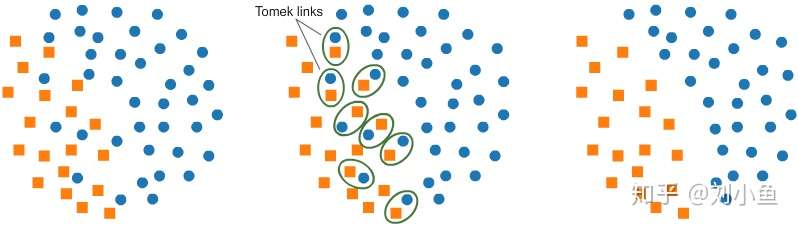
【Tomek links】
- 这个不知道咋翻译
Tomek links是指相反类样本的配对,这样的配对距离非常近,也就是说这样的配对中两个样本的各项指标都非常接近,但是属于不同的类。如图所示,这一方法能够找到这样的配对,并删除配对中的多数类样本。经过这样的处理,两类样本之间的分界线变得更加清晰,使少数类的存在更加明显。
下图是操作的过程。
2.2 调整损失函数
调整损失函数的目的本身是为了使模型对少数量样本更加敏感。训练任何一个机器学习模型的最终目标是损失函数(loss function)的最小化,如果能够在损失函数中加大错判少数类样本的损失,那么模型自然而然能够更好地识别出少数类样本。
比较著名的损失函数就是目标检测任务中的focal loss。不过在处理其他任务的时候,也可以人为的增加少数样本错判的损失。
2.3 异常值检测框架
- 将分类问题转换成为一个异常值监测框架
这个异常值检测框架又是一个非常大的体系,有很多不同的模型,比方说:异常森立等。之后会专门讲讲这个体系的模型的。
(小伙伴关注下公众号呗,不迷路呀)
2.4 二分类变成多分类
对于不均衡程度较低的数据,可以将多数量样本进一步分为多个组,虽然二分类问题被转化成了一个多分类问题,但是数据的不平衡问题被解决,接下来就可以使用多分类中的一对多(OVA)或一对一(OVO)的分类方式进行分类。
就是把多数类的样本通过聚类等方法,划分成不同的类别。这样2分类任务就变成了多分类任务。
2.5 EasyEnsemble
另外一种欠采样的改进方法是 EasyEnsemble ,它将多数样本划分成若 N个集合,然后将划分过后的集合与少数样本组合,这样就形成了N个训练集合,而且每个训练都正负样本均衡,并且从全局来看却没有信息丢失。
【小白学AI】八种应对样本不均衡的策略的更多相关文章
- 【小白学AI】GBDT梯度提升详解
文章来自微信公众号:[机器学习炼丹术] 文章目录: 目录 0 前言 1 基本概念 2 梯度 or 残差 ? 3 残差过于敏感 4 两个基模型的问题 0 前言 先缕一缕几个关系: GBDT是gradie ...
- 【小白学AI】XGBoost 推导详解与牛顿法
文章转自公众号[机器学习炼丹术],关注回复"炼丹"即可获得海量免费学习资料哦! 目录 1 作者前言 2 树模型概述 3 XGB vs GBDT 3.1 区别1:自带正则项 3.2 ...
- 【小白学AI】随机森林 全解 (从bagging到variance)
文章转自公众号[机器学习炼丹术],关注回复"炼丹"即可获得海量免费学习资料哦! 目录 1 随机森林 2 bagging 3 神秘的63.2% 4 随机森林 vs bagging 5 ...
- 【小白学AI】XGBoost推导详解与牛顿法
文章来自微信公众号:[机器学习炼丹术] 目录 1 作者前言 2 树模型概述 3 XGB vs GBDT 3.1 区别1:自带正则项 3.2 区别2:有二阶导数信息 3.3 区别3:列抽样 4 XGB为 ...
- 【小白学AI】线性回归与逻辑回归(似然参数估计)
文章转自[机器学习炼丹术] 线性回归解决的是回归问题,逻辑回归相当于是线性回归的基础上,来解决分类问题. 1 公式 线性回归(Linear Regression)是什么相比不用多说了.格式是这个样子的 ...
- LVS负载均衡的三种模式和八种算法总结
三种LVS负载均衡模式 调度器的实现技术中,IP负载均衡技术是效率最高的,IP虚拟服务器软件(IPVS)是在linux内核中实现的。 LVS负载均衡模式---1.NAT模式 NAT用法本来是因为网络I ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 数据分析(9):Pandas (八)数据预处理(2)
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- 小白学 Python 数据分析(10):Pandas (九)数据运算
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
随机推荐
- Python函数03/函数名的第一类对象及使用/f 格式化/迭代器/递归
Python函数03/函数名的第一类对象及使用/f 格式化/迭代器/递归 目录 Python函数03/函数名的第一类对象及使用/f 格式化/迭代器/递归 内容纲要 1.函数名的第一类对象及使用 2.f ...
- 【高性能Mysql 】读书笔记(三)
第5章 创建高性能的索引 本文为<高性能Mysql 第三版>第四章读书笔记,Mysql版本为5.5 索引基础 索引的重要性:找一本800面的书的某一段内容,没有目录也没有页码(页码也可类比 ...
- Python 爬取 42 年高考数据,告诉你高考为什么这么难?
作者 | 徐麟 历年录取率 可能很多经历过高考的人都不知道高考的全称,高考实际上是普通高等学校招生全国统一考试的简称.从1977年国家恢复高考制度至今,高考经历了许多的改革,其中最为显著的变化就是录取 ...
- 数据结构C语言实现----出栈操作
代码如下: #include<stdio.h> #include<stdlib.h> typedef struct { char *base; char *top; int s ...
- oracle 在物理机上添加磁盘操作
物理机上添加磁盘操作 注意:1)物理机上添加磁盘操作,不涉及到start_udev的动作.2)磁盘分区的操作,需要谨慎进行,核准无误后再操作. (1)查看磁盘名称命名 # su - grid$ sql ...
- ajax原生js封装
不带注释的 function ajax(json) { json.type = json.type ? json.type : 'get'; json.async = json.async == fa ...
- Split Screen
Split Screen 是一个用来分屏的 bookmarklet 程序. 它通过 javascript 通信协议实现[1]. 特点 使用 HTML5 <dialog> 元素实现 使用 G ...
- BUUCTF-Web Easy Calc
要素察觉 打开calc.php发现源码 过滤了很多字符.题目一开始提示了有waf,最后通过eval实现计算功能.考虑利用该函数读取flag文件,先尝试弹个phpinfo 被waf拦截,在num参数前面 ...
- date 常用格式化输出
date "+%Y-%m-%d" 2013-02-19 date "+%H:%M:%S" 13:13:59 date "+%Y-%m-%d %H:%M ...
- mysql字符集 utf8 和utf8mb4 的区别
一.导读我们新建mysql数据库的时候,需要指定数据库的字符集,一般我们都是选择utf8这个字符集,但是还会又一个utf8mb4这个字符集,好像和utf8有联系,今天就来解析一下这两者的区别. 二.起 ...