【高并发】面试官问我如何使用Nginx实现限流,我如此回答轻松拿到了Offer!
写在前面
最近,有不少读者说看了我的文章后,学到了很多知识,其实我本人听到后是非常开心的,自己写的东西能够为大家带来帮助,确实是一件值得高兴的事情。最近,也有不少小伙伴,看了我的文章后,顺利拿到了大厂Offer,也有不少小伙伴一直在刷我的文章,提升自己的内功,最终成为自己公司的核心业务开发人员。在此,冰河确实为你们高兴,希望小伙伴们能够一如既往的学习,保持一颗持续学习的心态,在技术的道路上越走越远。
今天写些什么呢?想来想去,写一篇关于高并发实战的文章吧,对,就写一下如何使用Nginx实现限流的文章吧。小伙伴们想看什么文章,可以在微信上给我留言,或者直接在公众号留言。
限流措施
如果看过我写的《【高并发】高并发秒杀系统架构解密,不是所有的秒杀都是秒杀!》一文的话,相信小伙伴们都会记得我说过的: 网上很多的文章和帖子中在介绍秒杀系统时,说是在下单时使用异步削峰来进行一些限流操作,那都是在扯淡!因为下单操作在整个秒杀系统的流程中属于比较靠后的操作了,限流操作一定要前置处理,在秒杀业务后面的流程中做限流操作是没啥卵用的。
Nginx作为一款高性能的Web代理和负载均衡服务器,往往会部署在一些互联网应用比较前置的位置。此时,我们就可以在Nginx上进行设置,对访问的IP地址和并发数进行相应的限制。
Nginx官方的限流模块
Nginx官方版本限制IP的连接和并发分别有两个模块:
- limit_req_zone 用来限制单位时间内的请求数,即速率限制,采用的漏桶算法 "leaky bucket"。
- limit_req_conn 用来限制同一时间连接数,即并发限制。
limit_req_zone 参数配置
limit_req_zone参数说明
Syntax: limit_req zone=name [burst=number] [nodelay];
Default: —
Context: http, server, location
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
- 第一个参数:$binary_remote_addr 表示通过remote_addr这个标识来做限制,“binary_”的目的是缩写内存占用量,是限制同一客户端ip地址。
- 第二个参数:zone=one:10m表示生成一个大小为10M,名字为one的内存区域,用来存储访问的频次信息。
- 第三个参数:rate=1r/s表示允许相同标识的客户端的访问频次,这里限制的是每秒1次,还可以有比如30r/m的。
limit_req zone=one burst=5 nodelay;
- 第一个参数:zone=one 设置使用哪个配置区域来做限制,与上面limit_req_zone 里的name对应。
- 第二个参数:burst=5,重点说明一下这个配置,burst爆发的意思,这个配置的意思是设置一个大小为5的缓冲区当有大量请求(爆发)过来时,超过了访问频次限制的请求可以先放到这个缓冲区内。
- 第三个参数:nodelay,如果设置,超过访问频次而且缓冲区也满了的时候就会直接返回503,如果没有设置,则所有请求会等待排队。
limit_req_zone示例
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /search/ {
limit_req zone=one burst=5 nodelay;
}
}
下面配置可以限制特定UA(比如搜索引擎)的访问:
limit_req_zone $anti_spider zone=one:10m rate=10r/s;
limit_req zone=one burst=100 nodelay;
if ($http_user_agent ~* "googlebot|bingbot|Feedfetcher-Google") {
set $anti_spider $http_user_agent;
}
其他参数
Syntax: limit_req_log_level info | notice | warn | error;
Default:
limit_req_log_level error;
Context: http, server, location
当服务器由于limit被限速或缓存时,配置写入日志。延迟的记录比拒绝的记录低一个级别。例子:limit_req_log_level notice延迟的的基本是info。
Syntax: limit_req_status code;
Default:
limit_req_status 503;
Context: http, server, location
设置拒绝请求的返回值。值只能设置 400 到 599 之间。
ngx_http_limit_conn_module 参数配置
ngx_http_limit_conn_module 参数说明
这个模块用来限制单个IP的请求数。并非所有的连接都被计数。只有在服务器处理了请求并且已经读取了整个请求头时,连接才被计数。
Syntax: limit_conn zone number;
Default: —
Context: http, server, location
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location /download/ {
limit_conn addr 1;
}
一次只允许每个IP地址一个连接。
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
...
limit_conn perip 10;
limit_conn perserver 100;
}
可以配置多个limit_conn指令。例如,以上配置将限制每个客户端IP连接到服务器的数量,同时限制连接到虚拟服务器的总数。
Syntax: limit_conn_zone key zone=name:size;
Default: —
Context: http
limit_conn_zone $binary_remote_addr zone=addr:10m;
在这里,客户端IP地址作为关键。请注意,不是$ remote_addr,而是使用$ binary_remote_addr变量。 $ remote_addr变量的大小可以从7到15个字节不等。存储的状态在32位平台上占用32或64字节的内存,在64位平台上总是占用64字节。对于IPv4地址,$ binary_remote_addr变量的大小始终为4个字节,对于IPv6地址则为16个字节。存储状态在32位平台上始终占用32或64个字节,在64位平台上占用64个字节。一个兆字节的区域可以保持大约32000个32字节的状态或大约16000个64字节的状态。如果区域存储耗尽,服务器会将错误返回给所有其他请求。
Syntax: limit_conn_log_level info | notice | warn | error;
Default:
limit_conn_log_level error;
Context: http, server, location
当服务器限制连接数时,设置所需的日志记录级别。
Syntax: limit_conn_status code;
Default:
limit_conn_status 503;
Context: http, server, location
设置拒绝请求的返回值。
Nginx限流实战
限制访问速率
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit;
}
}
上述规则限制了每个IP访问的速度为2r/s,并将该规则作用于根目录。如果单个IP在非常短的时间内并发发送多个请求,结果会怎样呢?

我们使用单个IP在10ms内发并发送了6个请求,只有1个成功,剩下的5个都被拒绝。我们设置的速度是2r/s,为什么只有1个成功呢,是不是Nginx限制错了?当然不是,是因为Nginx的限流统计是基于毫秒的,我们设置的速度是2r/s,转换一下就是500ms内单个IP只允许通过1个请求,从501ms开始才允许通过第二个请求。
burst缓存处理
我们看到,我们短时间内发送了大量请求,Nginx按照毫秒级精度统计,超出限制的请求直接拒绝。这在实际场景中未免过于苛刻,真实网络环境中请求到来不是匀速的,很可能有请求“突发”的情况,也就是“一股子一股子”的。Nginx考虑到了这种情况,可以通过burst关键字开启对突发请求的缓存处理,而不是直接拒绝。
来看我们的配置:
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit burst=4;
}
}
我们加入了burst=4,意思是每个key(此处是每个IP)最多允许4个突发请求的到来。如果单个IP在10ms内发送6个请求,结果会怎样呢?

相比实例一成功数增加了4个,这个我们设置的burst数目是一致的。具体处理流程是:1个请求被立即处理,4个请求被放到burst队列里,另外一个请求被拒绝。通过burst参数,我们使得Nginx限流具备了缓存处理突发流量的能力。
但是请注意:burst的作用是让多余的请求可以先放到队列里,慢慢处理。如果不加nodelay参数,队列里的请求不会立即处理,而是按照rate设置的速度,以毫秒级精确的速度慢慢处理。
nodelay降低排队时间
在使用burst缓存处理中,我们看到,通过设置burst参数,我们可以允许Nginx缓存处理一定程度的突发,多余的请求可以先放到队列里,慢慢处理,这起到了平滑流量的作用。但是如果队列设置的比较大,请求排队的时间就会比较长,用户角度看来就是RT变长了,这对用户很不友好。有什么解决办法呢?nodelay参数允许请求在排队的时候就立即被处理,也就是说只要请求能够进入burst队列,就会立即被后台worker处理,请注意,这意味着burst设置了nodelay时,系统瞬间的QPS可能会超过rate设置的阈值。nodelay参数要跟burst一起使用才有作用。
延续burst缓存处理的配置,我们加入nodelay选项:
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit burst=4 nodelay;
}
}
单个IP 10ms内并发发送6个请求,结果如下:
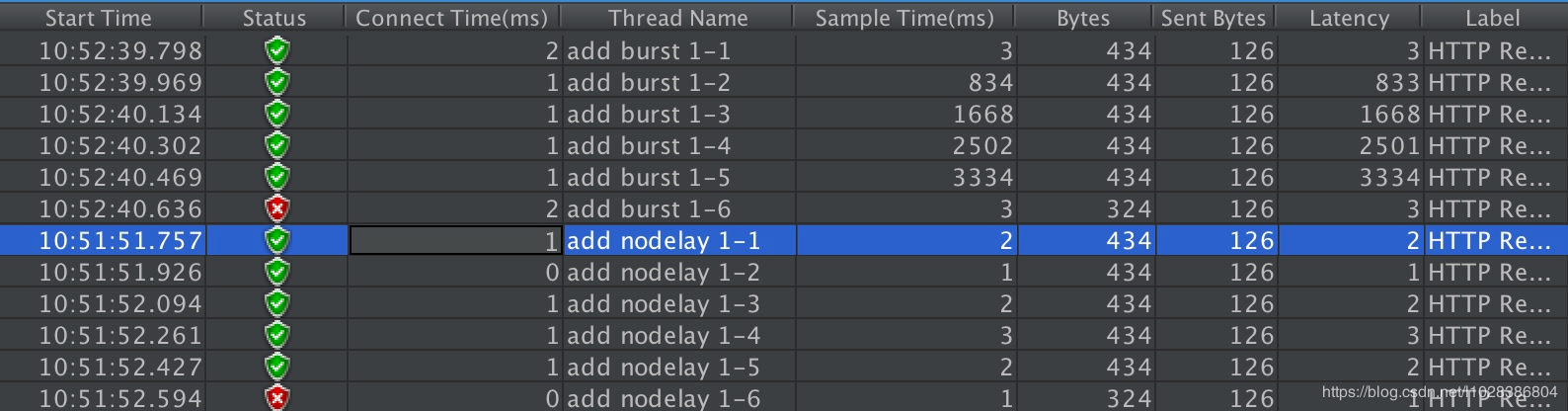
跟burst缓存处理相比,请求成功率没变化,但是总体耗时变短了。这怎么解释呢?在burst缓存处理中,有4个请求被放到burst队列当中,工作进程每隔500ms(rate=2r/s)取一个请求进行处理,最后一个请求要排队2s才会被处理;这里,请求放入队列跟burst缓存处理是一样的,但不同的是,队列中的请求同时具有了被处理的资格,所以这里的5个请求可以说是同时开始被处理的,花费时间自然变短了。
但是请注意,虽然设置burst和nodelay能够降低突发请求的处理时间,但是长期来看并不会提高吞吐量的上限,长期吞吐量的上限是由rate决定的,因为nodelay只能保证burst的请求被立即处理,但Nginx会限制队列元素释放的速度,就像是限制了令牌桶中令牌产生的速度。
看到这里你可能会问,加入了nodelay参数之后的限速算法,到底算是哪一个“桶”,是漏桶算法还是令牌桶算法?当然还算是漏桶算法。考虑一种情况,令牌桶算法的token为耗尽时会怎么做呢?由于它有一个请求队列,所以会把接下来的请求缓存下来,缓存多少受限于队列大小。但此时缓存这些请求还有意义吗?如果server已经过载,缓存队列越来越长,RT越来越高,即使过了很久请求被处理了,对用户来说也没什么价值了。所以当token不够用时,最明智的做法就是直接拒绝用户的请求,这就成了漏桶算法。
自定义返回值
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit burst=4 nodelay;
limit_req_status 598;
}
}
默认情况下 没有配置 status 返回值的状态:


好了,咱们今天就聊到这儿吧!别忘了给个在看和转发,让更多的人看到,一起学习一起进步!!
写在最后
如果你觉得冰河写的还不错,请微信搜索并关注「 冰河技术 」微信公众号,跟冰河学习高并发、分布式、微服务、大数据、互联网和云原生技术,「 冰河技术 」微信公众号更新了大量技术专题,每一篇技术文章干货满满!不少读者已经通过阅读「 冰河技术 」微信公众号文章,吊打面试官,成功跳槽到大厂;也有不少读者实现了技术上的飞跃,成为公司的技术骨干!如果你也想像他们一样提升自己的能力,实现技术能力的飞跃,进大厂,升职加薪,那就关注「 冰河技术 」微信公众号吧,每天更新超硬核技术干货,让你对如何提升技术能力不再迷茫!

【高并发】面试官问我如何使用Nginx实现限流,我如此回答轻松拿到了Offer!的更多相关文章
- 【Java8新特性】面试官问我:Java8中创建Stream流有哪几种方式?
写在前面 先说点题外话:不少读者工作几年后,仍然在使用Java7之前版本的方法,对于Java8版本的新特性,甚至是Java7的新特性几乎没有接触过.真心想对这些读者说:你真的需要了解下Java8甚至以 ...
- 当面试官问你GET和POST区别的时候,请这么回答.......
文章内容转载于微信公众号WebTechGarden 一.GET和POST的'普通'区别 GET和POST是HTTP请求的两种基本方法,要说它们的区别,接触过WEB开发的人都能说出一二. 最直观的区别就 ...
- 面试官:RabbitMQ怎么实现消费端限流
哈喽!大家好,我是小奇,一位不靠谱的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新 一.前言 RabbitMQ有很多高级特性, ...
- 高并发面试必问:分布式消息系统Kafka简介
转载:https://blog.csdn.net/caisini_vc/article/details/48007297 Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成 ...
- 面试官问我:谈谈对Java GC的了解?回答完让我回家等消息....
JVM的运行数据区 首先我简单来画一张 JVM的结构原理图,如下. 我们重点关注 JVM在运行时的数据区,你可以看到在程序运行时,大致有5个部分. 1.方法区 不止是存“方法”,而是存储整个 clas ...
- 面试官问:HashMap在并发情况下为什么造成死循环?一脸懵
这个问题是在面试时常问的几个问题,一般在问这个问题之前会问Hashmap和HashTable的区别?面试者一般会回答:hashtable是线程安全的,hashmap是线程不安全的. 那么面试官就会紧接 ...
- 面试官问我,Redis分布式锁如何续期?懵了。
前言 上一篇[面试官问我,使用Dubbo有没有遇到一些坑?我笑了.]之后,又有一位粉丝和我说在面试过程中被虐了.鉴于这位粉丝是之前肥朝的粉丝,而且周一又要开启新一轮的面试,为了回馈他长期以来的支持,所 ...
- 面试官问线程安全的List,看完再也不怕了!
最近在Java技术栈知识星球里面有球友问到了线程安全的 List: 扫码查看答案或加入知识星球 栈长在之前的文章<出场率比较高的一道多线程安全面试题>里面讲过 ArrayList 的不安全 ...
- 【MySQL】面试官问我:MySQL如何实现无数据插入,有数据更新?我是这样回答的!
写在前面 马上就是金九银十的跳槽黄金期了,很多读者都开始出去面试了.这不,又一名读者出去面试被面试官问了一个MySQL的问题:向MySQL中插入数据,如何实现MySQL中没有当前id标识的数据时插入数 ...
随机推荐
- springMVC 异常
springMVC 异常 0.依赖(不只是本次案例所需) <?xml version="1.0" encoding="UTF-8"?> <p ...
- LeetCode 76,一题教会你面试算法时的思考套路
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题的第45篇文章,我们一起来看看LeetCode的76题,最小窗口子串Minimum Window Substrin ...
- 跨域问题 - Nginx反向代理
Nginx反向代理的思路,就是通过Nginx解析URL地址的时候进行判断,将请求转发的具体的服务器上. 解决思路 跨域问题,是由于JavaScript出于安全方面的考虑,不允许跨域调用其他页面的对象. ...
- 附020.Nginx-ingress部署及使用
一 手动部署-官网版 1.1 获取资源 [root@master01 ~]# mkdir ingress [root@master01 ~]# cd ingress/ [root@master01 i ...
- @loj - 3157@「NOI2019」机器人
目录 @description@ @solution@ @accepted code@ @details@ @description@ 小 R 喜欢研究机器人. 最近,小 R 新研制出了两种机器人,分 ...
- Ubuntu:E: Sub-process /usr/bin/dpkg returned an error code (1)
Ubuntu系统安装软件时报以下错误: E: Sub-process /usr/bin/dpkg returned an error code (1) 解决: mv /var/lib/dpkg/inf ...
- (八)利用 Profile 构建不同环境的部署包
接上回继续,项目开发好以后,通常要在多个环境部署,象我们公司多达5种环境:本机环境(local).(开发小组内自测的)开发环境(dev).(提供给测试团队的)测试环境(test).预发布环境(pre) ...
- The following packages will be SUPERCEDED by a higher-priority channel是什么意思?
参考资料: https://stackoverflow.com/questions/42015732/the-following-packages-will-be-superceded-by-a-hi ...
- android 6.0 权限设置详解
从Android 6.0版本开始,在安装应用时,该应用无法取得任何权限. 相反,在使用应用的过程中,若某个功能需要获取某个权限,系统会弹出一个对话框,显式地由用户决定是否将该权限赋予应用. 只有得到了 ...
- Struts2 执行流程 以及 Action与Servlet比较 (个人理解)
上图提供了struts2的执行流程.如下: 1:从客户端发出请求(HTTPServletRequest). 2:请求经过各种过滤器(filter),注:一般情况下,如SiteMesh等其他过滤器要放在 ...