阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。
而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
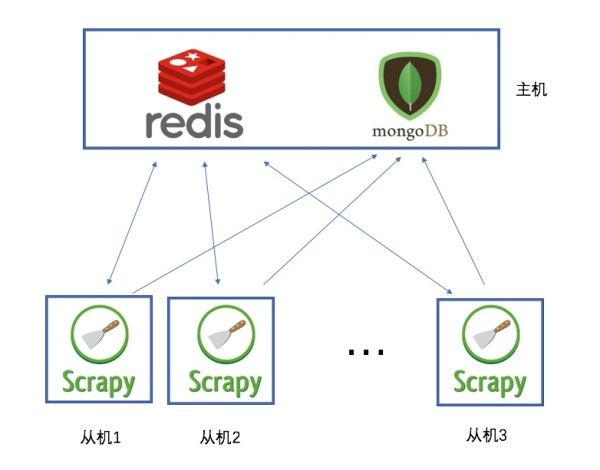
说白了,就是使用redis来维护一个url队列,然后scrapy爬虫都连接这一个redis获取url,且当爬虫在redis处拿走了一个url后,redis会将这个url从队列中清除,保证不会被2个爬虫拿到同一个url,即使可能2个爬虫同时请求拿到同一个url,在返回结果的时候redis还会再做一次去重处理,所以这样就能达到分布式效果,我们拿一台主机做redis 队列,然后在其他主机上运行爬虫.且scrapy-redis会一直保持与redis的连接,所以即使当redis 队列中没有了url,爬虫会定时刷新请求,一旦当队列中有新的url后,爬虫就立即开始继续爬
首先分别在主机和从机上安装需要的爬虫库
pip3 install requests scrapy scrapy-redis redis
在主机中安装redis
#安装redis
yum install redis 启动服务
systemctl start redis 查看版本号
redis-cli --version 设置开机启动
systemctl enable redis.service
修改redis配置文件 vim /etc/redis.conf 将保护模式设为no,同时注释掉bind,为了可以远程访问,另外需要注意阿里云安全策略也需要暴露6379端口
改完配置后,别忘了重启服务才能生效
systemctl restart redis
然后分别新建爬虫项目
scrapy startproject myspider
在项目的spiders目录下新建test.py
#导包
import scrapy
import os
from scrapy_redis.spiders import RedisSpider #定义抓取类
#class Test(scrapy.Spider):
class Test(RedisSpider): #定义爬虫名称,和命令行运行时的名称吻合
name = "test" #定义redis的key
redis_key = 'test:start_urls' #定义头部信息
haders = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.86 Chrome/73.0.3683.86 Safari/537.36'
} def parse(self, response):
print(response.url)
pass
然后修改配置文件settings.py,增加下面的配置,其中redis地址就是在主机中配置好的redis地址:
BOT_NAME = 'myspider' SPIDER_MODULES = ['myspider.spiders']
NEWSPIDER_MODULE = 'myspider.spiders' #设置中文编码
FEED_EXPORT_ENCODING = 'utf-8' # scrapy-redis 主机地址
REDIS_URL = 'redis://root@39.106.228.179:6379'
#队列调度
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#不清除缓存
SCHEDULER_PERSIST = True
#通过redis去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#不遵循robots
ROBOTSTXT_OBEY = False
最后,可以在两台主机上分别启动scrapy服务
scrapy crawl test
此时,服务已经起来了,只不过redis队列中没有任务,在等待状态
进入主机的redis
redis-cli
将任务队列push进redis
lpush test:start_urls http://baidu.com
lpush test:start_urls http://chouti.com
可以看到,两台服务器的爬虫服务分别领取了队列中的任务进行抓取,同时利用redis的特性,url不会重复抓取
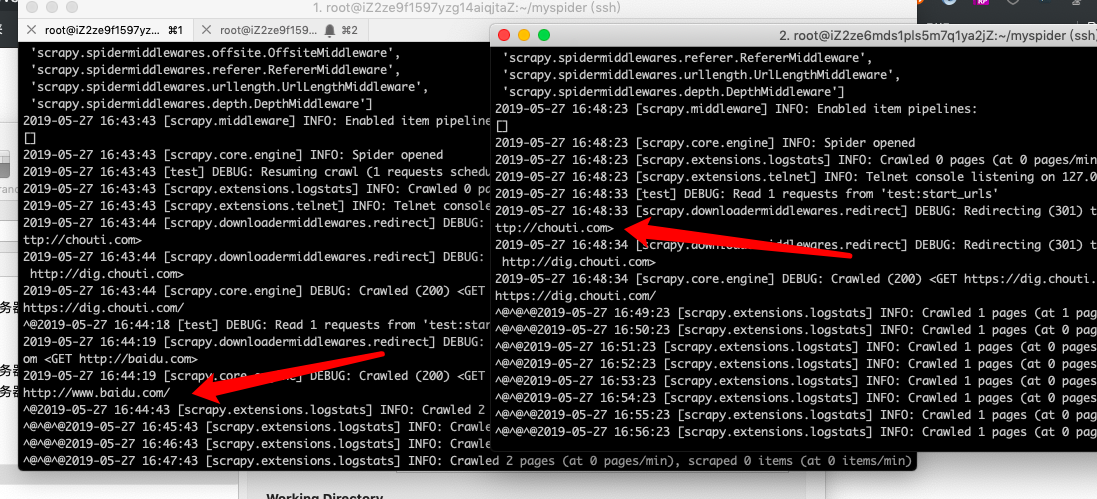
爬取任务结束之后,可以通过flushdb命令来清除地址指纹,这样就可以再次抓取历史地址了。
阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis的更多相关文章
- 在阿里云Centos7.6上面部署基于Redis的分布式爬虫Scrapy-Redis
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_83 Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的 ...
- 在阿里云Centos7.6中部署nginx1.16+uwsgi2.0.18+Django2.0.4
上次在网上找了一个在阿里云Centos7.6中部署nginx1.16+uwsgi2.0.18+Django2.0.4的文档,可能是这个文档不是最新版的,安装的时候遇到了很多问题, 最后跟一个大神要了一 ...
- 阿里云Centos7.6中部署nginx1.16+uwsgi2.0.18+Django2.0.4
当你购买了阿里云的ecs,涉及ecs的有两个密码,一定要搞清楚,一个密码是远程链接密码,也就是通过浏览器连接服务器的密码,另外一个是实例密码,这个密码就是ecs的root密码,一般情况下,我们经常用到 ...
- 【Docker】 使用Docker 在阿里云 Centos7 部署 MySQL 和 Redis (二)
系列目录: [Docker] CentOS7 安装 Docker 及其使用方法 ( 一 ) [Docker] 使用Docker 在阿里云 Centos7 部署 MySQL 和 Redis (二) [D ...
- 新手之首次部署阿里云centos7+mysql+asp.net mvc core应用之需要注意的地方
先来几个字,坑坑坑. 自己业余爱好者,签名一直捣鼓net+mssql,前阵买了阿里云esc,自己尝试做个博客,大体架子都打好了,本地安装了mysql,测试了也没问题. 部署到阿里云centos7,结果 ...
- 阿里云CentOS7部署ASP.NET Core
本文主要介绍了阿里云CentOS7下如何成功的发布ASP.Core应用并使用nginx进行代理, 并对所踩的坑加以记录; 环境.工具.准备工作 服务器:阿里云64位CentOS 7.4.1708版本; ...
- 阿里云服务器安装Docker并部署nginx、jdk、redis、mysql
阿里云服务器安装Docker并部署nginx.jdk.redis.mysql 一.安装Docker 1.安装Docker的依赖库 yum install -y yum-utils device-map ...
- 阿里云CentOS7部署MySql8.0
本文主要介绍了阿里云CentOS7如何安装MySql8.0,并对所踩的坑加以记录; 环境.工具.准备工作 服务器:阿里云CentOS 7.4.1708版本; 客户端:Windows 10; SFTP客 ...
- 阿里云CentOS7.3服务器通过Docker安装Nginx
前言 小编环境: 阿里云CentOS7.3服务器 docker 下面分享一次小编在自己的阿里云CentOS7.3服务器上使用Docker来安装Nginx的一次全过程 温馨小提示: 如果只是希望单纯使用 ...
随机推荐
- zabbix 监控文件夹
安装inotify wget http://github.com/downloads/rvoicilas/inotify-tools/inotify-tools-3.14.tar.gz tar -zx ...
- 【初等数论】费马小定理&欧拉定理&扩展欧拉定理(暂不含证明)
(不会证明--以后再说) 费马小定理 对于任意\(a,p \in N_+\),有 \(a^{p-1} \equiv 1\pmod {p}\) 推论: \(a^{-1} \equiv a^{p-2} \ ...
- 蓝桥杯——分组比赛(2017JavaB组第3题)
分组比赛(17JavaB3) 9名运动员参加比赛,需要分3组进行预赛. 有哪些分组的方案呢? 标记运动员为 A,B,C,... I 下面的程序列出了所有的分组方法: ABC DEF GHI ABC D ...
- Java基础教程——Random随机数类
Random类 java.util.Random类用于产生随机数.需要导入包: import java.util.Random; 方法 解释 Random() 创建一个Random类对象 Random ...
- ModelViewSet + ModelSerializer
ModelSerializer (封装好的序列化器,不需要我们写字段) from rest_framework import serializers from .models import * cl ...
- Android开发环境及Hello World程序
Android的开发需要以下四个工具: 1. JDK 2. Eclipse 3. Android SDK 4. ADT 具体功能: 1. JDK.JDK即Java Development Kit(Ja ...
- Alpha冲刺-第五次冲刺笔记
Alpha冲刺-冲刺笔记 这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzzcxy/2018SE2 这个作业要求在哪里 https://edu.cnblogs. ...
- Bootstrap Blazor 组件介绍 Table (三)列数据格式功能介绍
Bootstrap Blazor 是一套企业级 UI 组件库,适配移动端支持各种主流浏览器,已经在多个交付项目中使用.通过本套组件可以大大缩短开发周期,节约开发成本.目前已经开发.封装了 70 多个组 ...
- 自动化运维工具之Puppet变量、正则表达式、流程控制、类和模板
前文我们了解了puppet的file.exec.cron.notify这四种核心资源类型的使用以及资源见定义通知/订阅关系,回顾请参考https://www.cnblogs.com/qiuhom-18 ...
- 从代码角度理解NNLM(A Neural Probabilistic Language Model)
其框架结构如下所示: 可分为四 个部分: 词嵌入部分 输入 隐含层 输出层 我们要明确任务是通过一个文本序列(分词后的序列)去预测下一个字出现的概率,tensorflow代码如下: 参考:https: ...