elasticsearch如何设计索引
本文为博客园作者所写: 一寸HUI,个人博客地址:https://www.cnblogs.com/zsql/
最近在做es相关的工作,所以记录下自己的一些想法,可能很多方面不会很全面,但是基本都是经过验证的。本文主要是围绕着思考,从多个方面进行考虑,怎么设计索引比较好,直接进入主题吧,本文的es版本为elasticsearch7.8.1。
一、索引设计的重要性
首先索引创建后,索引的分片只能通过_split和_shrink接口对其进行成倍的增加和缩减,主要是因为es的数据是通过_routing分配到各个分片上面的,所以本质上是不推荐去改变索引的分片数量的,因为这样都会对数据进行重新的移动。还有就是索引只能新增字段,不能对字段进行修改和删除,缺乏灵活性,所以每次都只能通过_reindex重建索引了。还有就是一个分片的大小以及所以分片数量的多少严重影响到了索引的查询和写入性能。所以可想而知,设计一个好的索引能够减少后期的运维管理和提高不少性能。所以前期对索引的设计是相当的重要的。
- 好的索引设计在整个集群规划中占据举足轻重的作用,索引的设计直接影响集群设计的好坏和复杂度。
- 好的索引设计应该是充分结合业务场景的时间维度和空间维度,结合业务场景充分考量增、删、改、查等全维度设计的。
- 好的索引设计是完全基于“设计先行,编码在后”的原则,前期会花很长时间,为的是后期工作更加顺畅,避免不必要的返工
二、如何设计索引
在设计索引之前我们要明白索引有些什么内容,明白索引的构成,比如索引的基本配置setting,映射mapping,还有重要的分片,副本,模板,索引的生命周期等。知道这些之后就可以有针对性的设计了。首先要结合公司的业务场景,数据量的大小,每天增量如何,数据的特点,会不会对历史数据进行重新更新。数据存多久,是永久还是有一定的周期。数据需要准实时呢还是不需要准实时呢。所以清楚索引的构成和知道业务场景,才能够结合起来做更好的设计。
2.1、考虑索引的公共基本配置
由于elasticsearch7.x不允许把索引级别的设置配置在elasticsearch.yml中,所以需要对每个索引进行单独的配置,这样的话就比较麻烦,所以可以把这些公共的配置配置在索引模板中,这样就可以在新建索引的时候可以自动的设置到索引中,关于索引模板的操作可以看考:聊聊elasticsearch7.8的模板和动态映射
接下来看看一些常用索引级别的配置
"number_of_replicas": 1, #推荐副本数为1
"max_result_window": 100000,
"refresh_interval": "30s", #这里对实时性要求不高,可以增加该值提高写入性能
"index.search.slowlog.threshold.query.warn": 10s,
"index.search.slowlog.threshold.query.info": 5s,
"index.search.slowlog.threshold.query.debug": 2s,
"index.search.slowlog.threshold.query.trace": 500ms,
"index.search.slowlog.threshold.fetch.warn": 1s,
"index.search.slowlog.threshold.fetch.info": 800ms,
"index.search.slowlog.threshold.fetch.debug": 500ms,
"index.search.slowlog.threshold.fetch.trace": 200ms,
"index.indexing.slowlog.threshold.index.warn": 10s,
"index.indexing.slowlog.threshold.index.info": 5s,
"index.indexing.slowlog.threshold.index.debug": 2s,
"index.indexing.slowlog.threshold.index.trace": 500ms
"dynamic": false #是否关闭动态字段映射,默认为true,这里选择个人选择禁用
当然索引的配置还有很多其他的,可以根据实际情况进行调整,这样就可以把需要配置公共索引配置设计成索引模板:
PUT _index_template/template_index
{
"index_patterns": [
"index-*"
],
"template": {
"settings": {
"number_of_replicas": 1,
"max_result_window": 100000,
"refresh_interval": "30s",
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms",
"index.indexing.slowlog.threshold.index.warn": "10s",
"index.indexing.slowlog.threshold.index.info": "5s",
"index.indexing.slowlog.threshold.index.debug": "2s",
"index.indexing.slowlog.threshold.index.trace": "500ms"
},
"mappings": {
"dynamic": false
}
},
"priority": 10
}
这样新建index-开头的索引的时候都会默认配置好如上的配置,这样就是考虑到基本设置公共化
2.2、索引命名规范
这部分主要说下索引命名规范,包括别名,通过别名可以使得索引的操作变得更加灵活,一个索引可以有多个别名,当然一个别名可以配置多个索引,这样的话就极大的增加了索引的的灵活性。在索引的命名上规定特殊字段开头,同样对其好进行权限控制,关于权限控制可以参考:elasticsearch7.8权限控制和规划
必须严格按照如下命名格式:(否则将无法使用,因为这里设置了相关权限);
- 索引命名规范:index-{行业}-{业务}-{版本}
- 别名命名规范:index-{行业}-{业务}
如果是索引拆分后(有多个索引),需要一个全局的读的别名对所有拆分后的所有进行命名,和一个最新索引写的别名(只对可更新的索引),如果这里没有描述清楚,请见2.5大索引的设计,两个别名可规范如下:
- 读别名:index-{行业}-{业务}-read
- 写别名:index-{行业}-{业务}-insert
2.3、mapping的设计
mapping设置主要就是怎么选择数据类型,分词等
中文分词:推荐使用:"analyzer": "ik_max_word" ,这样可以更细粒度的进行中文分词
设置字段的时候,务必过一下如下图示的流程。根据实际业务需要,主要关注点:
- 数据类型选型;
- 是否需要检索;
- 是否需要排序+聚合分析;
- 是否需要另行存储
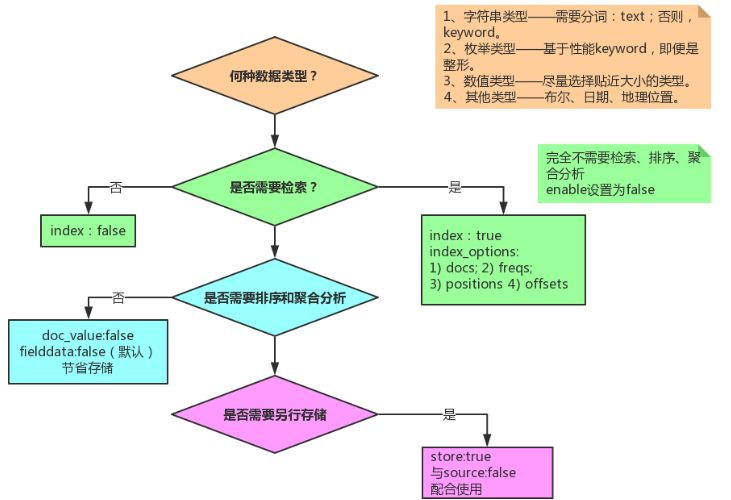
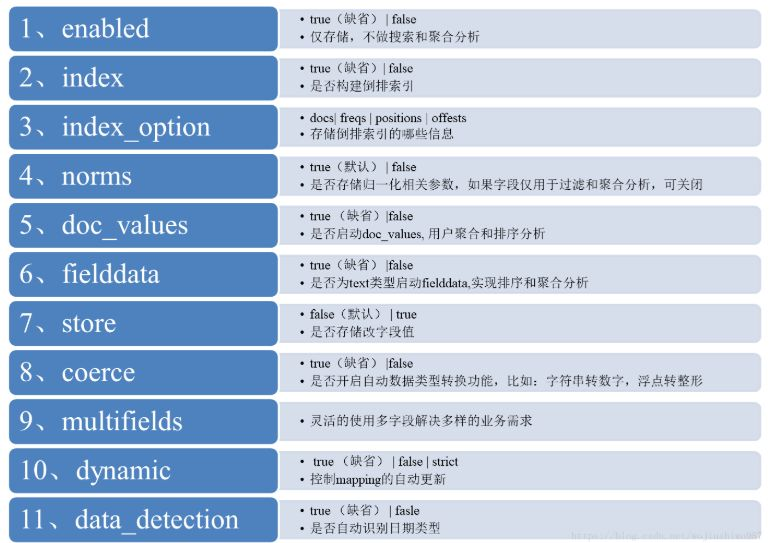
核心参数的含义,梳理如下
2.4、分片的设计
这个很重要,直接影响到后期的管理和性能。
Elasticsearch中的数据组织成索引。每一个索引由一个或多个分片组成。每个分片是Luncene索引的一个实例,你可以把实例理解成自管理的搜索引擎,用于在Elasticsearch集群中对一部分数据进行索引和处理查询。
分片设计原则
- 推荐每个分片的大小:20-40G,建议不超过30G,但是也会有特殊的情况,有些索引字段少,但是数据量大,这样的话也可以增加一些分片数
- 确保每个节点的分片数量保持在低于每1GB堆内存对应集群的分片在20-25之间。 因此,具有30GB堆内存的节点最多可以有600-750个分片
- 每个索引的分片:一般为节点数的1-3倍,假设我们有15个数据节点,则15*3*40G=1.8T,这样一个索引最多设置真的大,如果超过了,就需要参考大索引的设计
- 分片数量尽量为数据节点的倍数,这样就可以使得数据进来均衡,但是数据量极少的索引,根据情况进行分片数量的设计
下面写一个简单的参考表(都可以根据实际情况进行调整,只是个人的建议):
| 索引的大小 | 分片数量设置 |
| 0-20G | 2 |
| 20-100G | 8 |
| 100-400G | 15 |
| 400-900G | 30 |
| 900G-1.6T | 45 |
如上设置是基于15个数据节点进行配置的,基本都给增量预留了一些空间,最好是根据实际情况进行设定,如果一个索引已经很大了,上面的配置不能满足了的话需要对对索引进行拆分了,使用索引模板+Rollover+索引生命周期进行自动滚动,拆分索引。见2.5节
2.5、大索引的设计
当一个索引太大时就会有很多的风险,首先会影响性能,当分片数一定的情况下,数据越来越多,一个分片就会越来越大,就会违背了上面的设计原则,其次就是一个索引出问题,很难恢复,并且影响范围广,那如何对很大的索引进行设计呢。可以使用索引模板+Rollover+生命周期进行自动滚动创建索引,所有的索引都用一个别名进行读,并且设置一个索引为写,这样就能够很好的拆分索引。先看看这么设计的原理图。
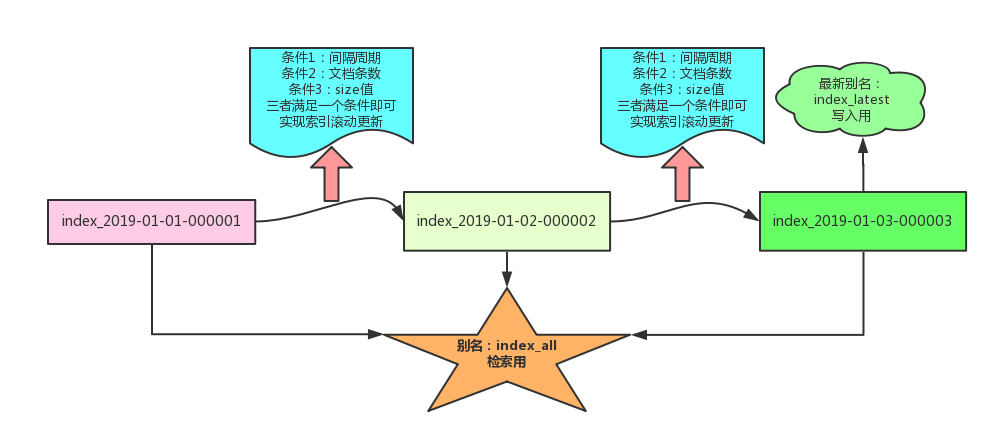
上面有三个索引,通过index_all索引进行检索,是用index_latest保证只写入到一个最新的索引中,每次索引满足三个条件(文档数,时间,索引大小)中的一个,就会自动的滚动生成新的索引。接下来做个实操,这样更方面理解。
先来个官网,有兴趣的可以参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.8/getting-started-index-lifecycle-management.html
主要分为四个步骤:
- 创建索引生命周期的规则
- 创建索引模板并应用该生命周期
- 初始化一个索引
- 验证
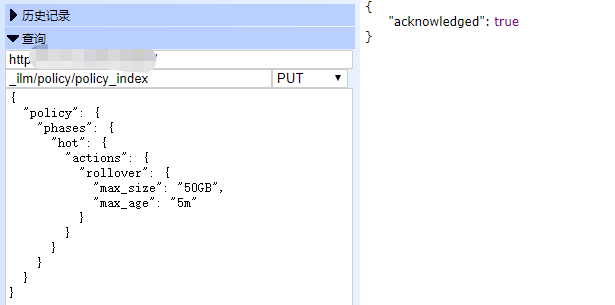
首先创建生命周期的规则,对于索引的生命周期可以参考:对Elasticsearch生命周期的思考,如果数据是定期存储的,比如一些日志,只保留最近30天,这样的数据结合索引的生命周期可以自动的进行清理。我们首先创建一个策略policy_index,这里是测试,所以把时间调至5分钟,这些配置都应该根据实际情况进行设置。
PUT _ilm/policy/policy_index
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50GB",
"max_age": "5m"
}
}
}
}
}
}
接下来设计索引模板,并且该策略应用进去。
PUT _index_template/policy_index_template
{
"index_patterns": [
"index-test-*"
],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "policy_index", #配置策略
"index.lifecycle.rollover_alias": "index-test-insert"
},
"aliases": {
"index-test-read": {
"is_write_index": false #这个别名是用来读的,不允许写,否则会和写的那个别名冲突
}
}
}
}
这里的模板只是为了演示该小节的内容,实际情况应该把基本配置以及mapping相关的设置好

接下来就是创建一个索引了
PUT index-test-000001

创建好之后,然后给索引添加别名index-test-insert,索引就自动有了两个别名,read负责读,insert负责写
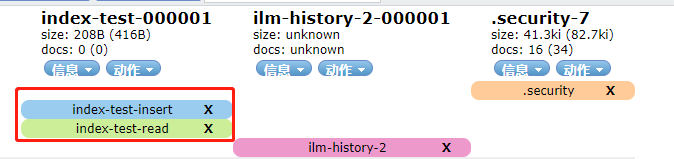
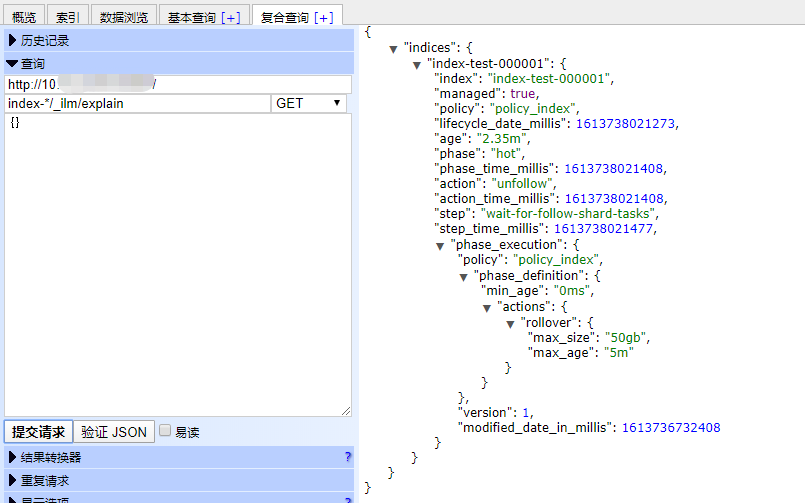
接下来,只要通过验证即可:GET index-*/_ilm/explain
最后达到条件后就会自动生成新的索引,然后把index-test-insert别名切换到新的索引上面,就是这样子的
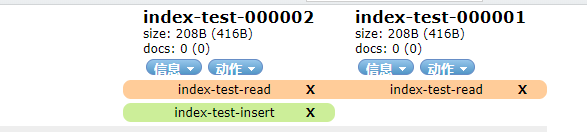
大索引的设计就是拆分,很多都是根据时间进行切分索引的,如果记得没错的话,上面的000001这些可以配置为日期的。
参考博文:
https://mp.weixin.qq.com/s/KQQJfKCOuqadTujbLNu5aA
elasticsearch如何设计索引的更多相关文章
- elasticsearch如何设计集群
本文为博客园作者所写: 一寸HUI,个人博客地址:https://www.cnblogs.com/zsql/ 在写本文时就在想,如果让你负责一个elasticsearch集群,从零开始,你会从哪些方面 ...
- Elasticsearch 关键字:索引,类型,字段,索引状态,mapping,文档
1. 索引(_index)索引:说的就是数据库的名字.我这个说法是对应到咱经常使用的数据库. 结合es的插件 head 来看. 可以看到,我这个地方,就有这么几个索引,索引就是数据库,后面是这个数据库 ...
- Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析
Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析 生鲜电商搜索引擎的特点 众所周知,标准的搜索引擎主要分成三个大的部分,第一步是爬虫系统,第二步是数据分析,第三步才 ...
- Elasticsearch 之 数据索引
对于提供全文检索的工具来说,索引时一个关键的过程——只有通过索引操作,才能对数据进行分析存储.创建倒排索引,从而让使用者查询到相关的信息. 本篇就ES的数据索引操作相关的内容展开: 更多内容参考:El ...
- Mysql设计索引的原则
内容来自书籍<深入浅出MySQL++数据库开发.优化与管理维护+第2版+唐汉明> 设计索引的原则1. 搜索的索引列,不一定是所要选择的列.换句话说,最适合索引的列是出现在 WHERE 子句 ...
- elasticsearch查询篇索引映射文档数据准备
elasticsearch查询篇索引映射文档数据准备 我们后面要讲elasticsearch查询,先来准备下索引,映射以及文档: 我们先用Head插件建立索引film,然后建立映射 POST http ...
- ElasticSearch创建动态索引
ElasticSearch创建动态索引 需求:某实例需要按照月份来维护,所以之前的“写死”索引的方式当然不行了.通过百度和看SpringDataElasticSearch官方文档,最后解决了这个问题. ...
- elasticsearch 内部对象结构数据索引
内部对象 经常用于 嵌入一个实体或对象到其它对象中.例如,与其在 tweet 文档中包含 user_name 和 user_id 域,我们也可以这样写: { "tweet": &q ...
- 阿里面试:MySQL如何设计索引更高效?
有情怀,有干货,微信搜索[三太子敖丙]关注这个不一样的程序员. 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点.资料以及我的系列文章. ...
随机推荐
- QT之——QTableWidget拖拽单元格并替换内容(进阶)
所需待重写函数: [virtual] bool QObject::eventFilter(QObject *watched, QEvent *event); /* * Filters events i ...
- Gitlab + DRBD HA
部署简介: 为了gitlab有容灾的能力,所以部署一个HA的小集群,用到的软件有 gitlab 和brbd,目前现有环境为 master节点 系统版本:CentOS release 6.5 (Fina ...
- Linux常用命令,目录解析,思维导图
文章目录 下载地址 Linux常用命令 linux系统常用快捷键及符号命令 Linux常用Shell命令 Linux系统目录解析 Shell Vi全文本编辑器 Linux安装软件 Linux脚本编制编 ...
- 使用Docker Compose编排Spring Cloud微服务
文章目录 微服务构建实例 简化Compose的编写 编排高可用的Eureka Server 编排高可用Spring Cloud微服务集群及动态伸缩 微服务项目名称 项目微服务中的角色 microser ...
- python工业互联网应用实战5—Django Admin 编辑界面和操作
1.1. 编辑界面 默认任务的编辑界面,对于model属性包含"choices"会自动显示下来列表供选择,"datetime"数据类型也默认提供时间选择组件,如 ...
- 一文入门Linux下gdb调试(二)
作者:良知犹存 转载授权以及围观:欢迎添加微信号:Conscience_Remains 总述 今天我们介绍一下core dump文件,Core dump叫做核心转储,它是进程运行时在突然崩溃的 ...
- C语言实现2048小游戏
目录 2048 一.设计思路 1.游戏规则 2.思路 二.代码实现 1.存储结构 2.初始化游戏数据 3.向左合并 4.其他方向合并 5.产生新的方块 6.源代码 7.实例演示 三.问题 2048 一 ...
- The Department of Redundancy Department
Write a program that will remove all duplicates from a sequence of integers and print the list of un ...
- POJ-3208 Apocalypse Someday (数位DP)
只要某数字的十进制表示中有三个6相邻,则该数字为魔鬼数,求第X小的魔鬼数\(X\le 5e7\) 这一类题目可以先用DP进行预处理,再基于拼凑思想,用"试填法"求出最终的答案 \( ...
- HDOJ 1348 基本二维凸包问题
这次写的凸包用的是Graham scan算法 就数据结构上只是简单地运用了一个栈 #include<stdio.h>#include<cmath>#include<alg ...