Java实现拓扑排序
1 问题描述
给定一个有向图,求取此图的拓扑排序序列。
那么,何为拓扑排序?
定义:将有向图中的顶点以线性方式进行排序。即对于任何连接自顶点u到顶点v的有向边uv,在最后的排序结果中,顶点u总是在顶点v的前面。
2 解决方案
2.1 基于减治法实现
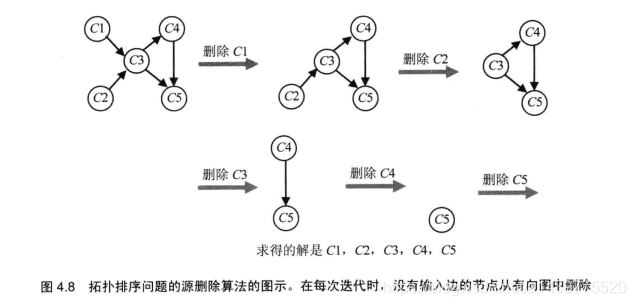
实现原理:不断地做这样一件事,在余下的有向图中求取一个源(source)(PS:定义入度为0的顶点为有向图的源),它是一个没有输入边的顶点,然后把它和所有从它出发的边都删除。(如果有多个这样的源,可以任意选择一个。如果这样的源不存在,算法停止,此时该问题无解),下面给出《算法设计与分析基础》第三版上一个配图:
package com.liuzhen.chapterFour;
import java.util.Stack;
public class TopologicalSorting {
//方法1:基于减治法:寻找图中入度为0的顶点作为即将遍历的顶点,遍历完后,将此顶点从图中删除
/*
* 参数adjMatrix:给出图的邻接矩阵值
* 参数source:给出图的每个顶点的入度值
* 该函数功能:返回给出图的拓扑排序序列
*/
public char[] getSourceSort(int[][] adjMatrix,int[] source){
int len = source.length; //给出图的顶点个数
char[] result = new char[len]; //定义最终返回路径字符数组
int count = 0; //用于计算当前遍历的顶点个数
boolean judge = true;
while(judge){
for(int i = 0;i < source.length;i++){
if(source[i] == 0){ //当第i个顶点入度为0时,遍历该顶点
result[count++] = (char) ('a'+i);
source[i] = -1; //代表第i个顶点已被遍历
for(int j = 0;j < adjMatrix[0].length;j++){ //寻找第i个顶点的出度顶点
if(adjMatrix[i][j] == 1)
source[j] -= 1; //第j个顶点的入度减1
}
}
}
if(count == len)
judge = false;
}
return result;
}
/*
* 参数adjMatrix:给出图的邻接矩阵值
* 函数功能:返回给出图每个顶点的入度值
*/
public int[] getSource(int[][] adjMatrix){
int len = adjMatrix[0].length;
int[] source = new int[len];
for(int i = 0;i < len;i++){
//若邻接矩阵中第i列含有m个1,则在该列的节点就包含m个入度,即source[i] = m
int count = 0;
for(int j = 0;j < len;j++){
if(adjMatrix[j][i] == 1)
count++;
}
source[i] = count;
}
return source;
}
public static void main(String[] args){
TopologicalSorting test = new TopologicalSorting();
int[][] adjMatrix = {{0,0,1,0,0},{0,0,1,0,0},{0,0,0,1,1},{0,0,0,0,1},{0,0,0,0,0}};
int[] source = test.getSource(adjMatrix);
System.out.println("给出图的所有节点(按照字母顺序排列)的入度值:");
for(int i = 0;i < source.length;i++)
System.out.print(source[i]+"\t");
System.out.println();
char[] result = test.getSourceSort(adjMatrix, source);
System.out.println("给出图的拓扑排序结果:");
for(int i = 0;i < result.length;i++)
System.out.print(result[i]+"\t");
}
}
运行结果:
给出图的所有节点(按照字母顺序排列)的入度值:
0 0 2 1 2
给出图的拓扑排序结果:
a b c d e
2.2 基于深度优先查找实现
引用自网友博客中一段解释:
除了使用上面2.1中所示算法之外,还能够借助深度优先遍历来实现拓扑排序。这个时候需要使用到栈结构来记录拓扑排序的结果。
同样摘录一段维基百科上的伪码:
L ← Empty list that will contain the sorted nodes
S ← Set of all nodes with no outgoing edges
for each node n in S do
visit(n)
function visit(node n)
if n has not been visited yet then
mark n as visited
for each node m with an edgefrom m to ndo
visit(m)
add n to L
DFS的实现更加简单直观,使用递归实现。利用DFS实现拓扑排序,实际上只需要添加一行代码,即上面伪码中的最后一行:add n to L。
需要注意的是,将顶点添加到结果List中的时机是在visit方法即将退出之时。
此处重点在于理解:上面伪码中的最后一行:add n to L,对于这一行的理解重点在于对于递归算法执行顺序的理解,递归执行顺序的核心包括两点:1.先执行递归,后进行回溯;2.遵循栈的特性,先进后出。此处可以参考本人另外一篇博客:递归执行顺序的探讨
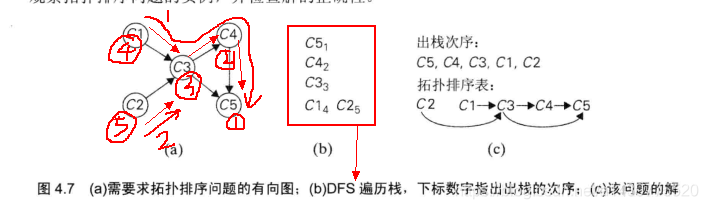
下面请看一个出自《算法设计与分析基础》第三版上一个配图:
package com.liuzhen.chapterFour;
import java.util.Stack;
public class TopologicalSorting {
//方法2:基于深度优先查找发(DFS)获取拓扑排序
public int count1 = 0;
public Stack<Character> result1;
/*
* adjMatrix是待遍历图的邻接矩阵
* value是待遍历图顶点用于是否被遍历的判断依据,0代表未遍历,非0代表已被遍历
*/
public void dfs(int[][] adjMatrix,int[] value){
result1 = new Stack<Character>();
for(int i = 0;i < value.length;i++){
if(value[i] == 0)
dfsVisit(adjMatrix,value,i);
}
}
/*
* adjMatrix是待遍历图的邻接矩阵
* value是待遍历图顶点用于是否被遍历的判断依据,0代表未遍历,非0代表已被遍历
* number是当前正在遍历的顶点在邻接矩阵中的数组下标编号
*/
public void dfsVisit(int[][] adjMatrix,int[] value,int number){
value[number] = ++count1; //把++count1赋值给当前正在遍历顶点判断值数组元素,变为非0,代表已被遍历
for(int i = 0;i < value.length;i++){
if(adjMatrix[number][i] == 1 && value[i] == 0) //当,当前顶点的相邻有相邻顶点可行走且其为被遍历
dfsVisit(adjMatrix,value,i); //执行递归,行走第i个顶点
}
char temp = (char) ('a' + number);
result1.push(temp);
}
public static void main(String[] args){
TopologicalSorting test = new TopologicalSorting();
int[][] adjMatrix = {{0,0,1,0,0},{0,0,1,0,0},{0,0,0,1,1},{0,0,0,0,1},{0,0,0,0,0}};
int[] value = new int[5];
test.dfs(adjMatrix, value);
System.out.println();
System.out.println("使用DFS方法得到拓扑排序序列的逆序:");
System.out.println(test.result1);
System.out.println("使用DFS方法得到拓扑排序序列:");
while(!test.result1.empty())
System.out.print(test.result1.pop()+"\t");
}
}
运行结果:
使用DFS方法得到拓扑排序序列的逆序:
[e, d, c, a, b]
使用DFS方法得到拓扑排序序列:
b a c d e
Java实现拓扑排序的更多相关文章
- 拓扑排序(三)之 Java详解
前面分别介绍了拓扑排序的C和C++实现,本文通过Java实现拓扑排序. 目录 1. 拓扑排序介绍 2. 拓扑排序的算法图解 3. 拓扑排序的代码说明 4. 拓扑排序的完整源码和测试程序 转载请注明出处 ...
- 无前趋的顶点优先的拓扑排序方法(JAVA)(转载http://128kj.iteye.com/blog/1706968)
无前趋的顶点优先的拓扑排序方法 该方法的每一步总是输出当前无前趋(即人度为零)的顶点,其抽象算法可描述为: NonPreFirstTopSort(G){//优先输出无前趋的顶点 w ...
- Java排序算法——拓扑排序
package graph; import java.util.LinkedList; import java.util.Queue; import thinkinjava.net.mindview. ...
- 有向图的拓扑排序算法JAVA实现
一,问题描述 给定一个有向图G=(V,E),将之进行拓扑排序,如果图有环,则提示异常. 要想实现图的算法,如拓扑排序.最短路径……并运行看输出结果,首先就得构造一个图.由于构造图的方式有很多种,这里假 ...
- 有向图和拓扑排序Java实现
package practice; import java.util.ArrayDeque; import java.util.Iterator; import java.util.Stack; pu ...
- 拓扑排序获取所有可能序列JAVA实现
在看算法基础这本书,看到有向无环图,其中介绍到了拓扑排序,讲到了获取拓扑序列的方法,结合自己的理解,用JAVA代码实现了获取所有可能序列,水平有限,效率什么的就没有考虑,下面贴上代码: package ...
- 有向图的拓扑排序的理解和简单实现(Java)
如果图中存在环(回路),那么该图不存在拓扑排序,在这里我们讨论的都是无环的有向图. 什么是拓扑排序 一个例子 对于一部电影的制作过程,我们可以看成是一个项目工程.所有的工程都可以分为若干个" ...
- JAVA邻接矩阵实现拓扑排序
由于一直不适用邻接表 ,现在先贴一段使用邻接矩阵实现图的拓扑排序以及判断有无回路的问题.自己做的图.将就看吧. package TopSort; import java.util.LinkedList ...
- 算法笔记_145:拓扑排序的应用(Java)
目录 1 问题描述 2 解决方案 1 问题描述 给出一些球,从1~N编号,他们的重量都不相同,也用1~N标记加以区分(这里真心恶毒啊,估计很多WA都是因为这里),然后给出一些约束条件,< a ...
随机推荐
- [hdu4358]树状数组
思路:用一个数组记录最近k次的出现位置,然后在其附近更新答案.具体见代码: #pragma comment(linker, "/STACK:10240000,10240000") ...
- [hdu1506]单调队列(栈)
题意:http://acm.hdu.edu.cn/showproblem.php?pid=1506看图一目了然.两个方向单调队列维护下. #include <iostream> #incl ...
- Semaphore和AQS
Semaphore意思的信号量,它的作用是控制访问特定资源的线程数量 构造方法: public Semaphore(int permits) public Semaphore(int permits, ...
- 4-JVM 参数
JVM 参数 标准参数:不会随着jdk版本的变化而变化.比如:java -version.java -help 非标准参数:随着JDK版本的变化而变化. -X参数[用的较少]非标准参数,也就是在JDK ...
- jbpm4.4 发送邮件
测了两天终于成功发送出邮件了,坑爹呢!原来一直用QQ邮箱发送,发现发送不了,提示要用ssl协议进行发送,后来换成了126邮箱,发送成功了!具体配置如下: jbpm定义文件 <?xml versi ...
- .Net Core3.0 WebApi 项目框架搭建:目录
一.目录 .Net Core3.0 WebApi 项目框架搭建 一:实现简单的Resful Api .Net Core3.0 WebApi 项目框架搭建 二:API 文档神器 Swagger .Net ...
- 力扣题解-LCP 06. 拿硬币
题目描述 桌上有 n 堆力扣币,每堆的数量保存在数组 coins 中.我们每次可以选择任意一堆,拿走其中的一枚或者两枚,求拿完所有力扣币的最少次数. 示例 1: 输入:[4,2,1] 输出:4 解释: ...
- 笨办法学习python之hashmap
#!/user/bin/env python #-*-coding:utf-8 -*- #Author: qinjiaxi #初始化aMap列表,把列表num_buckets添加到aMap中,num_ ...
- css多行省略和单行省略
实现文本省略: <!-- html代码 --> <p class="single">该文的主题思想即对自由境界的向往.朱自清当时虽置身在污浊黑暗的旧中国,但 ...
- vim命令备份
vim命令 vim键盘位置说明 在命令状态下对当前行用 == (连按=两次), 或对多行用 n==(n是自然数)表示自动缩进从当前行起的下面n行. 可以试试把代码缩进任意打乱再用 n== 排版,相当于 ...