redis zset底层实现原理
一.Zset编码的选择
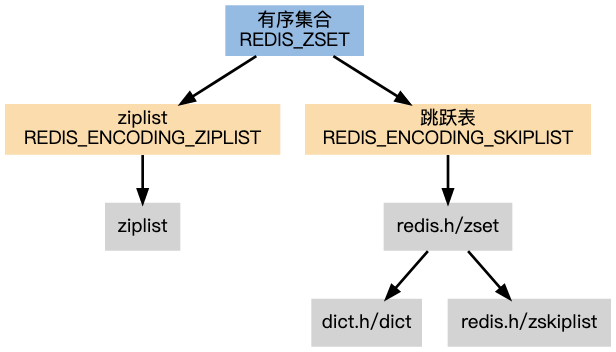
1.有序集合对象的编码可以是ziplist或者skiplist。同时满足以下条件时使用ziplist编码:
- 元素数量小于128个
- 所有member的长度都小于64字节
- 其他:
- 不能满足上面两个条件的使用 skiplist 编码。以上两个条件也可以通过Redis配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改
- 对于一个
REDIS_ENCODING_ZIPLIST编码的 Zset, 只要满足以上任一条件, 则会被转换为REDIS_ENCODING_SKIPLIST编码
2.zset操作命令
zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
zrem(key, member) :删除名称为key的zset中的元素member
zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素 zcard(key):返回名称为key的zset的基数
zscore(key, element):返回名称为key的zset中元素element的score zremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
二.ziplist
1. 介绍
ziplist 编码的 Zset 使用紧挨在一起的压缩列表节点来保存,第一个节点保存 member,第二个保存 score。ziplist 内的集合元素按 score 从小到大排序,其实质是一个双向链表。虽然元素是按 score 有序排序的, 但对 ziplist 的节点指针只能线性地移动,所以在 REDIS_ENCODING_ZIPLIST 编码的 Zset 中, 查找某个给定元素的复杂度为 O(N)O(N)。
2.
//操作
ZADD price 8.5 apple 5.0 banana 6.0 cherry //存储顺序

3. 从以上的布局中,我们可以看到ziplist内存数据结构,由如下5部分构成:
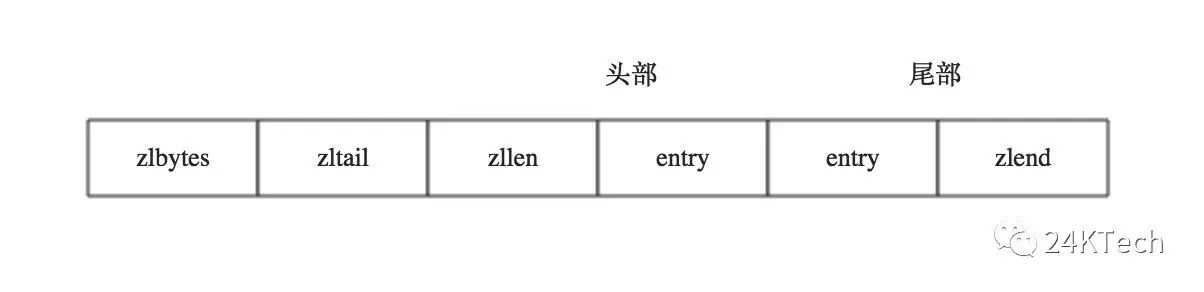
各个部分在内存上是前后相邻的并连续的,每一部分作用如下:
zlbytes: 存储一个无符号整数,固定四个字节长度(32bit),用于存储压缩列表所占用的字节(也包括<zlbytes>本身占用的4个字节),当重新分配内存的时候使用,不需要遍历整个列表来计算内存大小。
zltail: 存储一个无符号整数,固定四个字节长度(32bit),表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
zllen: 压缩列表包含的节点个数,固定两个字节长度(16bit), 表示ziplist中数据项(entry)的个数。由于zllen字段只有16bit,所以可以表达的最大值为2^16-1。
注意点:如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以表示。ziplist是如何做到的?
如果<zllen>小于等于2^16-2(也就是不等于2^16-1),那么<zllen>就表示ziplist中数据项的个数;否则,也就是<zllen>等于16bit全为1的情况,那么<zllen>就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。
entry,表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构。
zlend, ziplist最后1个字节,值固定等于255,其是一个结束标记。
三.skiplist
1.介绍
skiplist 编码的 Zset 底层为一个被称为 zset 的结构体,这个结构体中包含一个字典和一个跳跃表。跳跃表按 score 从小到大保存所有集合元素,查找时间复杂度为平均
O(logN)O(logN),最坏 O(N
O(N) 。字典则保存着从 member 到 score 的映射,这样就可以用 O(1)O(1) 的复杂度来查找 member 对应的 score 值。虽然同时使用两种结构,但它们会通过指针来共享相同元素的 member 和 score,因此不会浪费额外的内存。
2.详解
跳表(skip List)是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。简单说来跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(logN)的时间复杂度。
先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

- 23首先和7比较,再和19比较,比它们都大,继续向后比较。
- 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
- 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个skiplist的过程:
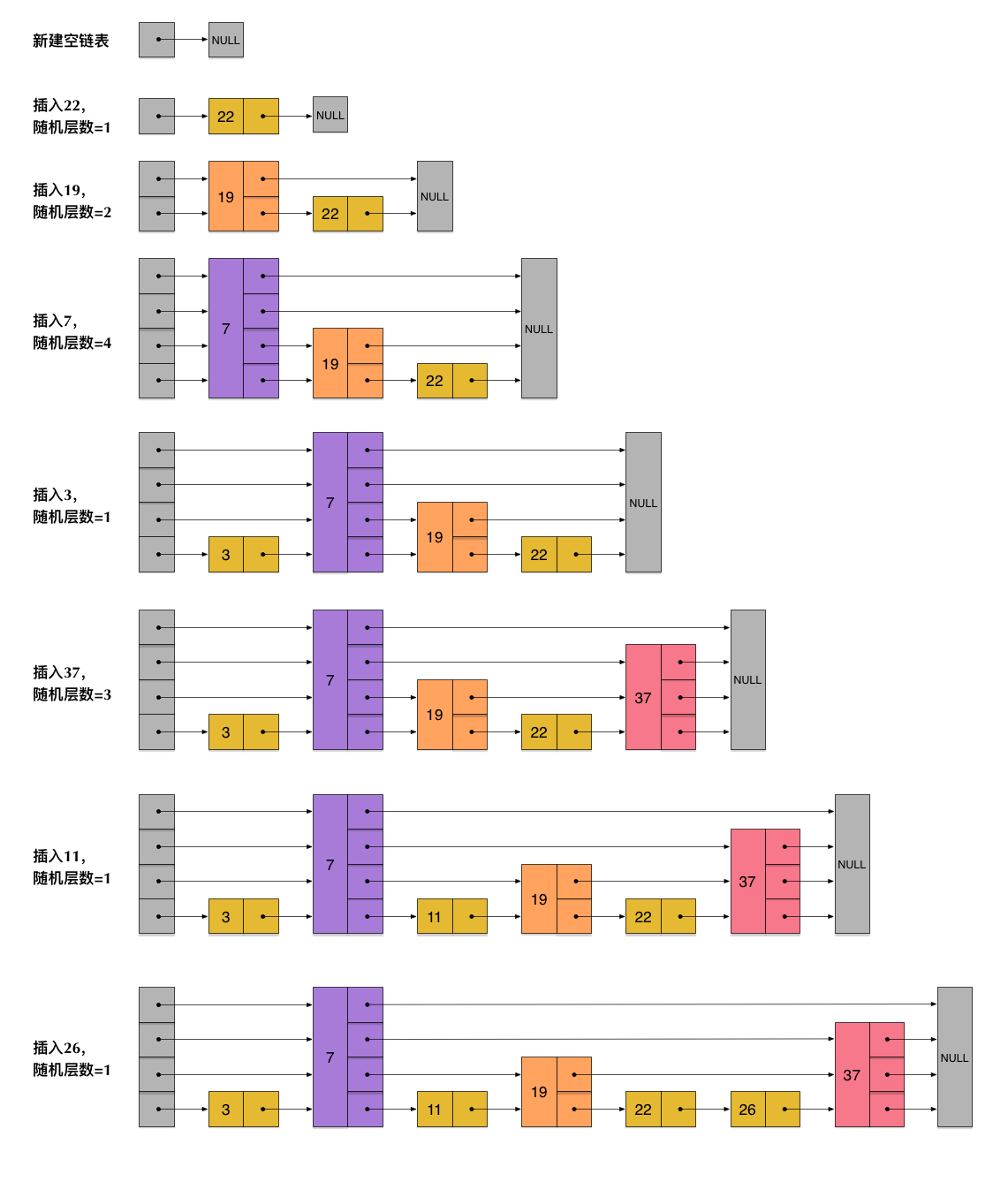
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
skiplist,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
刚刚创建的这个skiplist总共包含4层链表,现在假设我们在它里面依然查找23,下图给出了查找路径:
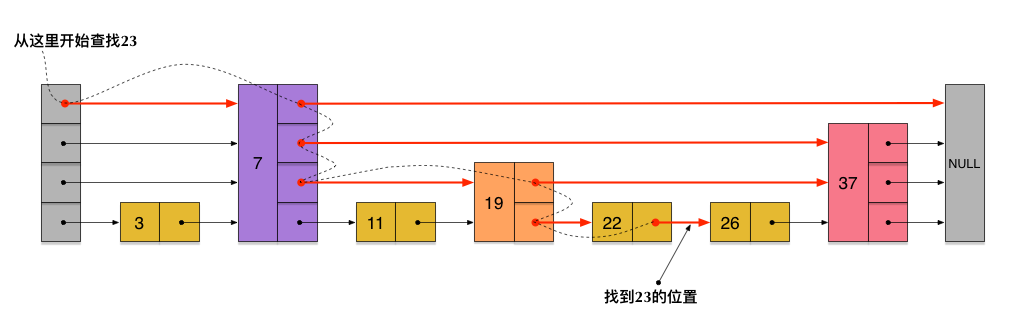
需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
实际应用中的skiplist每个节点应该包含key和value两部分。前面的描述中我们没有具体区分key和value,但实际上列表中是按照key(score)进行排序的,查找过程也是根据key在比较。
执行插入操作时计算随机数的过程,是一个很关键的过程,它对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
- 首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。
- 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。
- 节点最大的层数不允许超过一个最大值,记为MaxLevel。
这个计算随机层数的伪码如下所示:
|
1
2
3
4
5
6
|
randomLevel()
level := 1
// random()返回一个[0...1)的随机数
while random() < p and level < MaxLevel do
level := level + 1
return level
|
randomLevel()的伪码中包含两个参数,一个是p,一个是MaxLevel。在Redis的skiplist实现中,这两个参数的取值为:
|
1
2
|
p = 1/4
MaxLevel = 32
|
四.skiplist与平衡树、哈希表的比较
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
- 在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
- 查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。
五.Redis中的skiplist实现
skiplist的数据结构定义:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
|
简单分析一下几个查询命令:
- zrevrank由数据查询它对应的排名,这在前面介绍的skiplist中并不支持。
- zscore由数据查询它对应的分数,这也不是skiplist所支持的。
- zrevrange根据一个排名范围,查询排名在这个范围内的数据。这在前面介绍的skiplist中也不支持。
- zrevrangebyscore根据分数区间查询数据集合,是一个skiplist所支持的典型的范围查找(score相当于key,数据相当于value)。
实际上,Redis中sorted set的实现是这样的:
- 当数据较少时,sorted set是由一个ziplist来实现的。
- 当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
看一下sorted set与skiplist的关系,:
- zscore的查询,不是由skiplist来提供的,而是由那个dict来提供的。
- 为了支持排名(rank),Redis里对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据之后,也同时很容易获得排名。而且,根据排名的查找,时间复杂度也为O(log n)。
- zrevrange的查询,是根据排名查数据,由扩展后的skiplist来提供。
- zrevrank是先在dict中由数据查到分数,再拿分数到skiplist中去查找,查到后也同时获得了排名。
总结起来,Redis中的skiplist跟前面介绍的经典的skiplist相比,有如下不同:
- 分数(score)允许重复,即skiplist的key允许重复。这在最开始介绍的经典skiplist中是不允许的。
- 在比较时,不仅比较分数(相当于skiplist的key),还比较数据本身。在Redis的skiplist实现中,数据本身的内容唯一标识这份数据,而不是由key来唯一标识。另外,当多个元素分数相同的时候,还需要根据数据内容来进字典排序。
- 第1层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
- 在skiplist中可以很方便地计算出每个元素的排名(rank)。
六.Redis为什么用skiplist而不用平衡树?
这里从内存占用、对范围查找的支持和实现难易程度这三方面总结的原因。
There are a few reasons:
1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
1) 也不是非常耗费内存,实际上取决于生成层数函数里的概率 p,取决得当的话其实和平衡树差不多。
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
2) 因为有序集合经常会进行 ZRANGE 或 ZREVRANGE 这样的范围查找操作,跳表里面的双向链表可以十分方便地进行这类操作。
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
3) 实现简单,ZRANK 操作还能达到 o(logn)的时间复杂度O
参考:https://zsr.github.io/2017/07/03/redis-zset%E5%86%85%E9%83%A8%E5%AE%9E%E7%8E%B0/
redis zset底层实现原理的更多相关文章
- zset底层数据结构
redis zset底层数据结构 https://www.jianshu.com/p/fb7547369655 跳跃列表(Skip List)与其在Redis中的实现详解 https://www.ji ...
- 【redis】redis底层数据结构原理--简单动态字符串 链表 字典 跳跃表 整数集合 压缩列表等
redis有五种数据类型string.list.hash.set.zset(字符串.哈希.列表.集合.有序集合)并且自实现了简单动态字符串.双端链表.字典.压缩列表.整数集合.跳跃表等数据结构.red ...
- Redis有序集内部实现原理分析(二)
Redis技术交流群481804090 Redis:https://github.com/zwjlpeng/Redis_Deep_Read 本篇博文紧随上篇Redis有序集内部实现原理分析,在这篇博文 ...
- Redis深度历险——核心原理与应用实践
高可用架构」的各位老铁们,你们好!你是否还记得上个月发布的文章中,有两篇深入讲解Redis的文章,分别是和,广大粉丝读者们对这两篇文章整体评价颇高.而我就是这两篇文章的原创作者「老钱」(钱文品),我是 ...
- Redis专题(2):Redis数据结构底层探秘
前言 上篇文章Redis闲谈(1):构建知识图谱介绍了redis的基本概念.优缺点以及它的内存淘汰机制,相信大家对redis有了初步的认识.互联网的很多应用场景都有着Redis的身影,它能做的事情远远 ...
- 面试官:你了解过Redis对象底层实现吗
上一章我们讲了Redis的底层数据结构,不了解的人可能会有疑问:这个和平时用的五大对象有啥关系呢?这一章我们就主要解释他们所建立的联系. 看这个文件之前,如果对ziplist.skiplist.int ...
- Redis(二)--- Redis的底层数据结构
1.Redis的数据结构 Redis 的底层数据结构包含简单的动态字符串(SDS).链表.字典.压缩列表.整数集合等等:五大数据类型(数据对象)都是由一种或几种数结构构成. 在命令行中可以使用 OBJ ...
- 以 DEBUG 方式深入理解线程的底层运行原理
说到线程的底层运行原理,想必各位也应该知道我们今天不可避免的要讲到 JVM 了.其实大家明白了 Java 的运行时数据区域,也就明白了线程的底层原理,不过把这些东西明明白白写在纸面上的,网络上的文章并 ...
- 延时任务-基于redis zset的完整实现
所谓的延时任务给大家举个例子:你买了一张火车票,必须在30分钟之内付款,否则该订单被自动取消.订单30分钟不付款自动取消,这个任务就是一个延时任务. 我之前已经写过2篇关于延时任务的文章: <完 ...
随机推荐
- OAuth + Security - 5 - Token存储升级(数据库、Redis)
PS:此文章为系列文章,建议从第一篇开始阅读. 在我们之前的文章中,我们当时获取到Token令牌时,此时的令牌时存储在内存中的,这样显然不利于我们程序的扩展,所以为了解决这个问题,官方给我们还提供了其 ...
- 曹工说JDK源码(4)--抄了一小段ConcurrentHashMap的代码,我解决了部分场景下的Redis缓存雪崩问题
曹工说JDK源码(1)--ConcurrentHashMap,扩容前大家同在一个哈希桶,为啥扩容后,你去新数组的高位,我只能去低位? 曹工说JDK源码(2)--ConcurrentHashMap的多线 ...
- DES/3DES/AES 三种对称加密算法实现
1. 简单介绍 3DES(或称为Triple DES)是三重数据加密算法(TDEA,Triple Data Encryption Algorithm)块密码的通称.它相当于是对每个数据块应用三次DES ...
- JSP和Servlet的相同点和不同点、有何联系。
JSP 和 Servlet 有哪些相同点和不同点,他们之间的联系是什么? 联系: JSP 是 Servlet 技术的扩展,本质上是 Servlet 的简易方式,更强调应用的外表表达. JSP编译后是& ...
- JAVA 代码查错
1.abstract class Name { private String name; public abstract boolean isStupidName(String name){}} 大侠 ...
- 入门springMVC
前言 开始学习springMVC整理的笔记,今天这一篇是回顾第一个springMVC程序. 环境 大致文件结构 先是要创建好一个普通maven工程,加入一些servlet包以及mvc支持的jar包,如 ...
- 2019-02-08 Python学习之Scrapy的简单了解
今天遇到的问题和昨天差不多,一个Scrapy装了好久,anaconda卸了又装,pycharm卸了又装,环境变量配置一堆,依赖包下载一堆.查了一堆资料总算是搞好了. Scripy: 先放个框架结构图( ...
- C++值元编程
--永远不要在OJ上使用值元编程,过于简单的没有优势,能有优势的编译错误. 背景 2019年10月,我在学习算法.有一道作业题,输入规模很小,可以用打表法解决.具体方案有以下三种: 运行时预处理,生成 ...
- maven项目快速搭建SSM框架(一)创建maven项目,SSM框架整合,Spring+Springmvc+Mybatis
首先了解服务器开发的三层架构,分配相应的任务,这样就能明确目标,根据相应的需求去编写相应的操作. 服务器开发,大致分为三层,分别是: 表现层 业务层 持久层 我们用到的框架分别是Spring+Spri ...
- 错误 C2679二进制“没有找到接受“std::string”类型的右操作数的运算符(或没有可接受的转换
错误 C2679二进制“没有找到接受“std::string”类型的右操作数的运算符(或没有可接受的转换 严重性 代码 说明 项目 文件 行 禁止显示状态错误 C2679 二进制“<<”: ...