SQL Server 索引 之 书签查找 <第十一篇>
一、书签查找的概念
书签可以帮助SQL Server快速从非聚集索引条目导向到对应的行,其实这东西几句话我就能说明白。
如果表有聚集索引(区段结构),那么书签就是从非聚集索引找到聚集索引后,利用聚集索引定位到数据。此处的书签就是聚集索引。如果表没有聚集索引(堆结构)。那么扫描非聚集索引后,通过RID定位到数据,那么此处书签就是RID。
所谓的书签查找,就是通过聚集索引,然后利用聚集索引或RID定位到数据。
不论表示堆结构还是区段结构,数据的存放都是数据库文件的某文件->某页->某行,因此定位数据的文件组合起来就是
文件号:页号:行号。这三个数字就是RID。如文件1的第77页的第12行的RID就是1:77:12。
堆结构与区段结构不同,通常堆上的行不会改变位置,一旦他们被插入某个页中,他们就会一直在那个位置。在堆上的行很少移动,如果行被移动的话,他们会在原来的位置留下指向其移动到的新位置的指针。而区段结构的行,是可以移动的,在添加数据或整理索引时,都可以会被移动位置。
因为在堆上的行很少移动,所以RID就可以唯一标识某一行,RID的值不仅仅不变,RID所表示的行的物理位置也不会变,这使得RID的值更适宜作为书签。这也是为什么SQL Server在堆上建立的非聚集索引的书签都使用RID。
1、堆上的非聚集索引:基于RID的书签
CREATE NONCLUSTERED INDEX FK_ProductID_ModifiedDate --主键不是聚集索引,没有聚集索引
ON
Sales.SalesOrderDetail(ProductID, ModifiedDate)
INCLUDE (OrderQty,
UnitPrice, LineTotal)
部分数据顺序:

注意到以上数据是无序的。
上面建立的非聚集索引因为使用了RID作为书签,直接指向对应行所在的物理位置,因此效率不错。虽然RID值用于键查找非常高效,但书签中包含的值与具体的用户数据无关。
2、在聚集索引上的非聚集索引:基于聚集键的书签
如果表示基于聚集索引的,则表内数据可以在表移动。因此,对于聚集索引来说,RID并不能一直不变的定位一个相同的行。因此必须用另外的方法定位行,这个方法就是使用聚集索引的索引键。
使用聚集索引键作为书签可以使得当数据在页中的行改变时,不需要非聚集索引的书签的值进行变动,因此非聚集索引的键就可以用于去找底层表的数据,即根据书签取数据不再基于物理位置,而是基于聚集索引查找。

以聚集索引键作为非聚集索引的书签最好要聚集索引键满足如下标准:
索引应该具有唯一性:每一个索引条目书签都应该使得书签可以通过聚集索引的键值唯一的确认表中的一行,如果你创建的聚集索引键值不唯一,SQL Server将会为有重复键值的每一行自动加上一个叫uniquifier的东西使得每一行唯一。这个uniquifier对客户端是透明的。对于是否可以允许聚集索引键重复,要考虑以下两点:
- 生成uniquifier增加SQL Server插入操作的额外负担,在插入时SQL Server还需要判断插入的值在表中是否唯一,如果不唯一生成uniquifier值再进行插入。
- uniquifier本身对业务数据来说是没有意义的,但是这个uniquifier本身不仅仅需要占用聚集索引键的空间,还同时占用非聚集索引书签的空间
索引键应该短:索引键所占的字节数应该短.因为这个键还会占用非聚集索引书签的空间。比如Contact表中以Last name / first name / middle name / street组合作为索引键看上去不错,但如果表中存在多个非聚集索引的话情况就有些微妙了。n个非聚集索引使得Last name / first name / middle name / street这些字段被存储在n+1个位置。
索引键最好不要变动:也就是索引键的值最好不要变动。对于聚集索引键的修改会使得基于这个聚集索引的所有非聚集索引同样进行修改。所以对于聚集索引的一次update会造成n个非聚集索引书签的update+1个聚集索引键值本身的update。
下面以一个示例来帮助理解书签查找:
假设数据库有一张表如下:

我们再Name列建一个非聚集索引,然后执行下面的语句:

从执行计划我们可以看到,因为Age列并不在非聚集索引中,所以SQL Server通过“键查找”引导到聚集表获取数据,这就是书签查找。
书签查找的目的,就是为了从非聚集索引导航到基本表获取非聚集索引中并未包含的信息。
二、书签查找的缺点
书签查找要求访问索引页面之外的数据页面,访问两组页面增加了查询逻辑读操作次数。而且,如果页面不在内存中,书签查找可能需要在磁盘上一个随机I/O操作来从索引页面跳转到数据页面,还需要必要的CPU能力来汇集这一数据并执行必要的操作。这是因为对于大的表,索引页面和对应的数据页面通常在磁盘上并不临近。
如果需要增加逻辑读操作或者开销较大的物理读操作使书签查找的数据检索操作开销相当大,这个开销因素是非聚集索引更适合于返回较小的数据行数的原因。随着查询检索的行数增加,书签查找的开销将变得无法接受。
为了理解书签查找随着检索行数增加而使feu聚集索引无效,下面来看一个实例:
还是那张Person表,一万数据。这次,我把索引建在Id列,Id列的唯一性是1,因为原来Id列是做主键+聚集索引的,但被我删掉了。
我们来看看下面两个查询的执行计划,
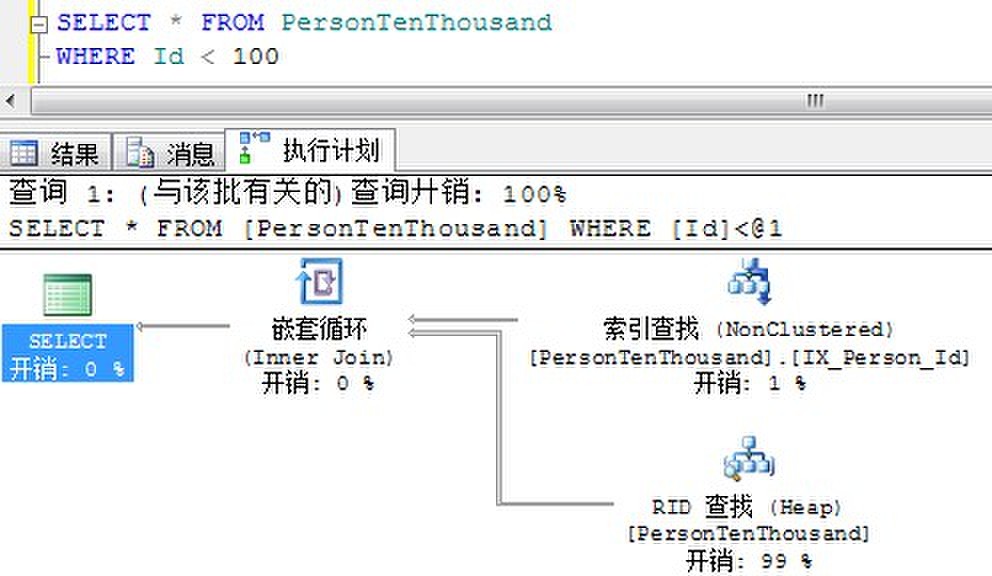
返回100条:
返回300条:
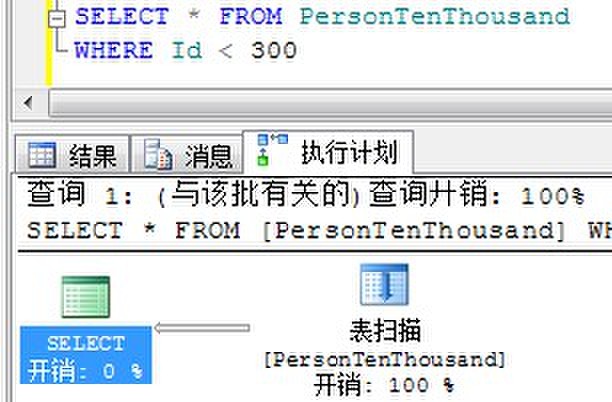
我们看到,当要求返回300条数据的时候,SQL Server就不在使用Id列上的非聚集索引,而是直接进行表扫描了。因为SQL Server认为执行300次书签查找还不如直接对一张1万条记录的表进行全表扫描。
由上面的实例可以得出结论,返回大的结果集将增加书签查找的开销,甚至低于表扫描。因此在返回较大结果集的情况下,必须考虑避免书签查找的可能性。
三、书签查找的起因
书签查找可能是一个开销较大的操作,所以应该分析查询计划,在执行计划中选择一个关键字查找步骤的原因。可能发现可以通过在非聚集索引键中包含丢失的行,或者作为索引页面级别上的包含列来避免书签查找,从而避免与书签查找相关的开销。
从上面的实例,我们可以提出观点:如果查询的各部分(不只是选择列表)中引用的列不都包含在使用的非聚集索引中,就会发生书签查找操作。
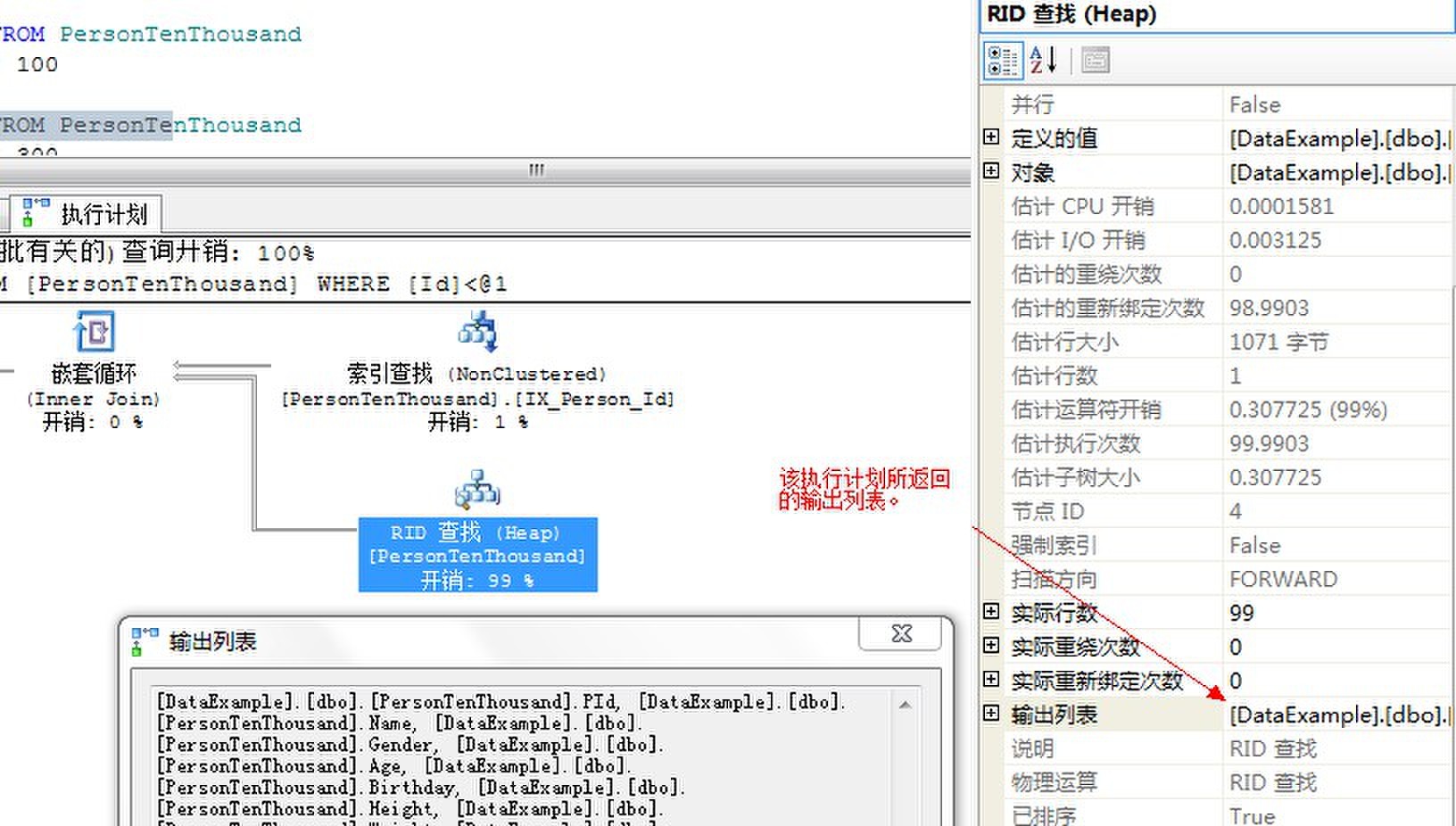
下面介绍一个技巧,我们点击某一个执行计划的图标之后,就能在右侧的属性信息栏里获取到相关的执行信息。例如,输出列表就是本执行计划的要返回的列。
四、避免书签查找的方法
因为书签查找的相对开销可能非常高,所以应该尽可能尝试摆脱书签查找操作。下面给出一下方案。
1、使用聚集索引
对于聚集索引,索引的叶子页面和表的数据页面相同。因此,当读取聚集索引键列的值时,数据引擎可以读取其他列的值而不需要任何导航。例如前面的区间数据查询的操作,SQL Server通过B树结构进行查找是非常快速的。
把非聚集索引转换为一个聚集索引说起来很简单。但是,这个例子和大部分可能遇到的情况下,这不可能做到,因为表已经有了一个聚集索引。这个表的聚集索引恰好是主键。必须卸载掉所有的外键约束,卸载并且重建为一个非聚集索引。这不仅要考虑所涉及的工作,还可能严重地影响依赖于现有聚集索引的其他查询。
2、使用覆盖索引
为了理解覆盖索引是如何避免书签查找,我们还是对于Person来执行如下两个查询:
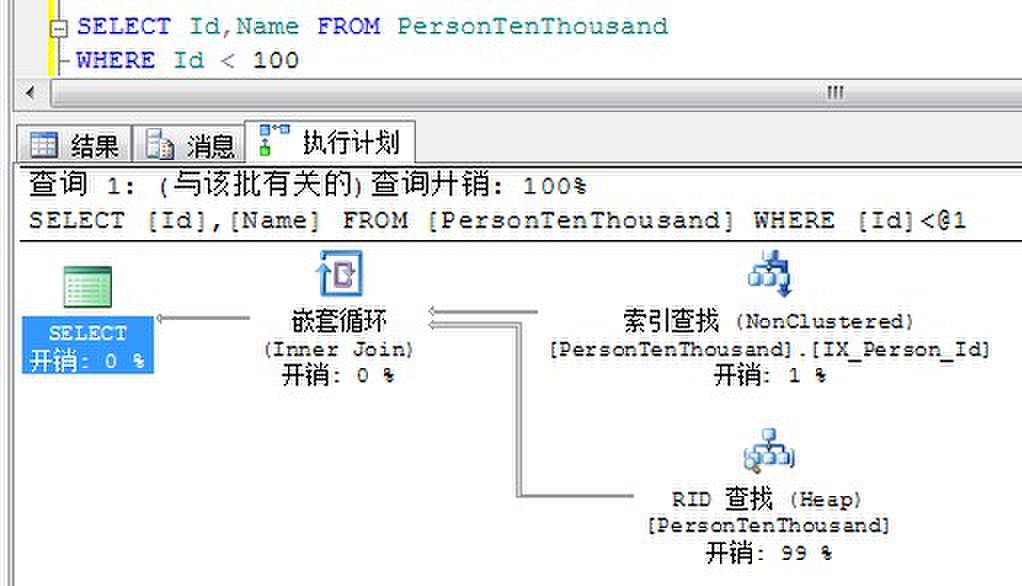
下面修改索引增加Name列。

由于非聚集索引上已经有了需要查询的Id和Name列的数据,所以不在需要书签查找定位到基本表。
3、使用索引连接
如果覆盖索引变得非常宽,那么可能要考虑索引连接技术。索引连接技术使用两个或更多索引之间的一个索引交叉来完全覆盖一个查询。因为索引连接技术需要访问多余一个索引,它必须在所有索引连接中使用的索引上执行逻辑读。因此,索引连接需要比覆盖索引更高的逻辑读数量。但是,因为索引连接所用的多个窄索引能够比宽的覆盖索引服务更多的查询。所以索引连接也可以作为避免书签查找的一种技术来考虑。
我们来看下面的实例:
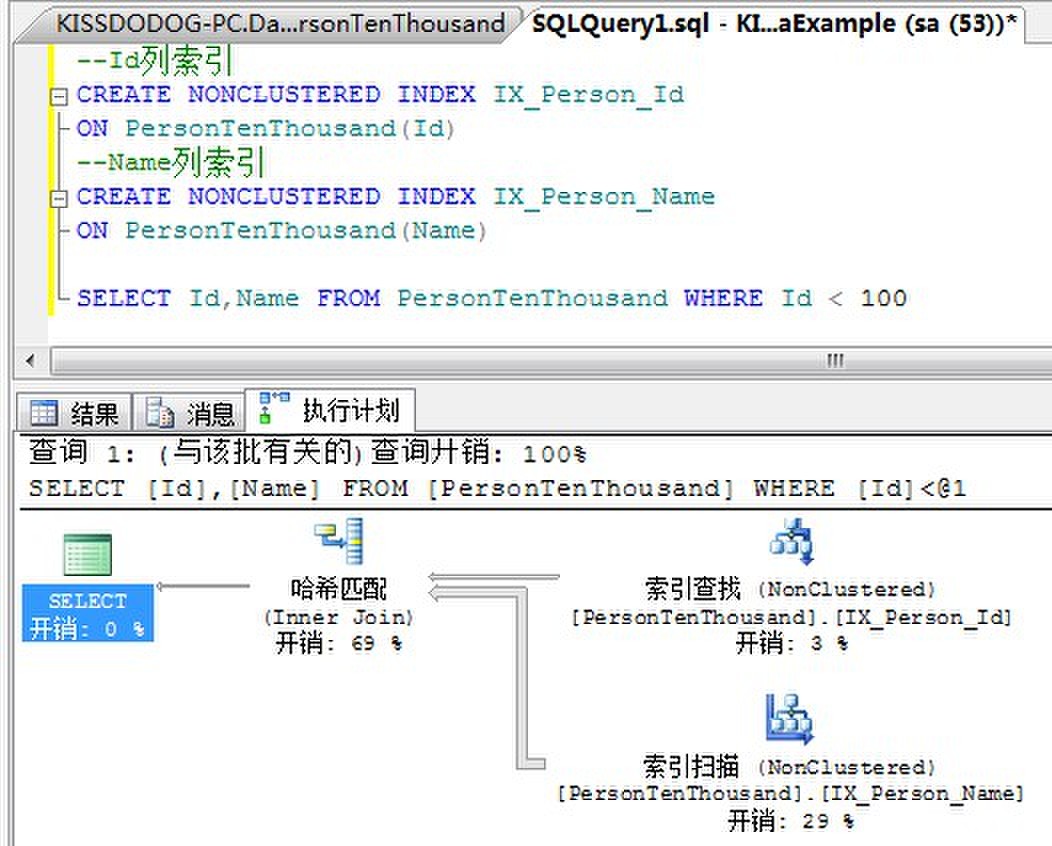
留意到,上面的例子我们创建了两个非聚集索引,一个在 Id列,一个在Name列。但是我们的查询需要同时返回Id列和Name列。而这两个非聚集索引都不完全包含要返回列。这个时候,哈希匹配目的就是通过定位到索引,而不用定位到基本表就能够获得我们所需要的全部数据,这样索引连接就避免了书签查找。
SQL Server 索引 之 书签查找 <第十一篇>的更多相关文章
- SQL Server 索引的自动维护 <第十三篇>
在有大量事务的数据库中,表和索引随着时间的推移而碎片化.因此,为了增进性能,应该定期检查表和索引的碎片,并对具有大量碎片的进行整理. 1.确定当前数据库中所有需要分析碎片的表. 2.确定所有表和索引的 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- 如何获得SQL Server索引使用情况
原文:如何获得SQL Server索引使用情况 原文出自: http://www.mssqltips.com/sqlservertip/1239/how-to-get-index-usage-info ...
- SQL Server 索引列的顺序——真的没关系吗
原文:SQL Server 索引列的顺序--真的没关系吗 翻译自:http://www.mssqltips.com/sqlservertip/2718/sql-server-index-column- ...
- SQL Server 索引维护(1)——系统常见的索引问题
前言: 在很多系统中,比如本人目前管理的数据库,索引经常被滥用,甚至使用DTA(数据库引擎优化顾问)来成批创建索引(DTA目前个人认为它的真正用处应该是在发现缺失的统计信息,在以前的项目中,用过一次D ...
- SQL Server 索引维护:系统常见的索引问题
在很多系统中,比如本人目前管理的数据库,索引经常被滥用,甚至使用DTA(数据库引擎优化顾问)来成批创建索引(DTA目前个人认为它的真正用处应该是在发现缺失的统计信息,在以前的项目中,用过一次DTA,里 ...
- sql server 索引总结三
一.非聚集索引维护 非聚集索引的行定位器值保持相同的聚集索引值,即使该聚集索引列物理上重新定位后,也是如此. 为了优化这个维护开销,SQL Server添加一个指向旧数据页的指针,以在页面分割之后指向 ...
- sql server 索引总结一
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- 转: SQL Server索引的维护 - 索引碎片、填充因子
转:http://www.cnblogs.com/kissdodog/archive/2013/06/14/3135412.html 实际上,索引的维护主要包括以下两个方面: 页拆分 碎片 这两个问题 ...
随机推荐
- 总结Selenium自动化测试方法(三)WebDriver定位元素方法
三.WebDriver定位元素 推荐使用的webdriver是firefox,因为他的firebug更能可以帮助定位页面元素使用 # create a new Firefox session cls. ...
- Vector示例一,二
#include <iostream> int main(void) { double a[] = {1, 2, 3, 4, 5}; std::cout<<mean(a, 5) ...
- Scrum Agile
Scrum Agile 迭代式增量软件开发,敏捷开发,源于丰田汽车的制造流程. HMC测试流程: 1.hmc改配置 2.上ui验证 3.还原hmm(有的需要,有的不需要) 4.addReferal,在 ...
- QQ互发消息
private NewsData data; private void button3_Click(object sender, EventArgs e) //发送 { string x = text ...
- gulp some tips
gulp作为替代grunt的task runner后起之秀,基于nodejs的stream操作模型,大大减少了对磁盘的操作因此大大提高了性能. gulp error handling var gulp ...
- CSS之弧形阴影
简述 网页上经常会出现一些弧形的阴影效果,看起来很漂亮,下面我们来讲述下如何用CSS来实现一个弧形阴影. 简述 阴影 效果 注释 标题 效果 源码 合并 效果 源码 阴影 效果 首先实现一个简单的阴影 ...
- HDU (线段树 单点更新) 敌兵布阵
哎,又切了一天的水题. 线段树果然必须自己写出来才能叫真正的会了,之前一直在套模板确实不好. 这个题目是单点更新 之 单点增减,= ̄ω ̄= #include <cstdio> <&l ...
- 多个MapReduce作业相互依赖时,使用JobControl进行管理
要处理复杂关系的数据,一个工程里面绝对不止一个MapReduce作业,当有多个MapReduce作业时, 并且每个作业之间有依赖关系,所谓的依赖就是一个作业得到的结果是另外一个作业的输入, ...
- 事件类型: 错误 事件来源: Service Control Manager 事件种类: 无 事件 ID: 7000
在控制面板\管理工具\服务里找dns Client 服务,把他启动了
- Cookie存储中文报错:java.lang.IllegalArgumentException: Control character in cookie value or attribute.(转)
项目中做自动登录和保存密码时,Cookie报错Java.lang.IllegalArgumentException,上google查了下 在http://hi.baidu.com/xtxycy/blo ...