ElasticSearch 文档及操作
公号:码农充电站pro
主页:https://codeshellme.github.io
本节介绍 ES 文档,索引及其基本操作。
1,ES 中的文档
在 ES 中,文档(Document)是可搜索数据的最小存储单位,相当于关系数据库中的一条记录。
文档以 Json 数据格式保存在 ES 中,Json 中保存着多个键值对,它可以保存不同类型的数据,比如:
- 字符串类型
- 数字类型
- 布尔类型
- 数组类型
- 日期类型
- 二进制类型
- 范围类型
Python 语言中的字典类型,就是 Json 数据格式。
文档中的数据类型可以指定,也可以由 ES 自动推断。
每个文档中都有一个 Unique ID,用于唯一标识一个文档。Unique ID 可以由用户指定,也可以由 ES 自动生成。
Unique ID 实际上是一个字符串。
比如下面的 Json 就是一个文档:
{
"name" : "XiaoMing",
"age" : 19,
"gender" : "male"
}
1.1,文档元数据
将上面那个 Json 数据存储到 ES 后,会像下面这样:
{
"_index": "person",
"_type": "_doc",
"_id": "2344563",
"_version": 1,
"_source": {
"name": "XiaoMing",
"age": 19,
"gender": "male"
}
}
其中以下划线开头的字段就是元数据:
_index:文档所属的索引。_type:文档的类型。ES 7.0 开始,一个索引只能有一种_type。_id:文档的唯一 ID。_source:文档的原始 Json 数据。_version:文档更新的次数。
你可以查看这里,了解“为什么单个Index下,不再支持多个Tyeps?”。
更多关于元数据的信息,可以参考这里。
1.2,文档的删除与更新
ES 中文档的删除操作不会马上将其删除,而是会将其标记到 del 文件中,在后期合适的时候(比如 Merge 阶段)会真正的删除。
ES 中的文档是不可变更的,更新操作会将旧的文档标记为删除,同时增加一个新的字段,并且文档的 version 加 1。
1.3,文档中的字段数
在 ES 中,一个文档默认最多可以有 1000 个字段,可以通过 index.mapping.total_fields.limit 进行设置。
注意在设计 ES 中的数据结构时,不要使文档的字段数过多,这样会使得 mapping 很大,增加集群的负担。
2,ES 中的索引
ES 中的文档都会存储在某个索引(Index)中,索引是文档的容器,是一类文档的集合,相当于关系型数据库中的表的概念。
ES 中可以创建很多不同的索引,表示不同的文档集合。
每个索引都可以定义自己的 Mappings 和 Settings:
Mappings:用于设置文档字段的类型。Settings:用于设置不同的数据分布。
对于索引的一些参数设置,有些参数可以动态修改,有些参数在索引创建后不能修改,可参考这里。
ES 与传统数据库类比
如果将 ES 中的基本概念类比到传统数据库中,它们的对应关系如下:
| ES | 传统数据库 |
|---|---|
| 索引 | 表 |
| 文档 | 行 |
| 字段 | 列 |
| Mapping | 表定义 |
| DSL | SQL 语句 |
索引相关 API
下面给出一些查看索引相关信息的 API:
# 查看索引相关信息
GET index_name
# 查看索引的文档总数
GET index_name/_count
# 查看指定索引的前10条文档
POST index_name/_search
{
}
#_cat indices API
# 查看所有的索引名以 index_prefix 为前缀的索引
GET /_cat/indices/index_prefix*?v&s=index
# 查看状态为 green 的索引
GET /_cat/indices?v&health=green
# 按照文档个数排序
GET /_cat/indices?v&s=docs.count:desc
# 查看指定索引的指定信息
GET /_cat/indices/index_prefix*?pri&v&h=health,index,pri,rep,docs.count,mt
# 查看索引使用的内存大小
GET /_cat/indices?v&h=i,tm&s=tm:desc
3,GET 操作
GET 操作可以获取指定文档的内容。
GET index_name/_count:获取指定索引中的文档数。
GET index_name/_doc/id:获取指定索引中的指定文档。
GET index_name/_doc:不允许该操作。
GET index_name:获取指定索引的 Mappings 和 Settings。
4,POST / PUT 操作
POST/PUT 操作用于创建文档。
按照 POST / PUT 方法来区分
POST index_name/_doc:
POST index_name/_doc:不指定 ID,总是会插入新的文档,文档数加 1。POST/PUT index_name/_doc/id:指定 ID- 当 id 存在时,会覆盖之前的,并且 version 会加 1,文档数不增加。
- 当 id 不存在时,会插入新的文档,文档数加 1。
PUT index_name/_create:
PUT index_name/_create:不指定 ID,不允许该操作。PUT index_name/_create/id:指定 ID- 当 id 存在时:报错,不会插入新文档。
- 当 id 不存在时:,会插入新的文档,文档数加 1。
PUT index_name/_doc:
PUT index_name/_doc:不指定 ID,不允许该操作。PUT/POST index_name/_doc/id:指定 ID- 当 id 存在时,会覆盖之前的,并且 version 会加 1,文档数不增加。
- 当 id 不存在时,会插入新的文档,文档数加 1。
PUT index_name/_doc/id?op_type=XXX
op_type=create:- 当 id 存在时,报错,不会插入新文档。
- 当 id 不存在时,会插入新的文档,文档数加 1。
op_type=index:- 当 id 存在时,会覆盖之前的,并且 version 会加 1,文档数不增加。
- 当 id 不存在时,会插入新的文档,文档数加 1。
按照是否指定 ID 来区分
指定 ID:
POST/PUT index_name/_doc/id:指定 ID,称为 Index 操作- 相当于
PUT index_name/_doc/id?op_type=index - 当 id 存在时,会覆盖之前的,并且 version 会加 1,文档数不增加。
- 当 id 不存在时,会插入新的文档,文档数加 1。
- 相当于
PUT index_name/_doc/id?op_type=create:指定 ID,称为 Create 操作- 相当于
PUT index_name/_create/id - 当 id 存在时,报错,不会插入新文档。
- 当 id 不存在时,会插入新的文档,文档数加 1。
- 相当于
不指定 ID:
POST index_name/_doc:不指定 ID,总是会插入新的文档,文档数加 1。PUT index_name/_doc:不指定 ID,不允许该操作。PUT index_name/_create:不指定 ID,不允许该操作。
5,Update 操作
Update 操作用于更新文档的内容。
POST index_name/_update/id/:更新指定文档的内容。更新的内容要放在 doc 字段中,否则会报错。
- 当 id 不存在时,报错,不更新任何内容。
- 当 id 存在时:
- 如果更新的字段与原来的相同,则不做任何操作。
- 如果更新的字段与原来的不同,则更新原有内容,并且 version 会加 1。
实际上 ES 中的文档是不可变更的,更新操作会将旧的文档标记为删除,同时增加一个新的字段,并且文档的 version 加 1。
6,Delete 操作
Delete 操作用于删除索引或文档。
DELETE /index_name/_doc/id:删除某个文档。
- 当删除的 id 存在时,会删除该文档。
- 当删除的 id 不存在时,ES 会返回
not_found。
DELETE /index_name:删除整个索引,要谨慎使用!
- 当删除的 index_name 存在时,会删除整个索引内容。
- 当删除的 index_name 不存在时,ES 会返回
404错误。
7,Bulk 批量操作
批量操作指的是,在一次 API 调用中,对不同的索引进行多次操作。
每次操作互不影响,即使某个操作出错,也不影响其他操作。
返回的结果中包含了所有操作的执行结果。
Bulk 支持的操作有 Index,Create,Update,Delete。
Bulk 操作的格式如下:
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test2", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
注意 Bulk 请求体的数据量不宜过大,建议在 5~15M。
8,Mget 批量读取
Mget 一次读取多个文档的内容,设计思想类似 Bulk 操作。
Mget 操作的格式如下:
GET _mget
{
"docs" : [
{"_index" : "index_name1", "_id" : "1"},
{"_index" : "index_name2", "_id" : "2"}
]
}
也可以在 URI 中指定索引名称:
GET /index_name/_mget
{
"docs" : [
{"_id" : "1"},
{"_id" : "2"}
]
}
还可以用 _source 字段来设置返回的内容:
GET _mget
{
"docs" : [
{"_index" : "index_name1", "_id" : "1"},
{"_index" : "index_name2", "_id" : "2", "_source" : ["f1", "f2"]}
]
}
9,Msearch 批量查询
Msearch 操作用于批量查询,格式如下:
POST index_name1/_msearch
{} # 索引名称,不写的话就是 URI 中的索引
{"query" : {"match_all" : {}},"size":1}
{"index" : "index_name2"} # 改变了索引名称
{"query" : {"match_all" : {}},"size":2}
URI 中也可以不写索引名称,此时请求体里必须写索引名称:
POST _msearch
{"index" : "index_name1"} # 索引名称
{"query" : {"match_all" : {}},"size":1}
{"index" : "index_name2"} # 索引名称
{"query" : {"match_all" : {}},"size":2}
上文中介绍了 3 种批量操作,分别是 Bulk,Mget,Msearch。注意在使用批量操作时,数据量不宜过大,避免出现性能问题。
10,ES 常见错误码
当我们的请求发生错误的时候,ES 会返回相应的错误码,常见的错误码如下:
| 错误码 | 含义 |
|---|---|
| 429 | 集群过于繁忙 |
| 4XX | 请求格式错误 |
| 500 | 集群内部错误 |
11,Reindex 重建索引
有时候我们需要重建索引,比如以下情况:
- 索引的
mappings发生改变:比如字段类型或者分词器等发生更改。 - 索引的
settings发生改变:比如索引的主分片数发生更改。 - 集群内或集群间需要做数据迁移。
ES 中提供两种重建 API:
- Update by query:在现有索引上重建索引。
- Reindex:在其它索引上重建索引。
11.1,添加子字段
先在一个索引中插入数据:
DELETE blogs/
# 写入文档
PUT blogs/_doc/1
{
"content":"Hadoop is cool",
"keyword":"hadoop"
}
# 查看自动生成的 Mapping
GET blogs/_mapping
# 查询文档
POST blogs/_search
{
"query": {
"match": {
"content": "Hadoop"
}
}
}
# 可以查到数据
现在修改 mapping(添加子字段是允许的),为 content 字段加入一个子字段:
# 修改 Mapping,增加子字段,使用英文分词器
PUT blogs/_mapping
{
"properties" : {
"content" : { # content 字段
"type" : "text",
"fields" : { # 加入一个子字段
"english" : { # 子字段名称
"type" : "text", # 子字段类型
"analyzer":"english" # 子字段分词器
}
}
}
}
}
# 查看新的 Mapping
GET blogs/_mapping
修改 mapping 之后再查询文档:
# 使用 english 子字段查询 Mapping 变更前写入的文档
# 查不到文档
POST blogs/_search
{
"query": {
"match": {
"content.english": "Hadoop"
}
}
}
# 注意:不使用 english 子字段是可以查询到之前的文档的
POST blogs/_search
{
"query": {
"match": {
"content": "Hadoop"
}
}
}
结果发现,使用 english 子字段是查不到之前的文档的。这时候就需要重建索引。
11.2,Update by query
下面使用 Update by query 对索引进行重建:
# Update所有文档
POST blogs/_update_by_query
{
}
重建索引之后,不管是使用 english 子字段还是不使用,都可以查出文档。
Update by query 操作还可以设置一些条件:
- uri-params
- request-body:通过设置一个 query 条件,来指定对哪些数据进行重建。
request-body 示例:
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{
"query": { # 将 query 的查询结果进行重建
"bool": {
"must_not": {
"exists": {"field": "views"}
}
}
}
}
11.3,修改字段类型
在原有 mapping 上,修改字段类型是不允许的:
# 会发生错误
PUT blogs/_mapping
{
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"english" : {
"type" : "text",
"analyzer" : "english"
}
}
},
"keyword" : { # 修改 keyword 字段的类型
"type" : "keyword"
}
}
}
这时候只能创建一个新的索引,设置正确的字段类型,然后再将原有索引中的数据,重建到新索引中。
建立一个新的索引 blogs_new:
# 创建新的索引并且设定新的Mapping
PUT blogs_new/
{
"mappings": {
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"english" : {
"type" : "text",
"analyzer" : "english"
}
}
},
"keyword" : {
"type" : "keyword"
}
}
}
}
11.4,Reindex
下面使用 Reindex 将原来索引中的数据,导入到新的索引中:
# Reindx API
POST _reindex
{
"source": { # 指定原有索引
"index": "blogs"
},
"dest": { # 指定目标索引
"index": "blogs_new"
}
}
Reindex API 中的 source 字段和 dest 字段还有很多参数可以设置,具体可参考其官方文档。
另外 Reindex 请求的 URI 中也可以设置参数,可以参考这里。
12,ES 的并发控制
同一个资源在多并发处理的时候,会发生冲突的问题。
传统数据库(比如 MySQL)会采用锁的方式,在更新数据的时候对数据进行加锁,来防止冲突。
而 ES 并没有采用锁,而是将并发问题交给了用户处理。
在 ES 中可以采用两种方式:
- 内部版本控制(ES 自带的 version):在 URI 中使用
if_seq_no和if_primary_term - 外部版本控制(由用户指定 version):在 URI 中使用
version和version_type=external
示例,首先插入数据:
DELETE products
PUT products/_doc/1
{
"title":"iphone",
"count":100
}
# 上面的插入操作会返回 4 个字段:
#{
# "_id" : "1",
# "_version" : 1,
# "_seq_no" : 0,
# "_primary_term" : 1
#}
12.1,内部版本控制方式
使用内部版本控制的方式:
PUT products/_doc/1?if_seq_no=0&if_primary_term=1
{
"title":"iphone",
"count":100
}
# 上面的更新操作返回下面内容:
#{
# "_id" : "1",
# "_version" : 2, # 加 1
# "_seq_no" : 1, # 加 1
# "_primary_term" : 1 # 不变
#}
如果再次执行这句更新操作,则会出错,出错之后由用户决定如何处理,这就达到了解决冲突的目的。
# 再执行则会出错,因为 seq_no=0 且 primary_term=1 的数据已经不存在了
PUT products/_doc/1?if_seq_no=0&if_primary_term=1
12.2,外部版本控制方式
先看下数据库中的数据:
GET products/_doc/1
# 返回:
{
"_index" : "products",
"_type" : "_doc",
"_id" : "1", # id
"_version" : 2, # version
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "iphone",
"count" : 100
}
}
使用外部版本控制的方式:
# 如果 URI 中的 version 值与 ES 中的 version 值相等,则出错
# 下面这句操作会出错,出错之后,由用户决定如何处理
PUT products/_doc/1?version=2&version_type=external
{
"title":"iphone",
"count":1000
}
# 如果 URI 中的 version 值与 ES 中的 version 值不相等,则成功
# 下面这句操作会成功
PUT products/_doc/1?version=3&version_type=external
{
"title":"iphone",
"count":1000
}
13,使用 Ingest 节点对数据预处理
Ingest 节点用于对数据预处理,它是在 ES 5.0 后引入的一种节点类型,可以达到一定的 Logstash 的功能。
默认情况下,所有的节点都是 Ingest 节点。
Ingest 节点通过添加一些 processors 来完成特定的处理,Pipeline 可以看做是一组 processors 的顺序执行。
Ingest 节点的处理阶段如下图所示:

13.0,Ingest 节点与 Logstash 对比
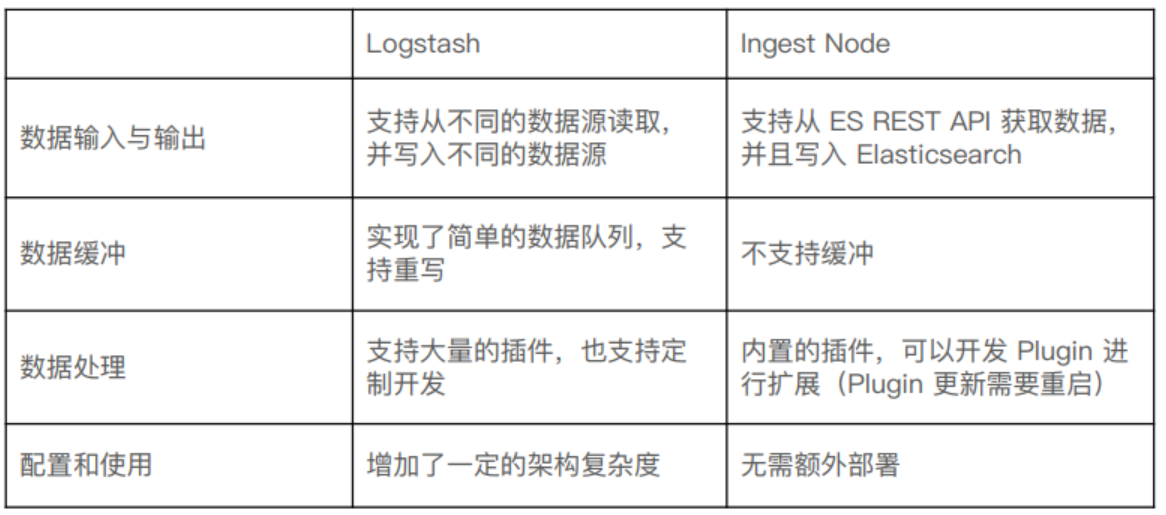
13.1,内置的 Processors
ES 中内置了很多现成的 Processors 供我们使用:
- Append:向一个数组类型的字段加入更多的值。
- Split:将字符串拆分成数组。
- Set:设置一个字段。
- Uppercase:大写转换。
- Lowercase:小写转换。
- Remove:移除一个已存在的字段。如果字段不存在,将抛出异常。
- Rename:为一个字段重命名。
- Convert:转换一个字段的数据类型。比如将字符串类型转换成整数类型。
- Date:日期格式转换。
- JSON:将 json 字符串转换成 JSON 类型。
- Date-index-name:将通过该处理器的文档,分配到指定时间格式的索引中。
- Fail:当出现异常的时候,将指定的信息返回给用户。
- Foreach:用于处理数组类型的数据。
- Pipeline:引用另一个 Pipeline。
- Trim:删除字符换的前置和后置空格。
- Sort:对数组中的元素排序。
- Url-decode:对字符串进行 URL 解码。
- User-agent:用于解析 User-Agent 信息。
- Html-strip:用于移除 HTML 标签。
- Script:用 Painless 语言编写脚本,以支持更复杂的功能。
- Painless 语言是专门为 ES 设计的,在 ES 5.x 引入,具有高性能和安全性。
- ES 6.0 开始,ES 只支持 Painless 脚本,不再支持其它语言脚本(比如 JavaScript,Python 等)。
- Painless 基于 Java 语言,并支持所有的 Java 数据类型。
- 等
13.2,测试 Processors
ES 中提供了一个 simulate 接口,用于测试 Processors。
示例:
POST _ingest/pipeline/_simulate
{
"pipeline": { # 定义 pipeline
"description": "to split blog tags", # 描述
"processors": [ # 一系列的 processors
{
"split": { # 一个 split processor
"field": "tags",
"separator": "," # 用逗号分隔
}
},
{
"set":{ # 可以设置多个 processor
"field": "views",
"value": 0
}
}
]
},
"docs": [ # 测试的文档
{ # 第 1 个文档
"_index": "index",
"_id": "id",
"_source": {
"title": "Introducing big data......",
"tags": "hadoop,elasticsearch,spark",
"content": "You konw, for big data"
}
},
{ # 第 2 个文档
"_index": "index",
"_id": "idxx",
"_source": {
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
}
]
}
13.3,添加一个 Pipeline
当 Processors 测试通过后,可以向 ES 中添加(设置)一个 Pipeline,语法:
# blog_pipeline 为 pipeline 名称
PUT _ingest/pipeline/blog_pipeline
{
"description": "a blog pipeline",
"processors": [
{
"split": { # 第 1个 Processor
"field": "tags",
"separator": ","
}
},
{
"set":{ # 第 2个 Processor
"field": "views",
"value": 0
}
}
]
}
13.4,查看 Pipeline
# 查看 Pipleline
GET _ingest/pipeline/blog_pipeline
# 删除 Pipleline
DELETE _ingest/pipeline/blog_pipeline
13.5,测试 Pipeline
# blog_pipeline 是 Pipeline 名称
POST _ingest/pipeline/blog_pipeline/_simulate
{
"docs": [
{ # 一个文档
"_source": {
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
}
]
}
13.6,使用 Pipeline
使用 Pipeline 插入文档时,文档会先经过 Pipeline 的处理,然后再插入到 ES 中。
# URI 中指定了 Pipeline 的名字
PUT tech_blogs/_doc/2?pipeline=blog_pipeline
{
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
最终插入的文档是这样的:
{
"title": "Introducing cloud computering",
"tags": ["openstack", "k8s"],
"content": "You konw, for cloud",
"views": 0
}
另外 update-by-query(重建索引)的 URI 中也可以设置 pipeline 参数来使用一个 Pipeline。
14,总结
上文介绍到的所有操作,可以参考 ES 的官方文档。
(本节完。)
推荐阅读:
Kibana,Logstash 和 Cerebro 的安装运行
欢迎关注作者公众号,获取更多技术干货。

ElasticSearch 文档及操作的更多相关文章
- ElasticSearch文档操作介绍三
ElasticSearch文档的操作 文档存储位置的计算公式: shard = hash(routing) % number_of_primary_shards 上面公式中,routing 是一个可变 ...
- ElasticStack学习(四):ElasticSearch文档使用与操作
一.文档的CRUD介绍 ElasticSearch中存在五种操作,分别如下: 1.Index 该操作表示:如果文档的ID不存在,则创建新的文档.若有相同的ID,先删除现有文档,然后再创建新的文档,同时 ...
- 关于Elasticsearch文档的描述以及如何操作文档的详细总结
文档 什么是文档 在大多数应用中,多数实体或对象可以被序列化为包含键值对的 JSON 对象. 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些 ...
- elasticsearch 文档
elasticsearch 文档 文档格式 索引中最基本的单元叫做文档 document. 在es中文档的示例如下: { "_index": "questions&quo ...
- elasticsearch文档-modules
elasticsearch文档-modules modules 模块 cluster 原文 基本概念 cluster: 集群,一个集群通常由很多节点(node)组成 node: 节点,比如集群中的每台 ...
- Elasticsearch文档查询
简单数据集 到目前为止,已经了解了基本知识,现在我们尝试用更逼真的数据集,这儿已经准备好了一份虚构的JSON,关于客户银行账户信息的.每个文档的结构如下: { , , "firstname& ...
- elasticsearch 文档阅读笔记(三)
文档 elasticsearch是通过document的形式存储数据的,个人理解文档就是一条数据一个对象 我们添加索引文档中不仅包含了数据还包含了元数据 比如我们为一个数据添加索引 文档中不仅有jso ...
- Elasticsearch入门教程(四):Elasticsearch文档CURD
原文:Elasticsearch入门教程(四):Elasticsearch文档CURD 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接: ...
- C# 使用XmlDocument类对XML文档进行操作
原创地址:http://www.cnblogs.com/jfzhu/archive/2012/11/19/2778098.html 转载请注明出处 W3C制定了XML DOM标准.很多编程语言中多提供 ...
随机推荐
- Java——序列化与反序列化
序列化 序列化 序列化是什么 如何实现对象序列化 实战练习 Serializable 反序列化 总结 使用Reader读取文件内容1 使用Reader读取文件内容2 序列化是什么? 将对象的状态存储到 ...
- GeoMesa,整体架构,创建Schema并导入数据
GeoMesa,整体架构,创建Schema并导入数据 一.GeoMesa-整体架构 二.GeoMesa-创建Schema并导入数据 2.1 GeoTools Data 模块 2.2 索引管理 2.3 ...
- Django(自定义过滤器和自定义标签)
模版是一个用django模版语言标记过的python字符串.模版可以包含模版标签和变量. 模版标签是在一个模版里起作用的标记.比如,一个模版标签可以产生控制结构的内容(if或者for),可以获取数据库 ...
- 用到的API整理
时间 淘宝 http://api.m.taobao.com/rest/api3.do?api=mtop.common.getTimestamp 获取时间戳,调用效果 { "api" ...
- HDU-3240(卡特兰数+分解质因数后求逆元)
卡特兰数相关公式 : \(H_n = {C_{2n}^n \over n+1)}\) \(H_n = {(4n-2)\over n+1}\times H_{n-1}\) \(H_n = C_{2n}^ ...
- Codeforces Round #664 (Div. 2) D. Boboniu Chats with Du
传送门:cf1395D 题意 给定一个长度为n的数组a[i]为当天说话的有趣值,如果a[i]>m,那么在 i 之后有d天不能说话.否则可以每天都说话.找到一个排列使得n天有趣值总和最大,问有趣值 ...
- c语言实现--顺序表操作
经过三天的时间终于把顺序表的操作实现搞定了.(主要是在测试部分停留了太长时间) 1;线性表顺序存储的概念:指的是在内存中用一段地址连续的存储单元依次存储线性表中的元素. 2;采用的实现方式:一段地址连 ...
- boomworks 1999~2009
大众软件 PC定时执行专家 4.0 (PCTaskTimer) - 功能强大.简单易用的定时执行软件.具有功能多.体积小.消耗资源少的特点. 超级网际搜索(SuperSearch) - 免费.快速.高 ...
- linux内核编程入门--系统调用监控文件访问
参考的资料: hello world https://www.cnblogs.com/bitor/p/9608725.html linux内核监控模块--系统调用的截获 https://www. ...
- codeforces 1010 C. Border【exgcd】
题目链接:戳这里 学习博客:戳这里 题意:给n种数,n种数取任意个任意组合相加为sum,求sum%k有哪些值. 解题思路: 由exgcd可知(具体用到的是贝祖定理),ax + by = c,满足gcd ...