数据可视化实例(六): 带线性回归最佳拟合线的散点图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter3/chapter3
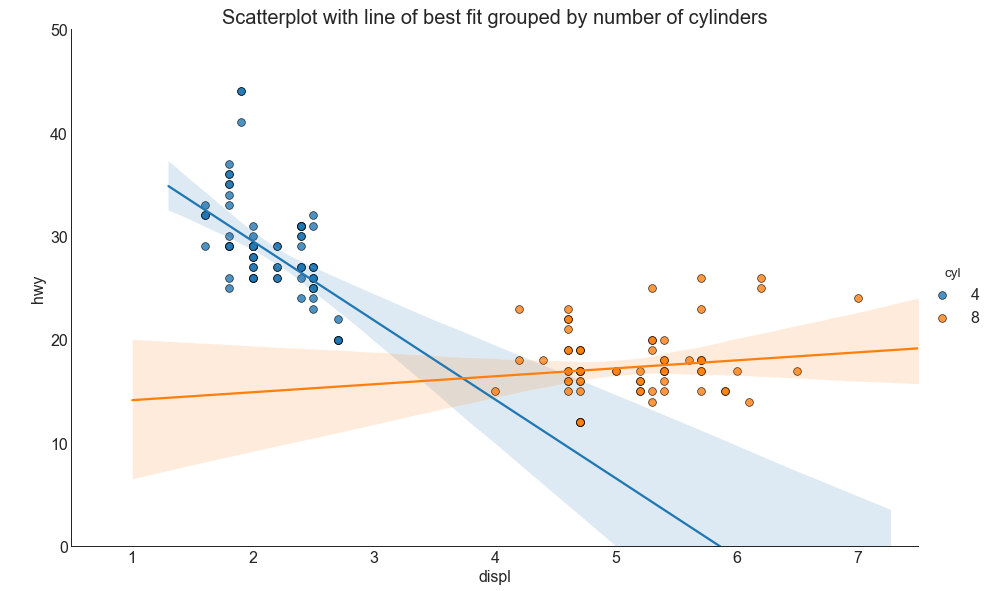
如果你想了解两个变量如何相互改变,那么最佳拟合线就是常用的方法。 下图显示了数据中各组之间最佳拟合线的差异。 要禁用分组并仅为整个数据集绘制一条最佳拟合线,请从下面的 sns.lmplot()调用中删除 hue ='cyl'参数。
导入所需要的库
# 导入numpy库
import numpy as np
# 导入pandas库
import pandas as pd
# 导入matplotlib库
import matplotlib as mpl
import matplotlib.pyplot as plt
# 导入seaborn库
import seaborn as sns
# 在jupyter notebook显示图像
%matplotlib inline
设定图像各种属性
large = 22; med = 16; small = 12
# 设置子图上的标题字体
params = {'axes.titlesize': large,
# 设置图例的字体
'legend.fontsize': med,
# 设置图像的画布
'figure.figsize': (16, 10),
# 设置标签的字体
'axes.labelsize': med,
# 设置x轴上的标尺的字体
'xtick.labelsize': med,
# 设置整个画布的标题字体
'ytick.labelsize': med,
'figure.titlesize': large}
# 更新默认属性
plt.rcParams.update(params)
# 设定整体风格
plt.style.use('seaborn-whitegrid')
# 设定整体背景风格
sns.set_style("white")
程序代码
# step1:导入数据
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# 选择cyl为4,8的数据集
df_select = df.loc[df.cyl.isin([4, 8]), :]
# step2:绘图
# 设立风格
sns.set_style('white') gridobj = sns.lmplot(x = 'displ', # 横坐标
y = 'hwy', # 纵坐标
hue = 'cyl', # 定义被绘制数据的子集
data = df_select, # 绘图所需要的数据集
height = 7, # 每个子图的高度
aspect = 1.6, # 每个子图的宽高比
robust = True, # 抗噪声鲁棒性
palette = 'tab10', # 调色板(不同层次的“色调”变量)
# 设置其它参数
scatter_kws = dict(s = 60, linewidths = .7, edgecolors = 'black'))
# step3:装饰
# 横纵坐标范围
gridobj.set(xlim = (0.5, 7.5), ylim = (0, 50))
# 设置标题
plt.title("Scatterplot with line of best fit grouped by number of cylinders", fontsize=20)
# 显示图像
plt.show()
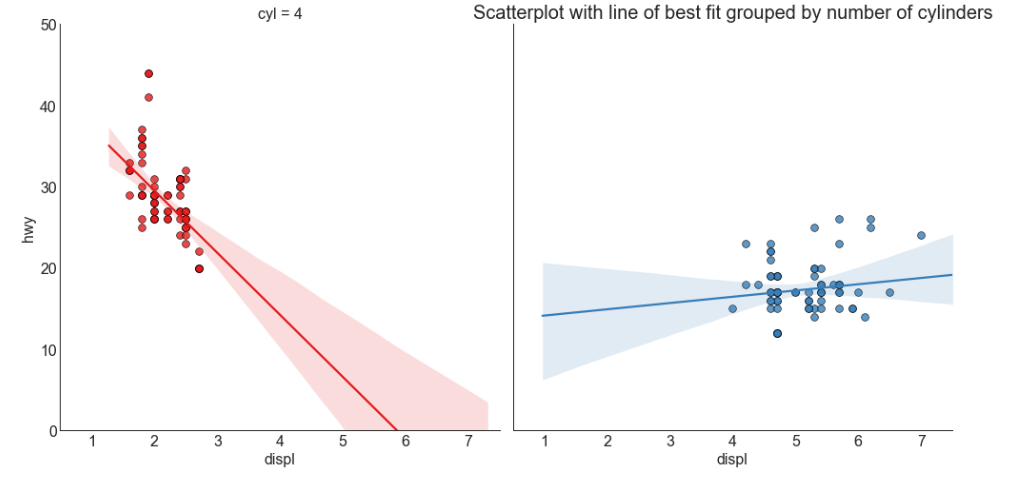
# step1:导入数据
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# 选择cyl为4,8的数据集
df_select = df.loc[df.cyl.isin([4, 8]), :]
# step2:绘图
# 设立风格
sns.set_style('white') gridobj = sns.lmplot(x = 'displ', # 横坐标
y = 'hwy', # 纵坐标
hue = 'cyl', # 定义绘制数据的子集
data = df_select, # 绘图所需要的数据集
height = 7, # 每个子图的高度
robust = True, # 抗噪声鲁棒性
palette = 'Set1', # 调色板(不同层次的“色调”变量)
col = 'cyl', # 按照类别绘制图像,一个类别一张图像
# 设置其它参数
scatter_kws = dict(s = 60, linewidths = .7, edgecolors = 'black'))
# step3:装饰
# 横纵坐标范围
gridobj.set(xlim = (0.5, 7.5), ylim = (0, 50))
# 设置标题
plt.title("Scatterplot with line of best fit grouped by number of cylinders", fontsize=20)
# 显示图像
plt.show()
博文总结
索引
- .loc[ ]__标签索引
- .iloc[ ]__位置索引
sns.lmplot
- 回归模型绘制
- 参数
- x__横坐标标称
- y__纵坐标标称
- hue__定义被绘制数据的子集
- data__绘图所需要的数据集
- height__每个子图的高度
- aspect__每个子图的宽高比
- palette__调色板
数据可视化实例(六): 带线性回归最佳拟合线的散点图(matplotlib,pandas)的更多相关文章
- 数据可视化实例(十一): 矩阵图(matplotlib,pandas)
矩阵图 https://datawhalechina.github.io/pms50/#/chapter9/chapter9 导入所需要的库 import numpy as np # 导入numpy库 ...
- 数据可视化实例(八): 边缘直方图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter6/chapter6 边缘直方图 (Marginal Histogram) 边缘直方图具有沿 X 和 Y ...
- 数据可视化实例(十七):包点图 (matplotlib,pandas)
排序 (Ranking) 包点图 (Dot Plot) 包点图表传达了项目的排名顺序,并且由于它沿水平轴对齐,因此您可以更容易地看到点彼此之间的距离. https://datawhalechina.g ...
- 数据可视化实例(七): 计数图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter5/chapter5 计数图 (Counts Plot) 避免点重叠问题的另一个选择是增加点的大小,这取 ...
- 【Matplotlib】数据可视化实例分析
数据可视化实例分析 作者:白宁超 2017年7月19日09:09:07 摘要:数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息.但是,这并不就意味着数据可视化就一定因为要实现其功能用途而令 ...
- 数据可视化实例(十六):有序条形图(matplotlib,pandas)
排序 (Ranking) 棒棒糖图 (Lollipop Chart) 棒棒糖图表以一种视觉上令人愉悦的方式提供与有序条形图类似的目的. https://datawhalechina.github.io ...
- [译]学习IPython进行交互式计算和数据可视化(六)
第五章:高性能并行计算 一个反复被提及的反对使用Python进行高性能数值计算的言论是这种语言是动态解释型的,速度太慢.一种编译型低级语言,如C,能提供比它快几个数量级的运算速度.我们在第三章--使用 ...
- 数据可视化实例(五): 气泡图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter2/chapter2 关联 (Correlation) 关联图表用于可视化2个或更多变量之间的关系. 也 ...
- 数据可视化实例(三): 散点图(pandas,matplotlib,numpy)
关联 (Correlation) 关联图表用于可视化2个或更多变量之间的关系. 也就是说,一个变量如何相对于另一个变化. 散点图(Scatter plot) 散点图是用于研究两个变量之间关系的经典的和 ...
随机推荐
- Spring源码系列(一)--详解介绍bean组件
简介 spring-bean 组件是 IoC 的核心,我们可以通过BeanFactory来获取所需的对象,对象的实例化.属性装配和初始化都可以交给 spring 来管理. 针对 spring-bean ...
- Docker数据管理与挂载管理
介绍如何在 Docker 内部以及容器之间管理数据:在容器中管理数据主要有两种方式:数据卷(Volumes).挂载主机目录 (Bind mounts) 镜像来源 [root@docker01 ~]# ...
- 3、尚硅谷_SSM高级整合_使用ajax操作实现增加员工的功能
20.尚硅谷_SSM高级整合_新增_创建员工新增的模态框.avi 1.接下来当我们点击增加按钮的时候会弹出一个员工信息的对话框 知识点1:当点击新增的时候会弹出一个bootstrap的一个模态对话框 ...
- Python初识类与对象
Python初识类与对象 类与对象 世界观角度分析类与对象 类是一个抽象的概念,而对象是一个实体的存在,对象由类创造而出,每个对象之间互相独立互不影响,一个对象可以同时拥有多个类的方法,实例化就是通过 ...
- vue全家桶(2.4)
3.6.重定向和别名 3.6.1.重定向 路由重定向通俗的说就是从一个路由重新定位跳转到另一个路由,例如:访问的 "/a" 重定向到"/b" 重定向也是通过配置 ...
- jmeter跨线程组获取cookie或jmeter线程组共享cookie-笔者亲测
一.Jmeter版本 此次示例采用的是apache-jmeter-5.2.1版本 二.设置配置文件使Cookie管理器保存cookie信息. 修改apache-jmeter-5.2.1/bin/jme ...
- max depth exceeded when dereferencing c0-param0的问题
在做项目的时候,用到了dwr,有一次居然报错,错误是max depth exceeded when dereferencing c0-param0 上网查了一下,我居然传参数的时候传的是object类 ...
- 字符串String和list集合判空验证
1`字符串判断处理: 结论: 当if判断条件为两个,并且它们两个为或的关系,如果第一个条件为false,则继续第二个条件的判断:如果第一个条件为true,该例子不足以说明是否判断第二个条件, 最终可以 ...
- LeetCode65. 有效数字
这题完美的诠释了什么叫"面向测试用例编程".由于要考虑的情况很多,所以基本的思路是先根据给出的测试用例写出规则判断无效的情况,然后再根据提交的错误对剩下的情况进行特判,如果不满足所 ...
- 【Oracle】rman中SBT_TYPE类型的备份如何删除
技阳的rman数据库出现删除rman备份失败,原因是出现SBT_TYPE的磁带备份. [BEGIN] 2018/8/13 13:48:42 RMAN> list backup; List of ...