python爬虫+正则表达式实例爬取豆瓣Top250的图片
- 直接上全部代码
新手上路代码风格可能不太好
import requests
import re
from fake_useragent import UserAgent #### 用来伪造爬头部信息
ua = UserAgent()
kv = {'user-agent': ua.random}
url = 'https://movie.douban.com/top250?start=0&filter='
index = 0 ####标记爬取图片的数量与命名
for i in range(0, 10):
sum_page = i*25
new_url = re.sub('start=\d+', 'start=%d'%sum_page, url, re.S)
r = requests.get(new_url, headers=kv)
r.encoding = 'utf-8'
text = r.text
#### 以上是一个分页爬取的操作 ####
pictures_part = re.findall('<div class="pic">(.*?)</div>', text, re.S)
for picture in pictures_part:
img = re.findall('src="(.*?)" class', picture, re.S)
pic = requests.get(img[0], headers=kv)
fp = open('imgs\\' + str(index) + '.jpg', 'wb') ####这里选用wb以二进制形式写入文件
fp.write(pic.content)
fp.close()
print('picture' + str(index) + ' has been dawnload')
index += 1
代码部分的解释
- 需要对爬虫的请求头部加以修改,引入fake_useragent库来进行轻微的伪造
- 利用了index在标记爬取图片数量的同时方便为爬取的图片命名
- 关于re库中的sub翻页,利用sub方法进行分页爬取
- 图片保存要以二进制形式写入
- 需要提前在和代码同目录下创建imgs文件夹
- 爬取时不无聊加了这个东西
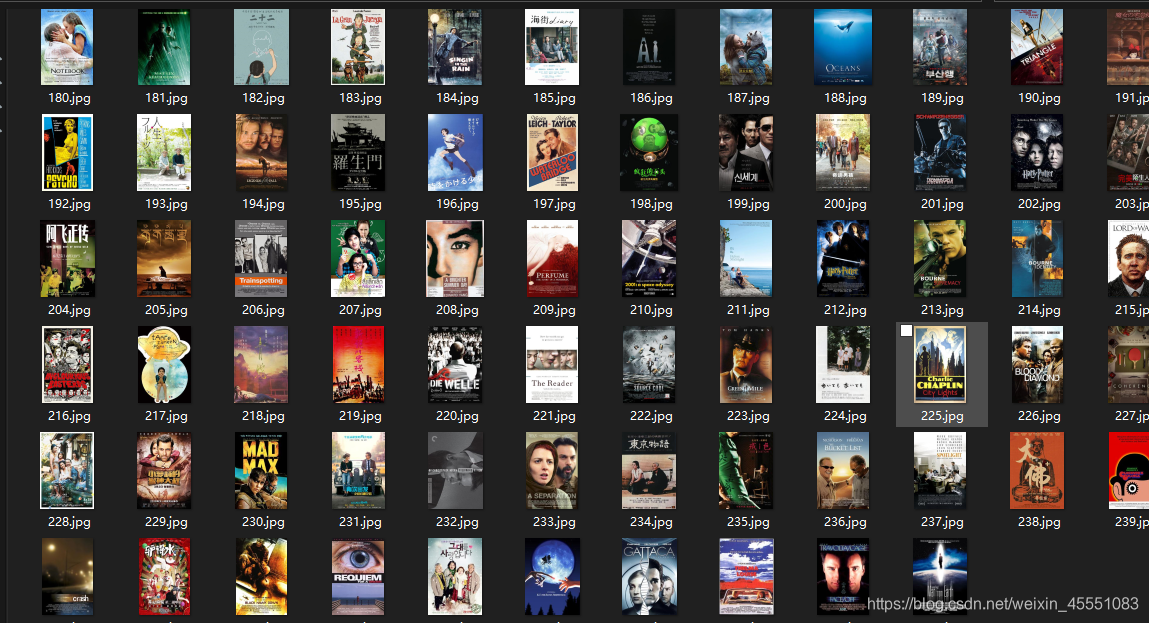
- 爬取的图片
python爬虫+正则表达式实例爬取豆瓣Top250的图片的更多相关文章
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- 爬虫学习--MOOC爬取豆瓣top250
scrapy框架 scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容或者各种图片. scrapy E ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- flask中的分页器
paginate(): 分页查询,返回一个分页对象 paginate(参数1, 参数2, 参数3) : 参数1:当前是第几页(page) 参数2:每页显示几条信息(per_page) 参数3:err ...
- JSP学习笔记(四)
Java Servlet servlet的部署.创建与运行 servlet的工作原理 重定向与转发 使用session 1.servlet的部署.创建与运行 [1].创建Servlet 创建一个Ser ...
- 5.Maven坐标
而这个坐标也意味着jar包等保存在 C:\Users\用户名.m2\repository\org\apache\tomcat\tomcat-catalina\9.0.2
- B. Kvass and the Fair Nut
B. Kvass and the Fair Nut time limit per test 1 second memory limit per test 256 megabytes input sta ...
- JDBC获取连接抛出java.sql.SQLException: The server time zone...
今天尝试数据库,代码确实没问题就是给了给这个东西 java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecogniz ...
- Linux学习66 运维安全-通信加密和解密技术入门
一.Linux Service and Security 1.OpenSSL(ssl/tls)协议 2.OpenSSH(ssh)协议 3.bind(dns) 4.web(http):httpd(apa ...
- 什么是ansible
什么是ansible l Ansible是2013年推出的一款IT自劢化和De ...
- scratch 如何改变变量的作用域
在新建变量的时候,有个选项是“适用于所有角色”还是“仅适用于当前角色”.通常称前者为全局变量,所有角色都可以访问到这个变量:后者,称为局部变量,只能在当前角色里访问到这个变量.例如,在使用克隆功能时, ...
- hadoop(八)集群namenode启动ssh免密登录(完全分布式五)|10
前置章节:hadoop集群配置同步(hadoop完全分布式四)|10 启动namenode之前: 1. 先查看有无节点启动,执行jps查看,有的话停掉 [shaozhiqi@hadoop102 ~]$ ...
- 支持向量机SVM推导
样本(\(x_{i}\),\(y_{i}\))个数为\(m\): \[\{x_{1},x_{2},x_{3}...x_{m}\} \] \[\{y_{1},y_{2},y_{3}...y_{m}\} ...