...python の 学习
5.14
...上次学python 好像是一个月前..
写点东西记录下叭..
现在在看李老大写的博客写..可能直接开抄代码...
感觉自己写的总是爬不成功,之前写的爬豆瓣影评的爬虫还是残的...
1.最简单的爬取一个网页
import urllib2
html = urllib2.urlopen('http://music.163.com/')
print html.read()
2.把爬取到的网页存起来
可是好像因为之前用了那个网页映射工具,现在生成 的 html 里面是当前目录下的东西,而不是自己爬的那个网页里面的内容...sigh..
import urllib2
response = urllib2.urlopen('http://music.163.com/')
html = response.read()
open('testt.html',"w").write(html)
3.爬取ZOL 的一张壁纸
import urllib2
import re # 正则表达式所用到的库 # 我们所要下载的图片所在网址
url = 'http://desk.zol.com.cn/bizhi/6377_78500_2.html'
response = urllib2.urlopen(url)
# 获取网页内容
html = response.read() # 确定一个正则表达式,用来找到图片的所在地址
reg = re.compile(r'<img id="bigImg" src="(.*?jpg)" .*>');
imgurl = reg.findall(html)[] # 打开图片并保存为haha.jpg
imgsrc = urllib2.urlopen(imgurl).read()
open("haha.jpg","w").write(imgsrc)
是直接抄的老大的代码
然而我爬出来的壁纸是这样的

不懂啊
解决了......
http://m.ithao123.cn/content-6589593.html
应该用 "wb" 去打开文件
import urllib2
import re url = 'http://desk.zol.com.cn/bizhi/6377_78500_2.html'
response = urllib2.urlopen(url) html = response.read() reg = re.compile(r'<img id="bigImg" src="(.*?jpg)" .*>');
imgurl = reg.findall(html)[] imgsrc = urllib2.urlopen(imgurl).read()
open("haha.jpg","wb").write(imgsrc)
然后
可以看到壁纸了,感人!!!

5.15
今天试了下李老大爬ZOL 壁纸 的代码,爬出来的文件夹里面是空的啊...而且文件名是乱码..
不过李老大说了那个只适用于linux
于是开始看 崔庆才 教程
1.爬取贴吧帖子
效果图
然后在抄代码的过程中遇到三个问题
1) print 中文的时候会报错
一种解决方案是 这个
#!/usr/bin/python
#coding:utf-
2)然后在改了上面那个问题后
会报错,像下面这样
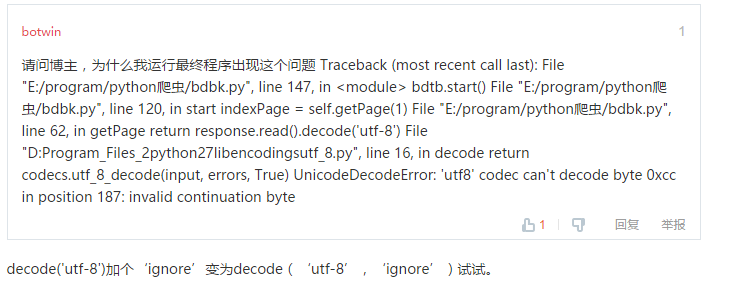
解决办法就是图里面说的这样
3.最后一个问题 就是 贴吧改版了
要换成
<h3 class="core_title_txt".*?>(.*?)</h3> 最后代码是这样的
#!/usr/bin/python
#coding:utf-
__author__ = 'CQC'
# -*- coding:utf- -*- import urllib
import urllib2
import re class Tool: removeImg = re.compile('<img.*?>| {7}|') removeAddr = re.compile('<a.*?>|</a>') replaceLine = re.compile('<tr>|<div>|</div>|</p>') replaceTD= re.compile('<td>') replacePara = re.compile('<p.*?>') replaceBR = re.compile('<br><br>|<br>') removeExtraTag = re.compile('<.*?>')
def replace(self,x):
x = re.sub(self.removeImg,"",x)
x = re.sub(self.removeAddr,"",x)
x = re.sub(self.replaceLine,"\n",x)
x = re.sub(self.replaceTD,"\t",x)
x = re.sub(self.replacePara,"\n ",x)
x = re.sub(self.replaceBR,"\n",x)
x = re.sub(self.removeExtraTag,"",x) return x.strip() class BDTB: def __init__(self,baseUrl,seeLZ,floorTag): self.baseURL = baseUrl self.seeLZ = '?see_lz='+str(seeLZ) self.tool = Tool() self.file = None self.floor = self.defaultTitle = u"百度贴吧" self.floorTag = floorTag def getPage(self,pageNum):
try: url = self.baseURL+ self.seeLZ + '&pn=' + str(pageNum)
request = urllib2.Request(url)
response = urllib2.urlopen(request) return response.read().decode('utf-8','ignore') except urllib2.URLError, e:
if hasattr(e,"reason"):
print u"连接百度贴吧失败,错误原因",e.reason
return None def getTitle(self,page): pattern = re.compile('<h3 class=core_title_txt.*?>(.*?)</h3>',re.S)
result = re.search(pattern,page)
if result: return result.group().strip()
else:
return None def getPageNum(self,page): pattern = re.compile('<li class="l_reply_num.*?</span>.*?<span.*?>(.*?)</span>',re.S)
result = re.search(pattern,page)
if result:
return result.group().strip()
else:
return None def getContent(self,page): pattern = re.compile('<div id="post_content_.*?>(.*?)</div>',re.S)
items = re.findall(pattern,page)
contents = []
for item in items: content = "\n"+self.tool.replace(item)+"\n"
contents.append(content.encode('utf-8'))
return contents def setFileTitle(self,title): if title is not None:
self.file = open(title + ".txt","w+")
else:
self.file = open(self.defaultTitle + ".txt","w+") def writeData(self,contents): for item in contents:
if self.floorTag == '': floorLine = "\n" + str(self.floor) + u"-----------------------------------------------------------------------------------------\n"
self.file.write(floorLine)
self.file.write(item)
self.floor += def start(self):
indexPage = self.getPage()
pageNum = self.getPageNum(indexPage)
title = self.getTitle(indexPage)
self.setFileTitle(title)
if pageNum == None:
print "URL已失效,请重试"
return
try:
print "该帖子共有" + str(pageNum) + "页"
for i in range(,int(pageNum)+):
print "正在写入第" + str(i) + "页数据"
page = self.getPage(i)
contents = self.getContent(page)
self.writeData(contents) except IOError,e:
print "写入异常,原因" + e.message
finally:
print "写入任务完成" print u"请输入帖子代号"
baseURL = 'http://tieba.baidu.com/p/' + str(raw_input(u'http://tieba.baidu.com/p/'))
seeLZ = raw_input("是否只获取楼主发言,是输入1,否输入0\n")
floorTag = raw_input("是否写入楼层信息,是输入1,否输入0\n")
bdtb = BDTB(baseURL,seeLZ,floorTag)
bdtb.start()
还不懂原理,再看
5.18
爬取贴吧内容的 一个类
#!/usr/bin/python
#coding:utf-
import urllib
import urllib2
import re class bdtb:
def __init__(self,baseurl,seelz):
self.baseurl = baseurl
self.seelz = '?see_lz='+str(seelz) def getPage(self,pagenum):
try:
url = self.baseurl + self.seelz + '&pn=' + str(pagenum)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
return response
except urllib2.URLError,e:
if hasattr(e,"reason"):
print u"连接百度贴吧失败,错误原因",e.reason
return None baseurl = 'http://tieba.baidu.com/p/3138733512'
bb = bdtb(baseurl,)
bb.getPage()
5.19
模拟登陆学校的信息门户
要用 ie 才能够看到成绩,但是看不到表单,就是 form data
这个时候再用回搜狗
#coding=utf- import urllib
import urllib2
import cookielib
import re class CHD: def __init__(self):
self.loginUrl = 'http://bksjw.chd.edu.cn/loginAction.do'
self.cookies = cookielib.CookieJar()
self.postdata = urllib.urlencode({
'dllx':dldl
'zjh':xxxx
'mm':xxxx
})
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookies)) def getPage(self):
request = urllib2.Request(
url = self.loginUrl,
data = self.postdata)
result = self.opener.open(request) print result.read().decode('gbk') chd = CHD()
chd.getPage()
...python の 学习的更多相关文章
- Python学习--04条件控制与循环结构
Python学习--04条件控制与循环结构 条件控制 在Python程序中,用if语句实现条件控制. 语法格式: if <条件判断1>: <执行1> elif <条件判断 ...
- Python学习--01入门
Python学习--01入门 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.和PHP一样,它是后端开发语言. 如果有C语言.PHP语言.JAVA语言等其中一种语言的基础,学习Py ...
- Python 学习小结
python 学习小结 python 简明教程 1.python 文件 #!/etc/bin/python #coding=utf-8 2.main()函数 if __name__ == '__mai ...
- Python学习路径及练手项目合集
Python学习路径及练手项目合集 https://zhuanlan.zhihu.com/p/23561159
- python学习笔记-python程序运行
小白初学python,写下自己的一些想法.大神请忽略. 安装python编辑器,并配置环境(见http://www.cnblogs.com/lynn-li/p/5885001.html中 python ...
- Python学习记录day6
title: Python学习记录day6 tags: python author: Chinge Yang date: 2016-12-03 --- Python学习记录day6 @(学习)[pyt ...
- Python学习记录day5
title: Python学习记录day5 tags: python author: Chinge Yang date: 2016-11-26 --- 1.多层装饰器 多层装饰器的原理是,装饰器装饰函 ...
- [Python] 学习资料汇总
Python是一种面向对象的解释性的计算机程序设计语言,也是一种功能强大且完善的通用型语言,已经有十多年的发展历史,成熟且稳定.Python 具有脚本语言中最丰富和强大的类库,足以支持绝大多数日常应用 ...
- Python学习之路【目录】
本系列博文包含 Python基础.前端开发.Web框架.缓存以及队列等,希望可以给正在学习编程的童鞋提供一点帮助!!! 目录: Python学习[第一篇]python简介 Python学习[第二篇]p ...
- python学习笔记系列----(八)python常用的标准库
终于学到了python手册的最后一部分:常用标准库.这部分内容主要就是介绍了一些基础的常用的基础库,可以大概了解下,在以后真正使用的时候也能想起来再拿出来用. 8.1 操作系统接口模块:OS OS模块 ...
随机推荐
- SQL HAVING语句
HAVING 子句 在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用. SQL HAVING 语法 SELECT column_name, aggregate_f ...
- javaMail编写案列
package common.impl; import java.util.Properties; import javax.mail.BodyPart; import javax.mail.Mess ...
- (二)miller指导查看主控板寄存器操作
Welcome to Command Shell!Username:admin Password:***** ROS>en ROS# ROS# ROS# ROS# ROS#^ada ROS(ad ...
- poj2975(nim游戏取法)
求处于必胜状态有多少种走法. if( (g[i]^ans) <= g[i]) num++; //这步判断很巧妙 // // main.cpp // poj2975 // // Created b ...
- SDL1.2到2.0的迁移指南(转)
里面有些单词不好翻译所以放在开头,以备查验. BLock Image Transfer, a computer graphics operation in which two bitmap patte ...
- Spring3 表达式语言(SpEL)介绍
转载自:http://iyiguo.net/blog/2011/06/19/spring-expression-language/ 下一版本 项目需要使用到SpEL ,做一个保存.
- hiho_1081_最短路径1
题目 最短路模板题目,纯练习手速. 实现 #include<iostream> #include<string.h> #include<iostream> #inc ...
- 深入理解JVM-3垃圾收集器与内存分配策略
在上面一篇文章中,介绍了java内存运行时区域,其中程序计数器.虚拟机栈.本地方法栈3个区域随线程生灭:栈中的栈帧随着方法的进入和退出而有条不紊的执行着进栈出栈的操作,每一个栈帧中分配着多少内存基本上 ...
- java中的异常和处理
算术异常类:ArithmeticExecption 空指针异常类:NullPointerException 类型强制转换异常:ClassCastException 数组负下标异常:NegativeAr ...
- 关于64位WIN7下正确建立JAVA开发环境(转
1.下载并安装JDK(地址:http://www.oracle.com/technetwor ... ownload-400750.html 先在“Accept License Agreeme ...