MySQL高可用性分析
版权声明:本文由易固武原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/203
来源:腾云阁 https://www.qcloud.com/community
MySQL数据库是目前开源应用最大的关系型数据库,有海量的应用将数据存储在MySQL数据库中。存储数据的安全性和可靠性是生产数据库的关注重点。本文分析了目前采用较多的保障MySQL可用性方案。
MySQL Replication
MySQL Replication是MySQL官方提供的主从同步方案,用于将一个MySQL实例的数据,同步到另一个实例中。Replication为保证数据安全做了重要的保证,也是现在运用最广的MySQL容灾方案。Replication用两个或以上的实例搭建了MySQL主从复制集群,提供单点写入,多点读取的服务,实现了读的scale out。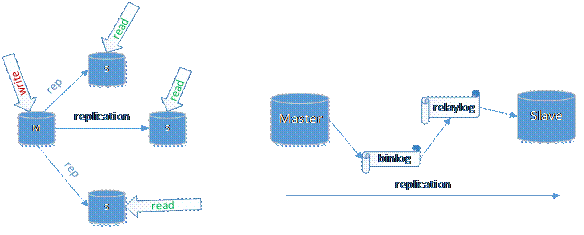
图1. MySQL Replication主从复制集群
如图一所示,一个主实例(M),三个从实例(S),通过replication,Master生成event的binlog,然后发给slave,Slave将event写入relaylog,然后将其提交到自身数据库中,实现主从数据同步。对于数据库之上的业务层来说,基于MySQL的主从复制集群,单点写入Master,在event同步到Slave后,读逻辑可以从任何一个Slave读取数据,以读写分离的方式,大大降低Master的运行负载,同时提升了Slave的资源利用。
对于高可用来说,MySQL Replication有个重要的缺陷:数据复制的时延。在通常情况下,MySQL Replication数据复制是异步的,即是MySQL写binlog后,发送给Slave并不等待Slave返回确认收到,本地事务就提交了。一旦出现网络延迟或中断,数据延迟发送到Slave侧,主从数据就会出现不一致。在这个阶段中,Master一旦宕机,未发送到Slave的数据就丢失了,无法做到数据的高可用。
为了解决这个问题,google提供了解决方案:半同步和同步复制。在数据异步复制的基础之上,做了一点修改。半同步复制是Master等待event写入Slave的relay后,再提交本地,保证Slave一定收到了需要同步的数据。同步复制不不仅是要求Slave收到数据,还要求Slave将数据commit到数据库中,从而保证每次的数据写入,主从数据都是一致的。
基于半同步和同步复制,MySQL Replication的高可用得到了质的提升,特别是同步复制。基于同步复制的MySQL Replication集群,每个实例读取的数据都是一致的,不会存在Slave幻读。同时,Master宕机后,应用程序切换到任何一个Slave都可以保证读写数据的一致性。但是,同步复制带来了重大的性能下降,这里需要做一个折衷。另外,MySQL Replication的主从切换需要人工介入判断,同时需要Slave的replaylog提交完毕,故障恢复时间会比较长。
MySQL Fabric
MySQL Fabric是MySQL社区提供的管理多个MySQL服务的扩展。高可用是它设计的主要特性之一。
Fabric将两个及以上的MySQL实例划分为一个HA Group。其中的一个是主,其余的都是从。HA Group保证访问指定HA Group的数据总是可用的。其基础的数据复制是基于MySQL Replication,然后,Fabric提供了更多的特性:
失效检测和恢复:Fabric监控HA Group中的主实例,一旦发现主实例失效,Fabric会从HA Group中剩余的从实例中选择一个,并将其提升为主实例。
读写均衡:Fabric可以自动的处理一个HA Group的读写操作,将写操作发送给主实例,而读请求在多个从实例之间做负载均衡。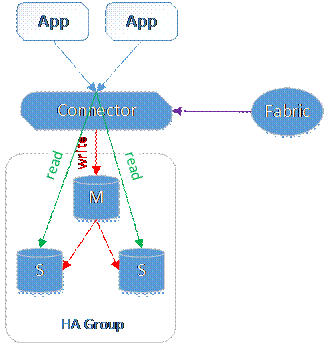
图2. Fabric
MHA
MHA(MySQL-master-ha)是目前广泛使用的MySQL主从复制的高可用方案。MHA设计目标是自动实现主实例宕机后,从机切换为主,并尽量降低切换时延(通常在10-30s内切换完成)。同时,由MHA保证在切换过程中的数据一致性。MHA对MySQL的主从复制集群非常友好,没有对集群做任何侵入性的修改。
MHA的一个重点特性是:在主实例宕机后,MHA可以自动的判断主从复制集群中哪个从实例的relaylog是最新的,并将最新从实例的差异log“应用”到其余的从实例中,从而保证每个实例的数据一致。通常情况下,MHA需要10s左右检测主实例异常,并将主实例关闭从而避免脑裂。然后再用10s左右将差异的log event同步,并启用新的Master。整个MHA的RTO时间大约在30s。
MySQL Cluster
MySQL Cluster是一个高度可扩展的,兼容ACID事务的实时数据库,基于分布式架构不存在单点故障,MySQL Cluster支持自动水平扩容,并能做自动的读写负载均衡。
MySQL Cluster使用了一个叫NDB的内存存储引擎来整合多个MySQL实例,提供一个统一的服务集群。如图三所示。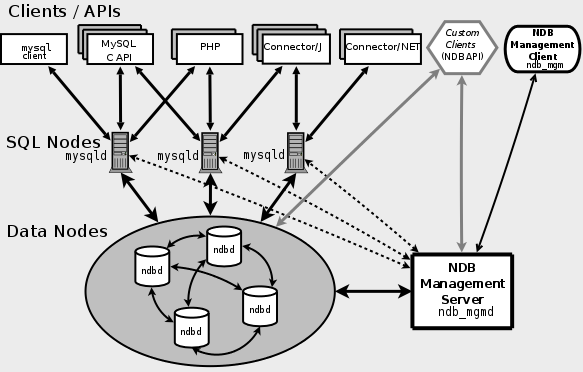
图3. MySQL Cluster组成
MySQL Cluster由SQL Nodes,DataNodes,和NDB Management Server组成。SQL Nodes是应用程序的接口,像普通的mysqld服务一样,接受用户的SQL输入,执行并返回结果。Data Nodes是数据存储节点,NDB Management Server用来管理集群中的每个node。
MySQL Cluster采用了新的数据分片和容错的方式来实现数据安全和高可用。其由Partition,Replica,Data Node,Node Group构成。
Partition:NDB一张表的一个数据分片,包含一张表的一部分数据。
Replica:一个Partition的拷贝。一个Partition可以有一个或多个Replica,一个Partition的所有Replica数据都是一致的。
Data Node:Replica的存储载体,每个Node存储一个或多个Replica。
Node Group:一个Data Node的集合。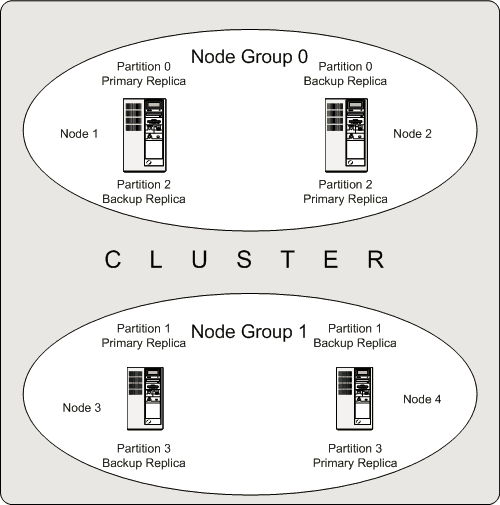
图4. MySQL Cluster数据高可用
一个MySQL Cluster有4个Node,被分为了两个Grou。Node1和2归属于Group0,Node3和4归属于Group1,。有一张表被分为4个Partition,并分别有两个Replica。Partition0和Partition2的两个Replica,分别存储在Node1和Node2上,Pratition1和Partition3的两个Replica分别存在Node3和Node4上。这样,对于一张表的一个Partition来说,在整个集群有两份数据,并分布在两个独立的Node上,实现了数据容灾。同时,每次对一个Partition的写操作,都会在两个Replica上呈现,如果Primary Replica异常,那么Backup Replica可以立即提供服务,实现数据的高可用。
小结
本文分析了目前MySQL使用较多的几种MySQL数据复制和高可用方案,从使用来看,MySQL Replication是使用最为广泛的数据复制方案,因为是MySQL原生支持,针对其在不同场景下的一些缺陷,衍生出了半同步复制,强同步复制等数据高可用的方案。在此基础之上,为了运维方便,MySQL Fabric和MHA应运而生,从不同的方向解决了主从切换时数据一致性问题和流程自动化的问题。此外,随着分布式系统架构和方案的逐步成熟。MySQL Cluster设计了全新的分布式架构,采用多副本,Sharding等特性,支持水平扩展,做到了5个9的数据库服务质量保证。
参考文献
1.http://dev.mysql.com/doc/refman/5.7/en/mysql-cluster.html
2.https://code.google.com/p/mysql-master-ha/
3.https://www.mysql.com/products/enterprise/fabric.html
MySQL高可用性分析的更多相关文章
- 【mysql】GitHub 的 MySQL 高可用性实践分享
原文出处: shlomi-noach 译文出处:oschina GitHub 使用 MySQL 作为所有非 git 仓库数据的主要存储, 它的可用性对 GitHub 的访问操作至关重要.Gi ...
- B+Tree和MySQL索引分析
首先区分两组概念: 稠密索引,稀疏索引: 聚簇索引,非聚簇索引: btree和mysql的分析: 参见 http://blog.csdn.net/hguisu/article/details/7786 ...
- MySQL性能分析及explain的使用
MySQL性能分析及explain用法的知识 1.使用explain语句去查看分析结果 如explain select * from test1 where id=1;会出现:id selectty ...
- PHP Apache Access Log 分析工具 拆分字段成CSV文件并插入Mysql数据库分析
现在需要分析访问日志,怎么办? 比如分析D:\Servers\Apache2.2\logs\access2014-05-22.log http://my.oschina.net/cart/针对这个问题 ...
- MySQL协议分析
MySQL协议分析 标签: mysql 2015-02-27 10:22 1807人阅读 评论(1) 收藏 举报 分类: 数据库(19) 目录(?)[+] 1 交互过程 MySQL客户端与 ...
- MySQL高可用性大杀器之MHA | 火丁笔记
MySQL高可用性大杀器之MHA | 火丁笔记 MySQL高可用性大杀器之MHA
- MySQL协议分析2
MySQL协议分析 议程 协议头 协议类型 网络协议相关函数 NET缓冲 VIO缓冲 MySQL API 协议头 ● 数据变成在网络里传输的数据,需要额外的在头部添加4 个字节的包头. . packe ...
- MySQL性能分析及explain的使用说明
1.使用explain语句去查看分析结果 如explain select * from test1 where id=1;会出现:id selecttype table type possible_k ...
- Mysql元数据分析
Mysql元数据分析 @(基础技术) 一.information_schema库 information_schema库中的表,保存的是Mysql的元数据. 官网元数据表介绍 InnoDB相关的表介绍 ...
随机推荐
- SpringMVC +mybatis+spring 结合easyui用法及常见问题总结
SpringMVC +mybatis+spring 结合easyui用法及常见问题总结 1.FormatString的用法. 2.用postAjaxFillGrid实现dataGrid 把form表单 ...
- libevent系列之一——libevent介绍
摘自:http://libevent.org/ libevent概述:一套事件通知库. libevent提供一套机制完成以下功能:当指定的事件发生在file descriptor时或者超时后执行一个回 ...
- redis基本数据类型及方法
redis支持的数据类型 String redis最基本的类型,可以是任意类型的字符串,也可以是数字 SET 赋值,用法: SET key value GET 取值,用法: GET key INCR ...
- UIView如何管理它的子视图
UIView提供了很多建立和管理视图的方法. 1.添加视图 insertSubview:atIndex: //放在子视图数组的具体索引位置 insertSubview:aboveSubview: ...
- 一次Linux系统被攻击的分析过程
IT行业发展到现在,安全问题已经变得至关重要,从最近的“棱镜门”事件中,折射出了很多安全问题,信息安全问题已变得刻不容缓,而做为运维人员,就必须了解一些安全运维准则,同时,要保护自己所负责的业务,首先 ...
- 【leetcode❤python】237. Delete Node in a Linked List
#-*- coding: UTF-8 -*- # Definition for singly-linked list.# class ListNode(object):# def __init ...
- CodeForces 451C Predict Outcome of the Game
Predict Outcome of the Game Time Limit:2000MS Memory Limit:262144KB 64bit IO Format:%I64d &a ...
- 【转载】Ogre的内存分配策略
原文:Ogre的内存分配策略 读这个之前,强烈建议看一下Alexandrescu的modern c++的第一章关于policy技术的解释.应该是这哥们发明的,这里只是使用. 首先列出涉及到的头文件:( ...
- SpringMVC 服务器端验证
1.导入JSR303验证类库Jar包2.在MVC的配置文件中添加<mvc:annotation-driven/>的配置3.在MVC的配置文件中添加验证器的配置4.在接收表单数据的类中添加验 ...
- 06_在web项目中集成Spring
在web项目中集成Spring 一.使用Servlet进行集成测试 1.直接在Servlet 加载Spring 配置文件 ApplicationContext applicationContext = ...