深入了解Kafka【二】工作流程及文件存储机制

1、Kafka工作流程
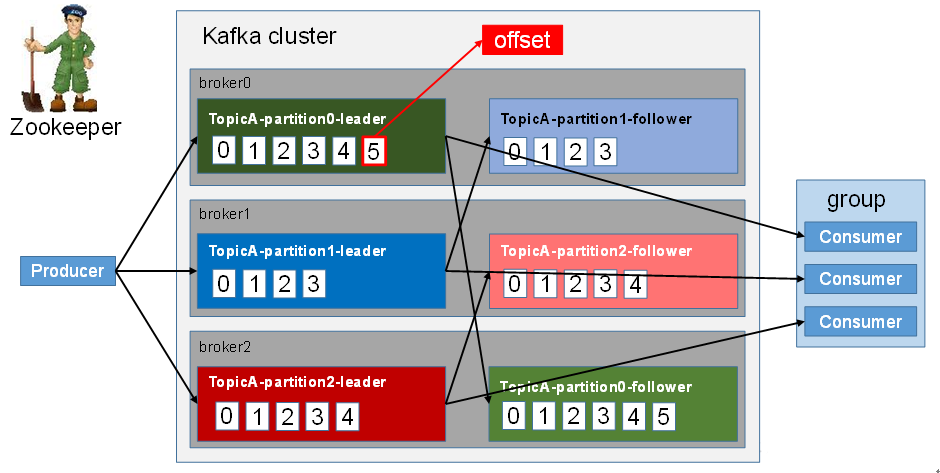
Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据。
Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个Segment,每个Segment对应两个文件,一个索引文件,一个日志文件。Producer生产的数据会被不断的追加到日志文件的末端,且每条数据都有自己的offset。消费组中的每个Consumer都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
2、文件存储机制
由于Producer产生的消息会不断的追加到日志文件的末尾,这样将对消息文件的维护以及以消费的消息的清理带来严重的影响,因此,Kafka引入的分片和索引的设计。每个Partition对应一个文件夹;“topic名称 分区序号”。每个Partition分为多个Segment,Segment分为两类文件:“.index”索引文件与“.log”数据文件,其中索引文件和数据文件都在Partition对应的文件夹中。
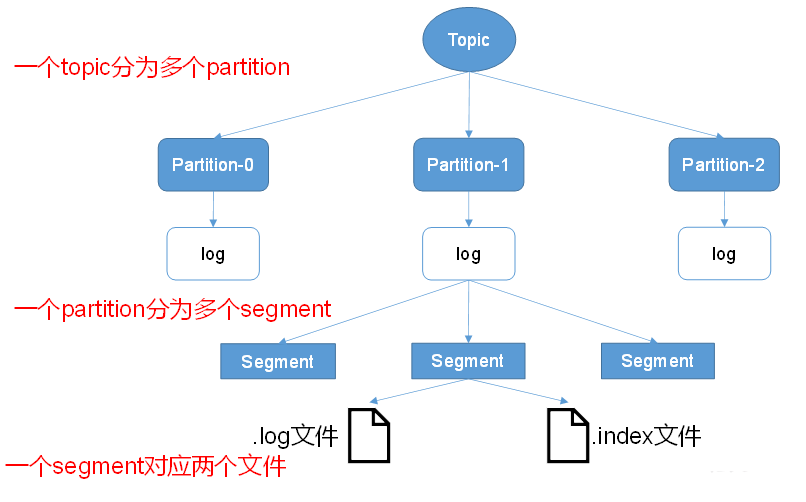
假设test-topic有3个分区,则对应的文件夹名称为:test-topic-0、test-topic-1、test-topic-2。
partition文件夹下文件形如:
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
可以看到有索引文件与数据文件,有3个Segment。
这两个文件的命令规则为:Partition全局的第一个Segment从0开始,后续每个Segment文件名为上一个Segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充。
以Segment文件的详细内容:
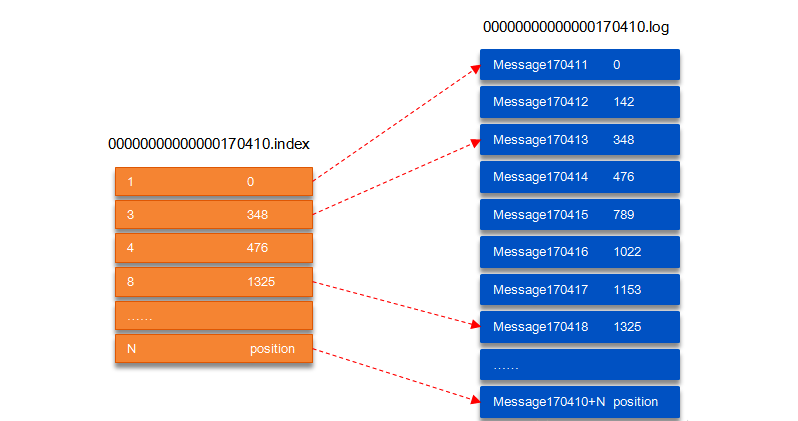
图中,索引文件存储的元数据指向数据文件中的message的物理偏移地址。
3、从partition中通过offset查找message
以上图为例,读取offset=170418的消息,首先查找segment文件,其中00000000000000000000.index 为最开始的文件,第二个文件为 00000000000000170410.index(起始偏移为 170410 1=170411),而第三个文件为 00000000000000239430.index(起始偏移为 239430 1=239431),所以这个 offset=170418 就落到了第二个文件之中。其它后续文件可以依次类推,以其偏移量命名并排列这些文件,然后根据二分查找法就可以快速定位到具体文件位置。其次根据 00000000000000170410.index 文件中的 [8,1325] 定位到 00000000000000170410.log 文件中的 1325 的位置进行读取。要是读取 offset=170418 的消息,从 00000000000000170410.log 文件中的 1325的位置进行读取,那么,如何确定何时读完本条消息呢?
这个问题由消息的物理结构解决,消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等字段,可以确定一条消息的大小,即读取到哪里截止。
参考
深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列

深入了解Kafka【二】工作流程及文件存储机制的更多相关文章
- Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程: 每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性. Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的 ...
- Kafka之工作流程分析
Kafka之工作流程分析 kafka核心组成 一.Kafka生产过程分析 1.1 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(pa ...
- Kafka与RocketMq文件存储机制对比
一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一. 开头问题 kafka文件结构和rocketMQ文件结构是什么样子?特点是什么? 一.目录结构 Kafk ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
随机推荐
- 灰帽黑客 基本的Linux漏洞攻击
有两个重要的寄存器负责处理堆栈:基址指针(EBP)和栈指针(ESP),EBP指向当前进程的当前栈帧的底部,ESP则总是指向栈顶 当调用函数的时候,会导致程序流跳转.在汇编代码调用函数时,将发生以下三件 ...
- python4.5实用内置模块
#引入urllib百度网页的数据爬取 from urllib import request url="http://www.baidu.com"data=request.urlop ...
- JS pc端网页特效
offset offset翻译就是偏移量,可以使用他相关的属性可以动态的得到该元素的位置.大小等等 获得元素距离带有定位父元素的位置 获得元素自己的大小(宽度高度) 注 ...
- 15、Facade 外观模式
什么是Facade模式 随着系统越来越复杂,我们需要把细节隐藏起来,给客户端提供一个统一的接口.在这种需求下facade模式诞生了.该模式比较简单,我们只需要在系统变得复杂把它运用上来,这样底层跟客户 ...
- 总结笔记 | 深度学习之Pytorch入门教程
笔记作者:王博Kings 目录 一.整体学习的建议 1.1 如何成为Pytorch大神? 1.2 如何读Github代码? 1.3 代码能力太弱怎么办? 二.Pytorch与TensorFlow概述 ...
- 你知道MySQL是如何处理千万级数据的吗?
mysql 分表思路 一张一亿的订单表,可以分成五张表,这样每张表就只有两千万数据,分担了原来一张表的压力,分表需要根据某个条件进行分,这里可以根据地区来分表,需要一个中间件来控制到底是去哪张表去找到 ...
- 利用Unity3D制作简易2D计算器
利用Unity3D制作简易2D计算器 标签(空格分隔): uiniy3D 1. 操作流程 在unity3DD中创建一个新项目 注意选择是2D的(因为默认3D) 在Assets框右键新建C#脚本 在新建 ...
- SpringBoot---SpringMVC关于拦截器的一些问题总结
SpringBoot---SpringMVC关于拦截器的一些问题总结 环境: IDEA :2020.1 Maven:3.5.6 SpringBoot: 2.3.2 1.直接在地址栏输入 http:// ...
- Python 常用的操作文件代码
1:统计list中相同的个数,并按大小排序. original_list = ['a', 'b', 'b', 'a', 'd', 'd', 'b', 'z', 'c', 'b', 'r', 's', ...
- Windows server 2008R2 中sql server的搭建
一.安装sql server Step1:下载sql server 2008 r2 standard,解压到Windows的C:\下. Step2:打开安装程序,进行sql server的安装 Ste ...