scrapy 在爬取过程中抓取下载图片
先说前提,我不推荐在sarapy爬取过程中使用scrapy自带的 ImagesPipeline 进行下载,是在是太耗时间了
最好是保存,在使用其他方法下载
我这个是在 https://blog.csdn.net/qq_41781877/article/details/80631942 看到的,可以稍微改改来讲解
文章不想其他文章说的必须在items.py 中建立 image_urls和image_path ,可以直接无视
只需要yield返回的item中有你需要的图片下载链接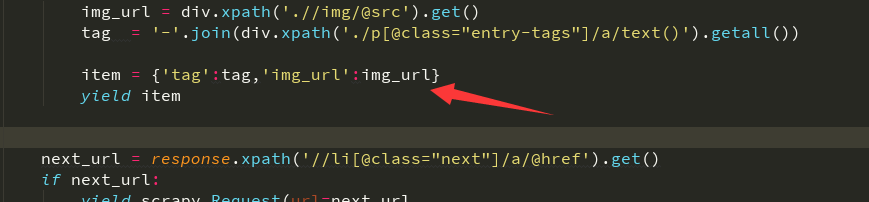
设置mid中的ua和ip,异常情况啥的,接下来是在pip中借用scrapy自带的图片下载类
ImagesPipeline 接下来基本是固定模板,创建一个类三个函数,都是固定的,除了方法可能根据需求改写 pip文件重写
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem import re
import scrapy class SaveImagePipeline(ImagesPipeline):
# 使用这个类,运行的第一个函数是这个get_media_requestsdef get_media_requests(self, item, info):# 下载图片,如果传过来的是集合需要循环下载
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
# yield Request(url=item['url'],meta={'name':item['title']}) # 这是我自己改的,根据yield给的tag和img_url切割得到一个图片名,传递给下一个函数
name = item['tag'] + item['img_url'].split('/')[-1]
yield scrapy.Request(url=item['img_url'], meta={'name':name}) # 第三个运行函数,判断有没有保存成功 ,我该写了没有保存成功者保存在本地文件中,以后进行抓取
def item_completed(self, results, item, info):
# 是一个元组,第一个元素是布尔值表示是否成功
if not results[0][0]:
with open('img_error.txt', 'a')as f:
error = str(item['tag']+' '+item['img_url'])
f.write(error)
f.write('\n')
raise DropItem('下载失败')
return item
# 第二个运行函数
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None):
# 接收上面meta传递过来的图片名称
# 我写的图片名
name = request.meta['name']
# 根据情况来选择,如果保存图片的名字成一个体系,那么可以使用这个
image_name = request.url.split('/')[-1]
# 清洗Windows系统的文件夹非法字符,避免无法创建目录
folder_strip = re.sub(r'[?\\*|“<>:/]', '', str(name))
# 分文件夹存储的关键:{0}对应着name;{1}对应着image_guid
# filename = u'{0}/{1}'.format(folder_strip, image_name) # 如果有体系,可以使用这个
filename = u'{0}'.format(folder_strip)
return filename
接下来在settings中设置文件放置在哪
IMAGES_STORE = ‘./meizi’ # meizi是放置图片的文件夹,随意设置名字
# 打开pip
ITEM_PIPELINES = {
'爬虫.pipelines.SaveImagePipeline': 300,
}
,如果图片有反爬,可以设置一个referer
我的如下 ,连同ua一起设置
import user_agent
class Girl13_UA_Middleware(object):
def process_request(self, request, spider):
request.headers['User_Agent'] = user_agent.generate_user_agent()
referer = request.url
if referer:
request.headers['Referer'] = referer
settings中将这个中间件mid设置为1
不过用这个还是很多下载出现错误404 ,虽然有一些下载下来了,五五开吧
要么一堆一次成功,要么一堆错误,有可能是ip访问频率问题吧,下次我再试试
github源码地址 https://github.com/z1421012325/girl13_spider
scrapy 在爬取过程中抓取下载图片的更多相关文章
- FETCH - 用游标从查询中抓取行
SYNOPSIS FETCH [ direction { FROM | IN } ] cursorname where direction can be empty or one of: NEXT P ...
- scrapy爬虫成长日记之将抓取内容写入mysql数据库
前面小试了一下scrapy抓取博客园的博客(您可在此查看scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据),但是前面抓取的数据时保存为json格式的文本文件中的.这很显然不满足我 ...
- windows中抓取hash小结(上)
我上篇随笔说到了内网中横向移动的几种姿势,横向移动的前提是获取了具有某些权限的用户的明文密码或hash,正愁不知道写点啥,那就来整理一下这个"前提"-----如何在windows系 ...
- java练习题(字符串类):显示4位验证码、输出年月日、从XML中抓取信息
1.显示4位验证码 注:大小写字母.数字混合 public static void main(String[] args) { String s="abcdefghijklmnopqrstu ...
- #在FLAT模式下,需要设置flat子网,VM的IP从这个设置的子网中抓取,这时flat_injected需要设置为True,系统才能自动获得IP,如果flat
#在FLAT模式下,需要设置flat子网,VM的IP从这个设置的子网中抓取,这时flat_injected需要设置为True,系统才能自动获得IP,如果flat子网和主机网络是同一网络,网络管理员要注 ...
- ListView与.FindControl()方法的简单练习 #2 -- ItemUpdting事件中抓取「修改后」的值
原文出處 http://www.dotblogs.com.tw/mis2000lab/archive/2013/06/24/listview_itemupdating_findcontrol_201 ...
- 【应用服务 App Service】App Service中抓取网络日志
问题描述 众所周知,Azure App Service是一种PaaS服务,也就是说,IaaS层面的所有内容都由平台维护,所以使用App Service的我们根本无法触碰到远行程序的虚拟机(VM), 所 ...
- windows中抓取hash小结(下)
书接上回,windows中抓取hash小结(上) 指路链接 https://www.cnblogs.com/lcxblogs/p/13957899.html 继续 0x03 从ntds.dit中抓取 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
随机推荐
- ACG记录整理
资料来源 日文维基百科 bangumi番组计划 中文维基百科 百度百科 豆瓣电影 资料类型 テレビアニメ OVA アニメ映画 Webアニメ 内容说明 番名,带超链接介绍,尽量选用国内网站介绍, ...
- Emgu.CV.CvInvoke的类型初始值设定项引发异常”TypeInitializationException”的问题
问题如图: 解决方案: 1.记住EmguCV的安装位置:X:\XXX\XXX… 本测试方案中EmguCV的安装位置:D:\Emgu,操作时记得用自己的EmguCV安装路径替换掉D:\Emgu. 2.添 ...
- every|each|the用于姓氏的复数形式|comrades-in-arms|clothes are|word|steel|affect|effect
________ man in the crowd raised his hand. A. All B. Each C. Every D. Both 题目解析 考查代词的用法.此句意思是:人群 ...
- 使用jxl操作之一: 实现对Excel简单读写操作
项目目录树 对象类UserObject UserObject.java package com.dlab.jxl; public class UserObject { private String u ...
- 苹果联合创始人高调宣布弃用Facebook是什么梗?
这段时间,扎克伯格非常郁闷.泄密丑闻不仅让Facebook股价大跌.引来审查等,还被众多互联网.科技大佬批判.孤立.如,"钢铁侠"马斯克就直接删除了SpaceX 和特斯拉的 Fac ...
- web中间件之nginx
web中间件之nginx https://www.jianshu.com/p/d8bd75c0fb1b 对nginx正向代理和反向代理理解特别好的一篇文章. 一.nginx nginx缺点,负载均 ...
- python3之urllib基础
urllib简单应用html=urllib.request.urlopen(域名/网址).read().decode('utf-8')----->--->urlopen-->获取源码 ...
- 如何为MyEclipse添加XML文档所使用的DTD
1.打开MyEclipse,找到菜单栏"Window"---->"Preferences(首选项)": 2.在左侧导航菜单栏找到"MyEclip ...
- <JZOJ5913>林下风气
快乐dp 反正考场写挂 #include<cstdio> #include<cstring> #include<cctype> #include<iostre ...
- 吴裕雄--天生自然 R语言开发学习:高级数据管理(续三)
#-----------------------------------# # R in Action (2nd ed): Chapter 5 # # Advanced data management ...