Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类)
运行环境
- Pyhton3
- numpy(科学计算包)
- matplotlib(画图所需,不画图可不必)
计算过程
st=>start: 开始
e=>end: 结束
op1=>operation: 读入数据
op2=>operation: 随机初始化聚类中心
cond=>condition: 是否聚类是否变化
op3=>operation: 寻找最近的点加入聚类
op4=>operation: 更新聚类中心
op5=>operation: 输出结果
st->op1->op2->op3->op4->cond
cond(yes)->op3
cond(no)->op5->e
输入样例
/* 788points.txt */
15.55,28.65
14.9,27.55
14.45,28.35
14.15,28.8
13.75,28.05
13.35,28.45
13,29.15
13.45,27.5
13.6,26.5
12.8,27.35
12.4,27.85
12.3,28.4
12.2,28.65
13.4,25.1
12.95,25.95
788points.txt完整文件:下载
代码实现
# -*- coding: utf-8 -*-
__author__ = 'Wsine'
from numpy import *
import matplotlib.pyplot as plt
import operator
import time
INF = 9999999.0
def loadDataSet(fileName, splitChar='\t'):
"""
输入:文件名
输出:数据集
描述:从文件读入数据集
"""
dataSet = []
with open(fileName) as fr:
for line in fr.readlines():
curline = line.strip().split(splitChar)
fltline = list(map(float, curline))
dataSet.append(fltline)
return dataSet
def createDataSet():
"""
输出:数据集
描述:生成数据集
"""
dataSet = [[0.0, 2.0],
[0.0, 0.0],
[1.5, 0.0],
[5.0, 0.0],
[5.0, 2.0]]
return dataSet
def distEclud(vecA, vecB):
"""
输入:向量A, 向量B
输出:两个向量的欧式距离
"""
return sqrt(sum(power(vecA - vecB, 2)))
def randCent(dataSet, k):
"""
输入:数据集, 聚类个数
输出:k个随机质心的矩阵
"""
n = shape(dataSet)[1]
centroids = mat(zeros((k, n)))
for j in range(n):
minJ = min(dataSet[:, j])
rangeJ = float(max(dataSet[:, j]) - minJ)
centroids[:, j] = minJ + rangeJ * random.rand(k, 1)
return centroids
def kMeans(dataSet, k, distMeans=distEclud, createCent=randCent):
"""
输入:数据集, 聚类个数, 距离计算函数, 生成随机质心函数
输出:质心矩阵, 簇分配和距离矩阵
"""
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m, 2)))
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m): # 寻找最近的质心
minDist = INF
minIndex = -1
for j in range(k):
distJI = distMeans(centroids[j, :], dataSet[i, :])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist**2
for cent in range(k): # 更新质心的位置
ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A == cent)[0]]
centroids[cent, :] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
def plotFeature(dataSet, centroids, clusterAssment):
m = shape(centroids)[0]
fig = plt.figure()
scatterMarkers = ['s', 'o', '^', '8', 'p', 'd', 'v', 'h', '>', '<']
scatterColors = ['blue', 'green', 'yellow', 'purple', 'orange', 'black', 'brown']
ax = fig.add_subplot(111)
for i in range(m):
ptsInCurCluster = dataSet[nonzero(clusterAssment[:, 0].A == i)[0], :]
markerStyle = scatterMarkers[i % len(scatterMarkers)]
colorSytle = scatterColors[i % len(scatterColors)]
ax.scatter(ptsInCurCluster[:, 0].flatten().A[0], ptsInCurCluster[:, 1].flatten().A[0], marker=markerStyle, c=colorSytle, s=90)
ax.scatter(centroids[:, 0].flatten().A[0], centroids[:, 1].flatten().A[0], marker='+', c='red', s=300)
def main():
#dataSet = loadDataSet('testSet2.txt')
dataSet = loadDataSet('788points.txt', splitChar=',')
#dataSet = createDataSet()
dataSet = mat(dataSet)
resultCentroids, clustAssing = kMeans(dataSet, 6)
print('*******************')
print(resultCentroids)
print('*******************')
plotFeature(dataSet, resultCentroids, clustAssing)
if __name__ == '__main__':
start = time.clock()
main()
end = time.clock()
print('finish all in %s' % str(end - start))
plt.show()
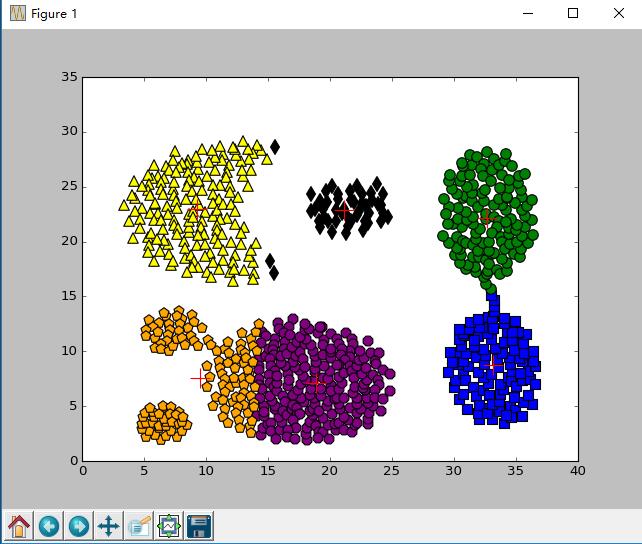
输出样例
*******************
[[ 33.14278846 8.79375 ]
[ 32.69453125 22.13789062]
[ 9.25928144 22.98113772]
[ 18.8620283 7.11037736]
[ 9.50503876 7.55620155]
[ 21.16041667 22.89895833]]
*******************
finish all in 5.454627327134057
Python实现kMeans(k均值聚类)的更多相关文章
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 第十篇:K均值聚类(KMeans)
前言 本文讲解如何使用R语言进行 KMeans 均值聚类分析,并以一个关于人口出生率死亡率的实例演示具体分析步骤. 聚类分析总体流程 1. 载入并了解数据集:2. 调用聚类函数进行聚类:3. 查看聚类 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
随机推荐
- [SSH 2] 以网站主页面浅谈Struts2配置
导读:前面总体的介绍了一下SSH框架,那么作为Struts这一支,具体是怎么配置的呢?本篇博客则主要是以自己做过的实例中的登录一条线,简单介绍一下struts2的配置,如有不妥之处,还请大家多提点提点 ...
- json 對象的序列化
var a={x:1,y:2} s=JSON.stringify(a); //s="{"x":1,"y":2}" p=JSON.parse( ...
- 开源项目:windows下使用MinGW+msys编译ffmpeg
本文参考了网络上的不少文章,但由于版本环境的问题参考文章并不能直接指导编译,本文吸收多方经验,并在自己多次编译实验的基础上写成,欢迎转载,请注名出处. FFmpeg是在Linux平台下开发的,但 ...
- python md5
import hashlib import os 简单的测试一个字符串的MD5值 src = 'teststring' print (hashlib.md5(src).hexdigest().uppe ...
- ENVI 5.0 Beta 体验——影像数据的显示
ENVI 5.0 Beta采用了全新的软件界面,数据的显示和操作跟以往的三视窗方式有很大的区别,下面一块体验一下. 对于栅格数据的显示方面,5.0有了非常大的改进,采用的全新的金字塔计算方法,在第一次 ...
- javascript 同步加载与异步加载
HTML 4.01 的script属性 charset: 可选.指定src引入代码的字符集,大多数浏览器忽略该值. defer: boolean, 可选.延迟脚本执行,相当于将script标签放入页面 ...
- 【MySQL】DNS与MHA/ZABBIX构建的高可用MySQL
MySQL实例组与DNS和MHA/ZABBIX架构示意图: DNS搭建:http://www.cnblogs.com/jiangxu67/p/4801230.html MHA分析:http://www ...
- Linux 之dhcp服务搭建
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一个局域网的网络协议 dhcp服务器端监控端口67 涉及的配置文件:/etc/dhcp/dhcpd ...
- CentOS 安裝 VMware Workstation / VMware Player
参考:http://www.vixual.net/blog/archives/650 序列号:1F04Z-6D111-7Z029-AV0Q4-3AEH8 注意说明:刚开始有很长的一系列协议信息,可以用 ...
- nginx url重写 rewrite实例
本文介绍下,在nginx中实现Url重写,学习rewrite的具体用法,有需要的朋友参考下吧. 原文地址:http://www.360doc.com/content/14/0202/20/142341 ...