1. Deep Q-Learning
传统的强化学习算法具有很强的决策能力,但难以用于高维空间任务中,需要结合深度学习的高感知能力,因此延展出深度强化学习,最经典的就是DQN(Deep Q-Learning)。
DQN 2013
DQN的主要思想是训练CNN拟合出Q-Learning算法,以此让智能体在复杂的RL环境中从原始视频数据学到成功的控制策略。
实现:
- 用参数\(\theta\)的CNN近似最优Q-values
\]
- 结合Bellman最优方程得到第\(i\)次迭代更新的目标
\]
- 定义网络的损失函数
3. 求出梯度
$$\triangledown_{\theta_i}L_i(\theta_i)=\mathbb{E}_{s,a\sim\rho(\cdot);s^\prime\sim\mathcal{E}}\bigg[\Big(r+\gamma\max_{a^\prime}Q(s^\prime,a^\prime;\theta_{i-1})-Q(s,a;\theta_i) \Big)\triangledown_{\theta_i}Q(s,a;\theta_i) \bigg]\]
难点以及解决方法:
- 强化学习假设智能体与环境的交互具有马尔科夫性,而现实中大多任务是部分可观的,智能体很难从当前视频帧\(x_t\)中获取到足够有用的信息。通过动作和观测序列\(s_t=x_1,a_1,x_2,...,a_{t-1},x_t\),人为地设定了MDP
- 训练CNN所需的样本需要相互独立,而RL状态间的相关性极高。通过经验回放机制(experience replay mechansim),保存以前的转移并进行随机采样,缓解数据相关性,保证训练数据分布平滑
- 单帧输入不包含时序信息,因此网络输入是经过预处理的4帧堆叠图像
Nature DQN
Nature DQN主要是对DQN 2013做了修改:
- 网络结构
DQN是一个端到端的模型,输入是预处理后的四帧灰度图像的堆叠,先经过三个卷积层提取特征,然后用两个全连接层作为决策层,最后输出为一个向量,向量的元素对应每个可执行动作的概率值,网络结构如下图:
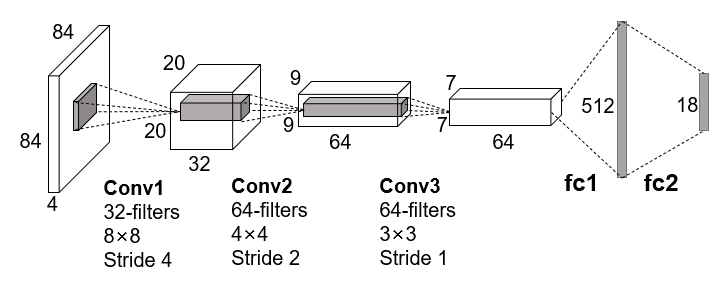
- 减少相关性
DQN 2013的\(Q(s,a)\)和\(r+\gamma\max_{a^\prime}Q(s^\prime,a^\prime)\)之间存在相关性,因此在网络训练过程中损失难以收敛。为了减少它们的相关性,Nature DQN使用了两个网络:主网络用于模型参数的更新,以及\(Q(s,a;\theta_i)\)的拟合;目标网络每隔一个周期对主网络进行一次拷贝,生成近似的目标价值\(r+\gamma \max_{a^\prime}Q(s^\prime,a^\prime;\theta_i^-)\)(\(\theta_i\)是主网络第\(i\)次迭代的参数,\(\theta_i^-\)是目标网络的参数,是从主网络参数\(\theta_{i-1}\)复制得到)。最后,损失函数为
\]
从而得到梯度:
\]
其中,\(D\)是经验回放池,用于存储每一时刻的转移,可以表示为\(e_t=(s_t,a_t,r_t,s_{t+1})\),\(e_t\in D_t=\{e_1,e_2,...,e_t\}\);在学习阶段,用于Q-Learning更新的样本服从于\(U(D)\)分布,即从\(D\)中均匀采样。从梯度公式中可以看出,只需要更新\(\theta_i\),减小了计算量和相关性。训练过程如下图:
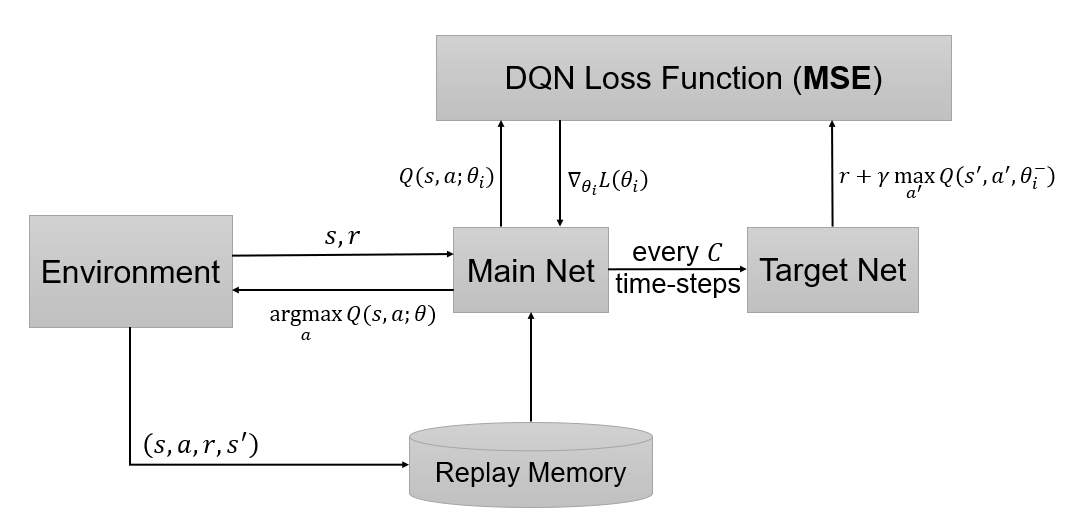
算法伪代码:

References
Volodymyr Mnih et al. Playing Atari with Deep Reinforcement Learning. 2013.
Volodymyr Mnih et al. Human-level control through deep reinforcement learning. 2015.
1. Deep Q-Learning的更多相关文章
- deep Q learning小笔记
1.loss 是什么 2. Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作.如下式,通过更新参数 θθ 使Q函数逼近最优Q值 深度神经网络可以自动提取复杂特征,因此,面对高 ...
- Open source packages on Deep Reinforcement Learning
智能车 self driving car + 强化学习 reinforcement learning + 神经网络 模拟 https://github.com/MorvanZhou/my_resear ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 如何用简单例子讲解 Q - learning 的具体过程?
作者:牛阿链接:https://www.zhihu.com/question/26408259/answer/123230350来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
随机推荐
- Java内部类使用场景和作用
一.Java内部类的分类 Java内部类一般包括四种:成员内部类.局部内部类.匿名内部类和静态内部类 大多数业务需求,不使用内部类都可以解决,那为什么Java还要设计内部类呢. 二.内部类的使用场景 ...
- git线上操作
选择线上仓库 """ 1.注册码云账号并登录:https://gitee.com/ 2.创建仓库(课堂截图) 3.本地与服务器仓库建立连接 ""&qu ...
- Pycharm永久激活2且jetbrains全系列产品
Pycharm永久激活2 注意:本教程补丁来源于https://zhile.io,如有侵权请联系作者删除! 本项目只做学习研究之用,不得用于商业用途! 一.激活前注意事项 PyCharm尽量在官网下载 ...
- @JsonCreator自定义反序列化函数-JSON框架Jackson精解第5篇
Jackson是Spring Boot(SpringBoot)默认的JSON数据处理框架,但是其并不依赖于任何的Spring 库.有的小伙伴以为Jackson只能在Spring框架内使用,其实不是的, ...
- Spring学习(十)Spring知识点汇总
一.基础概念 Q:Spring是什么? 定义:Spring是一个轻量级的IoC(控制反转)和AOP容器框架. 目的:用于简化企业应用程序的开发,使得开发者只需要关心业务需求. 常见的配置方式: 基于X ...
- python基本语法要注意哪些?本文详解!
基本语法 第一个注释 print("hello,python") # 第二行注释 string_demo = "你好!" string_demo print ( ...
- Fowsniff靶机
Fowsniff靶机 主机探测+端口扫描. 扫目录没扫到什么,看一下页面源代码. 网站主页告诉我们这个站现在不提供服务了,并且因为收到了安全威胁,攻击者将他们管理员信息发布到了社交媒体上. 大家要科学 ...
- Emit动态生成代理类用于监控对象的字段修改
利用Emit动态生成代理对象监控对象哪些字段被修改,被修改为什么值 被Register的对象要监控的值必须是Virtual虚类型 必须使用CreateInstance创建对象 必须使用DynamicP ...
- Spring AOP系列(二) — 动态代理引言
接上一篇Spring AOP系列(一)- 代理模式,本篇来聊聊动态代理. 动态代理与静态代理的区别 要想了解动态代理与静态代理的区别,需要有两个前置知识点:java程序是如何执行的以及类加载机制. j ...
- hadoop上传文件失败解决办法
hadoop上传文件到web端hdfs显示hadoop could only be replicated to 0 nodes instead of 1解决办法 错误状态:在hadoop-2.7.2目 ...