十八般武艺玩转GaussDB(DWS)性能调优(三):好味道表定义
摘要:表结构设计是数据库建模的一个关键环节,表定义好坏直接决定了集群的有效容量以及业务查询性能,本文从产品架构、功能实现以及业务特征的角度阐述在GaussDB(DWS)的中表定义时需要关注的一些关键因素。
前言
GaussDB(DWS)是企业级的大规模并行处理关系型数据库,采用Shared-nothing架构的MPP(Massive Parallel Processing)系统,支持PB级别数据量的处理,适用于详单查询、数据仓库、混合负载和大数据分析等场景。Shared-nothing架构天然支持数据打散分布到各个数据节点(DataNode)以及多节点协同计算机制,同时这种机制对表定义涉及提出了更高的诉求,表定义会直接影响集群的有效容量以及业务查询性能。本文从产品架构、功能实现以及业务特征的角度阐述GaussDB(DWS)的中表定义需要关注的一些关键因素。
1 存储方式设计
GaussDB(DWS)支持行存储(row-based storage)和列存储(column-based storage)两种存储方式,这两种存储格式分别适用不同的业务场景。通常来讲典型的点查询为主的场景推荐使用行存储,典型的统计分析型业务推荐使用列存储。
1.1 行存储
行存储模式下,一条数据的所有列组合在一起称之为一个tuple多个tuple组成一个page,所有的page构成表的数据文件。pages是行存数据存取的最小单元,一个page默认8KB。page的基本结构如下
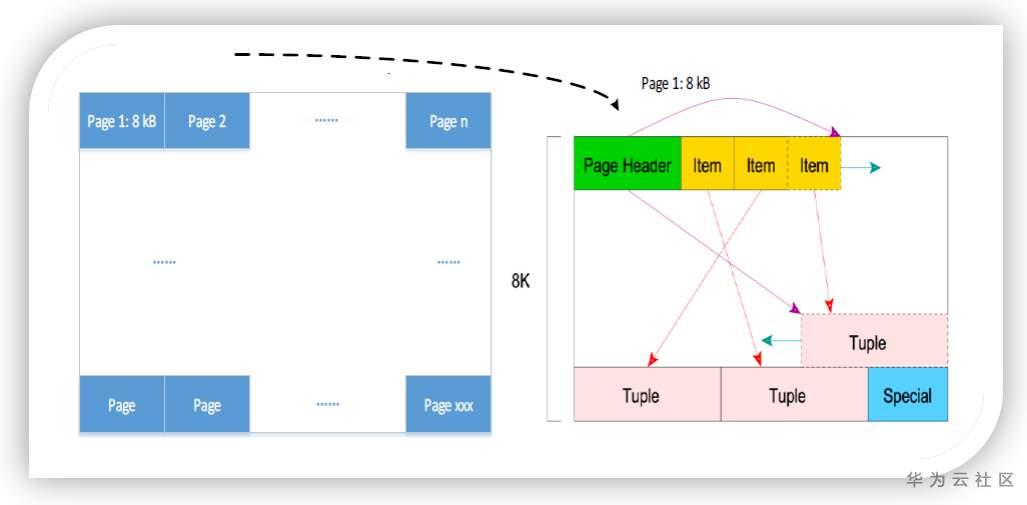
行存储模式下,所有数据列集中存储在一个tuple中,所以行存储的更新(UPDATE)、删除(DELETE)、索引点查性能较好,但是当查询列只涉及所有列的很少一部分的时候,所有列的数据也都会被读取,导致大量的无效IO,因此推荐比较简单点查场景或者存在频繁的数据更新的业务采用行存储。
1.2 列存储
列存储下把数据表中的每一列单独存储,每个列的 6w条数据组成一个CU,每个列的所有的CU构成一个列的数据文件,每个列都会有单独的数据文件。CU的基本结构如下
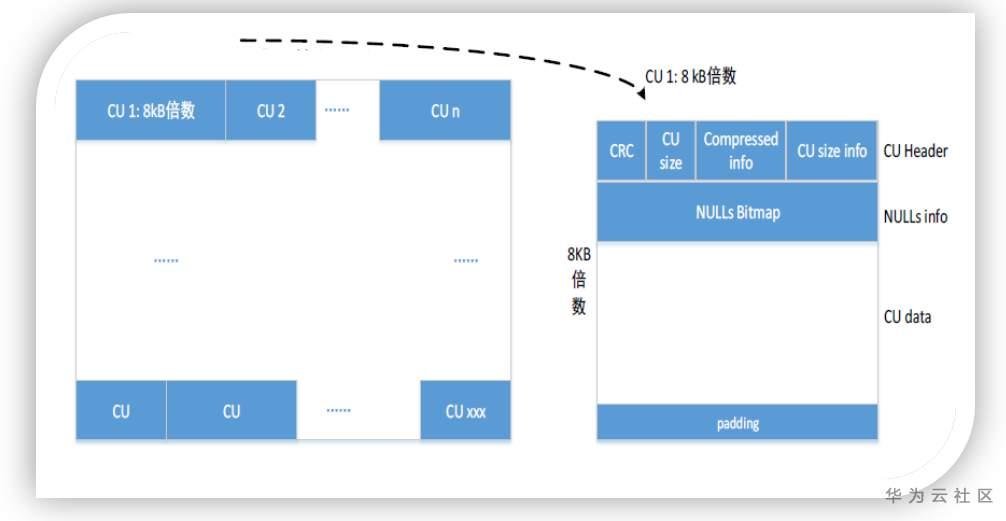
列数据之间具有更高的相似度,所以列存储的压缩性能更好。当只查询少量列且查询数据量较大时,列存储的IO性能收益很明显。因为数据分列存储,导致更新(UPDATE)、删除(DELETE)、索引点查性的时候需要访问或者刷新更多的文件,导致大量的随机IO;因此相比行存储,列存储的更新、删除、索引点查询的性能较差。同时列存储天然的可以跟向量化执行引擎对接,在表关联、汇聚等重计算场景下可以使用向量化执行引擎提升计算性能,因此统计分析等重IO和重计算型业务推荐使用列存储。
1.3 表存储方式选择
表的存储类型是表定义设计的第一步,客户业务属性是表的存储类型的决定性因素。根据以上我们对行存储和列存储原理的介绍,重查询分析(大量的多表关联、group by操作)场景推荐使用使用列存表,典型的有数仓场景;以点查询为主的场景推荐使用行存表,典型的有详单查询场景。

GaussDB(DWS)支持单个database中同时存储行存储和列存储类型的表,以更好的支持混合负载场景
1.4 表存储方式定义
表的行/列存储通过表定义的orientation属性定义。当指定orientation属性为row时,表为行存储;当指定orientation属性为column时,表为列存储;如果不指定,默认为行存储。
行存储表定义方式如下:
CREATE TABLE storage
(
c_id int,
c_d_id int NOT NULL,
c_w_id int NOT NULL,
c_first varchar(16) NOT NULL
)WITH(orientation=row)
DISTRIBUTE BY HASH(c_d_id);
列存储表定义方式如下: CREATE TABLE storage
(
c_id int,
c_d_id int NOT NULL,
c_w_id int NOT NULL,
c_first varchar(16) NOT NULL
)WITH(orientation=column)
DISTRIBUTE BY HASH(c_d_id);
2 数据分布方式设计
GaussDB(DWS)的MPP架构,天然支持通过散列的方式进行水平分表,将业务数据表的元组打散存储到各个数据节点(DataNode)上,通过并行利用各个数据节点的IO能力提升数据扫描的效率。为了优化高频关联小表的查询性能,GuassDB(DWS)支持复制的数据分布方式。表的分布方式取决于表的业务属性,事实表一般数据量较大,且数据增加或者变化很频繁,建议使用散列分布;维度表数据量较小,且数据一般不会变化,只有定期更新操作,建议使用复制分布。
2.1 散列分布
散列分布是按照某种散列规则,把表数据map到指定的数据节点(DataNode)上进行存储的方式。散列分布可以利用各个节点的IO资源,提升各个数据节点的IO能力。GaussDB(DWS)中采用hash的散列策略,按照表定义时指定的分布列组合,对一条记录的某一个或几个字段进行hash运算后,生成对应的hash值,然后根据DN实例与哈希值的映射关系获得该元组的目标存储位置。
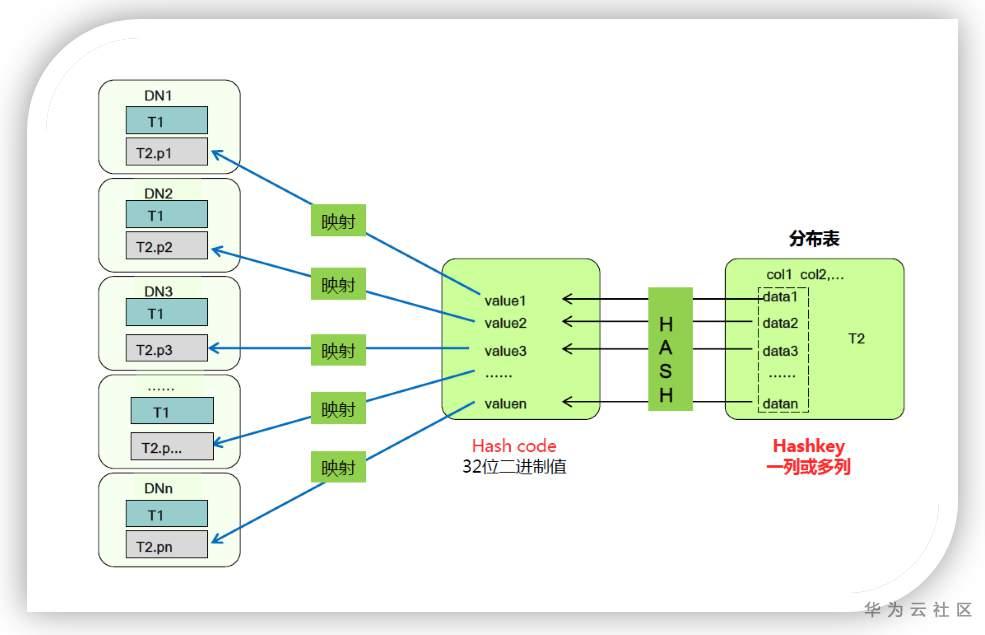
对于散列分布的表,分布列的选择非常重要。当分布列选择合理时,Hash散列策略可以大大减小计算节点之间的数据交互,大幅提升查询性能;但是当hash分布列选择不合理时,会导致数据倾斜(某个或者某些DataNode的数据量严重超过其它DataNode的数据量),因为短板效应导致集群的有效容量下降。
散列主要使用于客户业务表,这些表有数据量大、数据量逐渐增加的特征,适用散列分布可以有效的提升表查询性能。
2.2 复制分布
复制分布(replication)策略将表中的全量数据在集群的每一个DN实例上保留一份。在关联操作中复制表可以避免数据重分布操作,减小网络开销,同时减少了plan segment(每个plan segment都会起对应的线程)的个数;但是复制分布策略会导致比较严重的数据冗余,因此只有小表才适合复制分布策略。
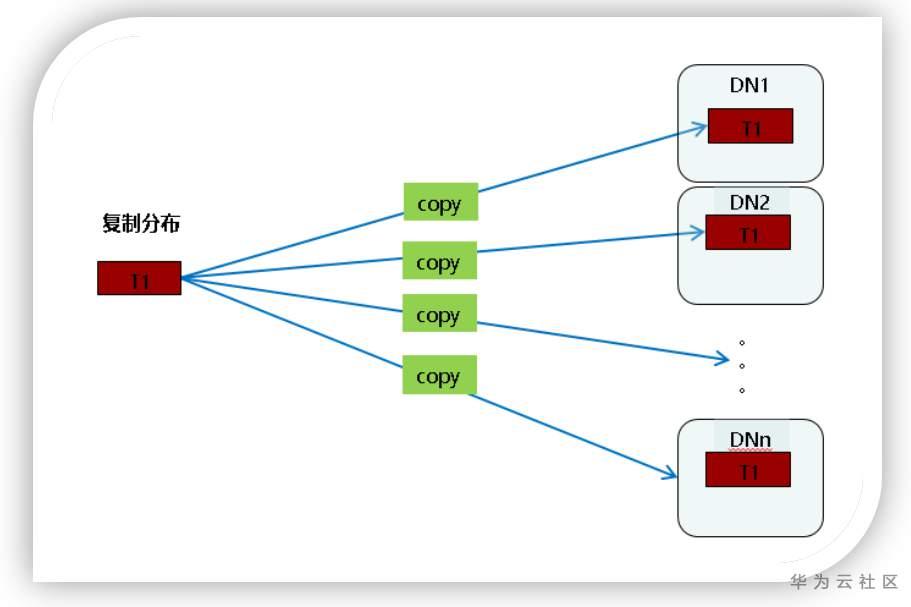
实际生产上只有小数据量、查询频繁、更新(DELETE/INSERT/UFPATE)很少的表(基本都是维度表)才会定义replication分布策略
2.3 分布方式选择
表数据分布方式主要依据表的业务属性和数据属性决定,简单总结如下

2.4 分布列定义
表的复制分布属性可以通过表定义指定:
CREATE TABLE storage
(
c_id int,
c_d_id int NOT NULL,
c_w_id int NOT NULL,
c_first varchar(16) NOT NULL
)WITH(orientation=row)
DISTRIBUTE BY REPLICATRRION;
表的散列分分布属性可以通过表定义:
CREATE TABLE storage
(
c_id int,
c_d_id int NOT NULL,
c_w_id int NOT NULL,
c_first varchar(16) NOT NULL
)WITH(orientation=row)
DISTRIBUTE BY HASH(c_d_id);
3 分布列设计
对于采取散列分布策略的表,分布列的选择取决于表数据的特征以及表相关的业务查询特征,推荐使用经常做关联查询的列、且数据分布均匀的列作为分布列。好的分布列可以通过减少跨节点的数据计划节省网络资源开销,优化查询性能。
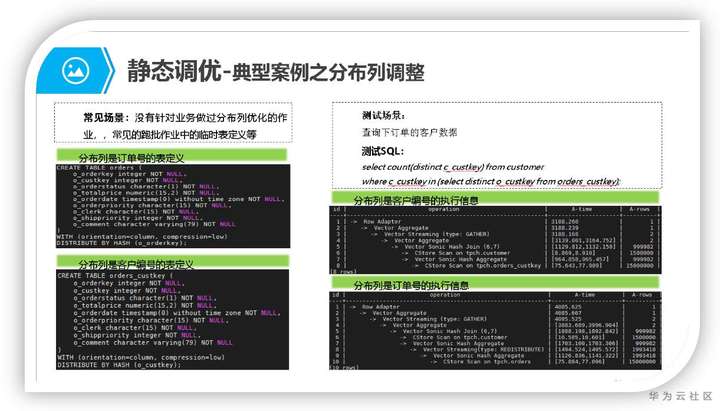
3.1 分布列选择策略
Hash分布表的分布列选取至关重要,需要满足以下原则:
a) 列值应比较离散,以便数据能够均匀分布到各个DN
分布列值分布不均匀会导致数据在数据节点分布不均匀(某些DataNode上数据量大,某些DataNode上数据量小),这会导致不同DataNode上数据扫面的计算量不均衡,从而拖慢整个表扫描的性能;同时会因为部分DataNode的磁盘容量提前爆满,集群只读,导致集群有效容量下降。通常情况下使用表的主键列或者唯一索引列作为表的分布列是一个不错的选择
b) 考虑选择查询中的连接条件为分布列
GaussDB(DWS)的散列策略是hash,根据GaussDB(DWS)的分布式查询框架,当两表等值关联(join)列刚好是表的分布列时(如果分布列是多列,那么要求所有列都存在等值关联条件),join任务可以不再数据重分布的情况下直接Join,这样可以省去数据重分布的时间开销和网络资源开销,从而提升查询计算性能。
c) 在满足前面两条原则的情况下尽量不要选取存在常量等值filter的列
GaussDB(DWS)会协调节点(Coordinator)上进行任务规划,此时会根据表的过滤条件(Filter)进行扫面操作剪枝优化,以较小IO资源开销。如果表dwcjk的分布列是zqdh,且表dwcjk扫描时存在Filter条件zqdh=’000001’,而根据散列策略zqdh=’000001’的值都分布在数据节点DN1上,那么协调节点(Coordinator)上进行任务规划时会对dwcjk表的扫描操作进行剪枝(指定只有在数据节点DN1对表dwcjk进行数据扫描操作)。这样对于表扫描的实际压力会值落在节点DN1,导致不同数据节点的IO压力不均衡。
注意此策略主要适用于统计分析类的重查询场景,对于详单查询等以点查为主要场景的查询类业务,在满足前两个约束的前提下,可以优选存在常量等值Filter约束列作为分布列。因为这种场景在数据节点上使用索引加速查询,查询耗时往往以ms或者几十ms计,通过剪枝把查询任务map到具体的某个数据节点上执行,节省无效操作(不用连接到所有的数据节点上操作),同时也会大大的提高并发能力
3.2 分布列选择的限制
GaussDB(DWS)的列存储格式的表不支持主键和唯一约束,行存储格式表支持主键和唯一约束。但是存储格式表的主键和唯一约束的创建存在严格约束:分布列的集合是主键列或者索引列的子集。
多个列作为分布列时,分布列的顺序会影响数据分布,即同一条记录在distribute by hash(col1, col2)方式下,跟在distribute by hash(col2, col1)分布方式下可能会map到不同的DataNode上进行存储。
GaussDB(DWS)对分布列的个数没有限制,但是建议分布列的个数尽量少,一方面可以减小数据map到不同DN的计算开销,同时也可以更好的全匹配join条件,提升查询性能。
3.3 分布列离散性校验
对于当前已创建并且导入数据的表,可以使用如下SQL检验表数据分布的离散型
-- 'public'是表的schema名称,'storage'是表名
SELECT * FROM table_distribution('public.storage') ORDER BY dnsize;

对于已经创建并且导入数据的表,如果我们认为当前的分布列不够离散,在修改为其它列之前,可尝试使用如下SQL判断目标分布列的离散性
-- 'public'是表的schema名称,'storage'是表名,c_id是要检测的列名
SELECT * FROM table_skewness('public.storage', 'c_id') ORDER BY seqnum;

当确定目标分布列之后,可以使用如下SQL实现分布列的修改
-- 'public'是表的schema名称,'storage'是表名,c_id是修改后的目标分布列
ALTER TABLE public.storage DISTRIBUTE BY HASH(c_id);
4 表分区设计
通俗的讲表,分区就是把一个大表按照条件分割为若干个小表,这种分割体现在数据库内部的数据管理上,对表数据的常规操作(UPDATE/DELETE/INSERT/SELECT)是透明的。一般对数据和查询都有明显区间段特征的表使用分区策略,可通过减少不必要的数据扫描提升查询性能。如下case中,使用分区表可以减少60%的数据扫描量,SQL查询整体性能提升46左右。
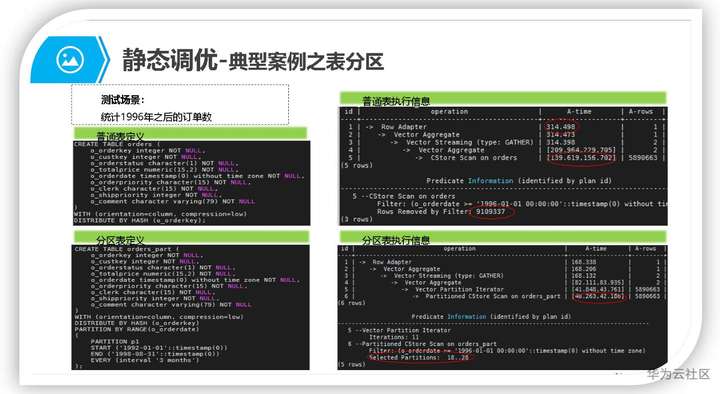
4.1 分区表的优势
分区表把逻辑上的一张表根据范围分区策略分成几张物理块库进行存储,这张逻辑上的表称之为分区表,物理块称之为分区。分区表是一张逻辑表,不存储数据,数据实际是存储在分区上的。分区表和普通表相比具有以下优点:
a) 改善查询性能
对分区对象的查询可以仅搜索自己关心的分区,提高检索效率
b) 增强可用性
如果分区表的某个分区出现故障,表在其他分区的数据仍然可用
c) 提升可维护性
对于需要周期性删除的过期历史数据,可以通过drop/truncate分区的方式快速高效处理
4.2 分区策略选择
当表有以下特征时,可以考虑使用表分区策略
a) 数据具有明显区间性的字段
分区表需要根据有明显区间性字段进行表分区。通常我们比如日期、区域、数值等字段进行分区,时间字段是最常见的分区字段。
b) 业务查询有明显的区间范围特征
查询数据可落到区间范围指定的分区内,这样才能通过分区剪枝,只扫描查询需要的分区,从而提升数据扫描效率,降低数据扫描的IO开销。
c) 表数据量比较大
小表扫描本身耗时不大,分区表的性能收益不明显,因此只建议对大表采取分区策略。列存储模式下因为每个列是单独的文件出处,且最小的存储单元CU可存储6w行数据,因此对于列存分区表,建议每个分区的数据不小于DN个数*6w
4.3 分区表定义
分区表策略定义分为两种方式
a) 简单区间切割
这种是最常见的通用的分区定义策略,适合所有的分区定义场景。
CREATE TABLE web_returns_p1
(
wr_returned_date_sk integer,
wr_returned_time_sk integer,
wr_item_sk integer NOT NULL,
wr_refunded_customer_sk integer
)
WITH (orientation = column)
DISTRIBUTE BY HASH (wr_item_sk)
PARTITION BY RANGE(wr_returned_date_sk)
(
PARTITION p2016 VALUES LESS THAN(20161231),
PARTITION p2017 VALUES LESS THAN(20171231),
PARTITION p2018 VALUES LESS THAN(20181231),
PARTITION p2019 VALUES LESS THAN(20191231),
PARTITION pxxxx VALUES LESS THAN(maxvalue)
);
b) 指定策略切割
此方式适用于分区间隔固定、批量创建分区的场景。当分区个数很多时,此方式可大大节省创建分区的工作量
CREATE TABLE web_returns_p1
(
wr_returned_date_sk integer,
wr_returned_time_sk integer,
wr_item_sk integer NOT NULL,
wr_refunded_customer_sk integer
)
WITH (orientation = column)
DISTRIBUTE BY HASH (wr_item_sk)
PARTITION BY RANGE(wr_returned_date_sk)
(
PARTITION p2016 START(20161231) END(20191231) EVERY(10000),
PARTITION p0 END(maxvalue)
);
4.4 分区键选择限制
类似表分布列的选择,对于行存储格式的表,如果表存在主键或者唯一约束,分区键应当是是主键列或者唯一约束的索引列的子集。
4.5 分区表查询
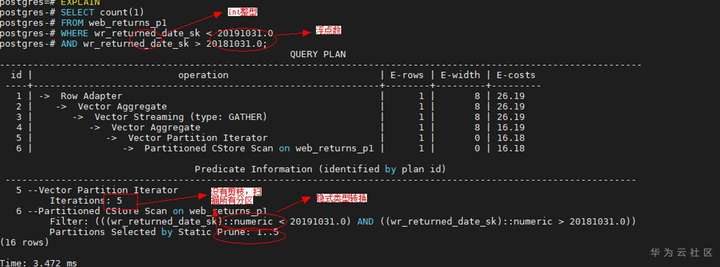
只有查询语句可以进行分区剪枝的时候,分区表查询才会产生数据扫描上的性能收益。一般只有当分区键跟常量值存在直接的比较(>、<、=、<=、>=)操作时,分区表才可以正常剪枝。我们可以通过对查询语句执行explain命令查看分区剪枝的效果
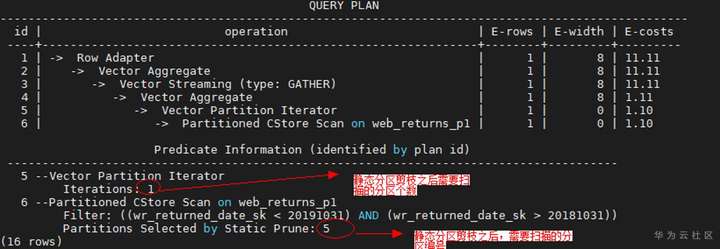
有时我们期望编写的SQL语句可以进行分区剪枝,但是实际上并没有走到分区剪枝,这种预期外的行为往往是因为以下因素导致
a) 分区键上有函数
当分区键上存在函数调用时,分区表无法剪枝
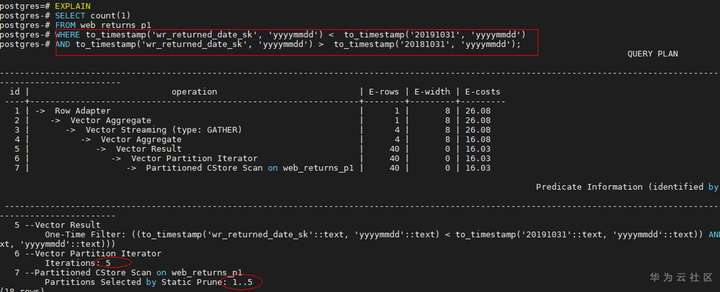
b) 分区键字段的存在隐式类型转换
这种场景往往是因为分区键跟常量值的数据类型不一致,导致计划规划时分区键的数据类型发生隐式类型转换,导致分区无法剪枝
5 字段设计
表字段设计时需要注意以下内容
a) 使用执行效率比较高的数据类型
一般来说整型数据的运算(包括=、>、<、≧、≦、≠等常规的比较运算,以及group by等运算)效率比字符串、浮点数要高。能使用整型的场景尽量使用整型。
b) 使用短字段的数据类型
长度较短的数据类型不仅可以减小数据文件的大小,提升IO性能;同时也可以减小计算相关计算时的内存消耗,提升计算性能。比如我们需要一个整型数据,如果可以用smallint就尽量不用int,如果可以用int就尽量不用bigint。
c) 关联列使用一致的数据类型
表关联列尽量使用相同的数据类型。如果表关联列数据类型不同,在执行时数据库会动态地转化为相同的数据类型进行比较,这种转换会带来一定的性能开销,同时可能会因为类型转换导致表关联操作时发生数据重分布,导致额外的性能和资源开销。
6 约束设计
1) 非空(not null)约束
明确不存在null值的字段加上not null约束。在特定场景下,优化器会对包含not null的查询语句进行自动优化,提升查询效率。
2) 主键/唯一约束
行存储表支持唯一/主键约束,如果表是散列分布,那么约束列必须包含所有的分布列;如果表做了分区,那么约束列也必须包含所有的分区列。
3) 局部聚簇约束
局部聚簇(partial cluster key,简称PCK)是列存储表一种局部聚簇技术,这种技术可以让表数据在批量入库的时,先对表进行局部排序,然后再写盘。这样可以让相同/相似的数据连续存储,提高数据的压缩比;同时在查询时也可以依赖列存储表的min/max稀疏索引实现表的CU过滤,从实现高效的数据过滤效果(参见《GaussDB(DWS)性能调优:列存表scan性能优化》)。一张表上只能建立一个PCK,一个PCK可以包含多列,但是一般不建议超过2列。通常我们使用经常出现的、过滤效果比较好的简单表达式中的列作为PCK列,局部聚簇约束的定义方式跟主键约束的定义方式类似
CREATE TABLE web_returns_p1
(
wr_returned_date_sk integer,
wr_returned_time_sk integer,
wr_item_sk integer NOT NULL,
wr_refunded_customer_sk integer,
PARTIAL CLUSTER KEY(wr_returned_date_sk)
)
WITH (orientation = column)
DISTRIBUTE BY HASH (wr_item_sk);

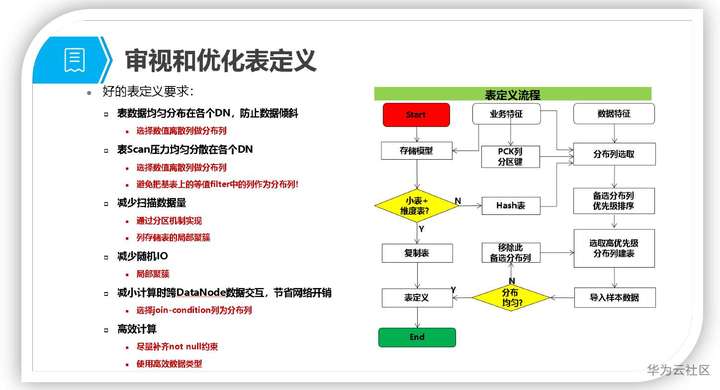
7 表定义总结
最后简单总结下表定义流程
十八般武艺玩转GaussDB(DWS)性能调优(三):好味道表定义的更多相关文章
- 十八般武艺玩转GaussDB(DWS)性能调优:SQL改写
摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改. 数据库的应用中,充斥着坏味 ...
- 十八般武艺玩转GaussDB(DWS)性能调优:路径干预
摘要:路径生成是表关联方式确定的主要阶段,本文介绍了几个影响路径生成的要素:cost_param, scan方式,join方式,stream方式,并从原理上分析如何干预路径的生成. 一.cost模型选 ...
- 性能调优7:多表连接 - join
在产品环境中,往往存在着大量的表连接情景,不管是inner join.outer join.cross join和full join(逻辑连接符号),在内部都会转化为物理连接(Physical Joi ...
- Java 代码性能调优“三十六”策
代码优化,一个很重要的课题.可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗?没用,但是, ...
- 数据库性能调优之始: analyze统计信息
摘要:本文简单介绍一下什么是统计信息.统计信息记录了什么.为什么要收集统计信息.怎么收集统计信息以及什么时候收集统计信息. 1 WHY:为什么需要统计信息 1.1 query执行流程 下图描述了Gau ...
- Spark常规性能调优
1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行 ...
- MySQL管理之道,性能调优,高可用与监控(第二版)pdf下载
MySQL管理之道,性能调优,高可用与监控(第二版) 书中内容以实战为导向,所有内容均来自于笔者多年实践经验的总结和新知识的拓展,同时也针对运维人员.DBA等相关工作者会遇到的有代表性的疑难问题给出了 ...
- JVM 性能调优实战之:一次系统性能瓶颈的寻找过程
玩过性能优化的朋友都清楚,性能优化的关键并不在于怎么进行优化,而在于怎么找到当前系统的性能瓶颈.性能优化分为好几个层次,比如系统层次.算法层次.代码层次…JVM 的性能优化被认为是底层优化,门槛较高, ...
- MySQL性能调优与架构设计——第 15 章 可扩展性设计之Cache与Search的利用
第 15 章 可扩展性设计之Cache与Search的利用 前言: 前面章节部分所分析的可扩展架构方案,基本上都是围绕在数据库自身来进行的,这样是否会使我们在寻求扩展性之路的思维受到“禁锢”,无法更为 ...
随机推荐
- Spring学习(九)--Spring的AOP
1.配置ProxyFactoryBean Spring IOC容器中创建Spring AOP的方法. (1)配置ProxyFactoryBean的Advisor通知器 通知器实现定义了对目标对象进行增 ...
- Go-err is shadowed during return
where? Go程序函数中在通过 return关键字返回的时候,报错 why? 变量作用域的问题,在子作用域定义一个上层作用域的同名的变量 package main import ( "e ...
- VARCHART XGantt如何计算截止日期
甘特图从1998年的第一个商用版本开始就致力于计划编制和项目管理方面控件的研究和开发,经过20多年的积累和沉淀,目前可为软件开发商和最终用户提供最顶级的计划编制和项目管理的控件产品,帮助用户快速的整合 ...
- Python练习题 044:Project Euler 016:乘方结果各个数值之和
本题来自 Project Euler 第16题:https://projecteuler.net/problem=16 ''' Project Euler 16: Power digit sum 2* ...
- 国产化之路-统信UOS + Nginx + Asp.Net MVC + EF Core 3.1 + 达梦DM8实现简单增删改查操作
专题目录 国产化之路-统信UOS操作系统安装 国产化之路-国产操作系统安装.net core 3.1 sdk 国产化之路-安装WEB服务器 国产化之路-安装达梦DM8数据库 国产化之路-统信UOS + ...
- linux centos7使用docker安装elasticsearch,并且用Django连接使用
一:elasticsearch安装及配置 1:需求分析 当用户在搜索框输入关键字后,我们要为用户提供相关的搜索结果.这种需求依赖数据库的模糊查询like关键字可以实现,但是like关键字的效率极低,而 ...
- 微型直流电机控制基本方法 L298N模块
控制任务 让单个直流电机在L298N模块驱动下,完成制动.自由停车,正反转,加减速等基本动作 芯片模块及电路设计 图1 L298N芯片引脚 图2 L298N驱动模块 表1 L298N驱动模块的控制引脚 ...
- 【小白学PyTorch】21 Keras的API详解(上)卷积、激活、初始化、正则
[新闻]:机器学习炼丹术的粉丝的人工智能交流群已经建立,目前有目标检测.医学图像.时间序列等多个目标为技术学习的分群和水群唠嗑答疑解惑的总群,欢迎大家加炼丹兄为好友,加入炼丹协会.微信:cyx6450 ...
- 第1天 | 12天搞定Python,告诉你有什么用?
掌握多一门编程语言,多一种选择,多一份机遇,更何况学的是人见人爱,花见花开的Python语言.它目前可占据编程语言排行榜的第3名,是名副其实的"探花郎",无论用它做什么(网络爬虫. ...
- 小白安装使用Redis
Redis属于NoSql中的键值数据库,非常适合海量数据读写. 之前用过mongo但是没有用过redis,今天来学习安装redis. 先去官网下载redis安装包 redis官网 redis是c语言编 ...