Spark入门(三)--Spark经典的单词统计
spark经典之单词统计
准备数据
既然要统计单词我们就需要一个包含一定数量的文本,我们这里选择了英文原著《GoneWithTheWind》(《飘》)的文本来做一个数据统计,看看文章中各个单词出现频次如何。为了便于大家下载文本。可以到GitHub上下载文本以及对应的代码。我将文本放在项目的目录下。
首先我们要读取该文件,就要用到SparkContext中的textFile的方法,我们尝试先读取第一行。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
println(sc.textFile("./GoneWithTheWind").first())
}
}
java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
System.out.println(sc.textFile("./GoneWithTheWind").first());
}
}
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("HelloWorld")
sc = SparkContext(conf=conf)
print(sc.textFile("./GoneWithTheWind").first())
得到输出
Chapter 1
以scala为例,其余两种语言也差不多。第一步我们创建了一个SparkConf
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
这里我们设置Master为local,该程序名称为WordCount,当然程序名称可以任意取,和类名不同也无妨。但是这个Master则不能乱写,当我们在集群上运行,用spark-submit的时候,则要注意。我们现在只讨论本地的写法,因此,这里只写local。
接着一句我们创建了一个SparkContext,这是spark的核心,我们将conf配置传入初始化
val sc = new SparkContext(conf)
最后我们将文本路径告诉SparkContext,然后输出第一行内容
println(sc.textFile("./GoneWithTheWind").first())
开始统计
接着我们就可以开始统计文本的单词数了,因为单词是以空格划分,所以我们可以把空格作为单词的标记。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
//设置数据路径
val text = sc.textFile("./GoneWithTheWind")
//将文本数据按行处理,每行按空格拆成一个数组
// flatMap会将各个数组中元素合成一个大的集合
val textSplit = text.flatMap(line =>line.split(" "))
//处理合并后的集合中的元素,每个元素的值为1,返回一个元组(key,value)
//其中key为单词,value这里是1,即该单词出现一次
val textSplitFlag = textSplit.map(word => (word,1))
//reduceByKey会将textSplitFlag中的key相同的放在一起处理
//传入的(x,y)中,x是上一次统计后的value,y是本次单词中的value,即每一次是x+1
val countWord = textSplitFlag.reduceByKey((x,y)=>x+y)
//将计算后的结果存在项目目录下的result目录中
countWord.saveAsTextFile("./result")
}
}
java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
//设置数据的路径
JavaRDD<String> textRDD = sc.textFile("./GoneWithTheWind");
//将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合
//这里需要注意的是FlatMapFunction中<String, String>,第一个表示输入,第二个表示输出
//与Hadoop中的map-reduce非常相似
JavaRDD<String> splitRDD = textRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//处理合并后的集合中的元素,每个元素的值为1,返回一个Tuple2,Tuple2表示两个元素的元组
//值得注意的是上面是JavaRDD,这里是JavaPairRDD,在返回的是元组时需要注意这个区别
//PairFunction中<String, String, Integer>,第一个String是输入值类型
//第二第三个,String, Integer是返回值类型
//这里返回的是一个word和一个数值1,表示这个单词出现一次
JavaPairRDD<String, Integer> splitFlagRDD = splitRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s,1);
}
});
//reduceByKey会将splitFlagRDD中的key相同的放在一起处理
//传入的(x,y)中,x是上一次统计后的value,y是本次单词中的value,即每一次是x+1
JavaPairRDD<String, Integer> countRDD = splitFlagRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
});
//将计算后的结果存在项目目录下的result目录中
countRDD.saveAsTextFile("./resultJava");
}
}
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("HelloWorld")
sc = SparkContext(conf=conf)
# 设置数据的路径
textData = sc.textFile("./GoneWithTheWind")
# 将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合
splitData = textData.flatMap(lambda line:line.split(" "))
# 处理合并后的集合中的元素,每个元素的值为1,返回一个元组(key,value)
# 其中key为单词,value这里是1,即该单词出现一次
flagData = splitData.map(lambda word:(word,1))
# reduceByKey会将textSplitFlag中的key相同的放在一起处理
# 传入的(x,y)中,x是上一次统计后的value,y是本次单词中的value,即每一次是x+1
countData = flagData.reduceByKey(lambda x,y:x+y)
#输出文件
countData.saveAsTextFile("./result")
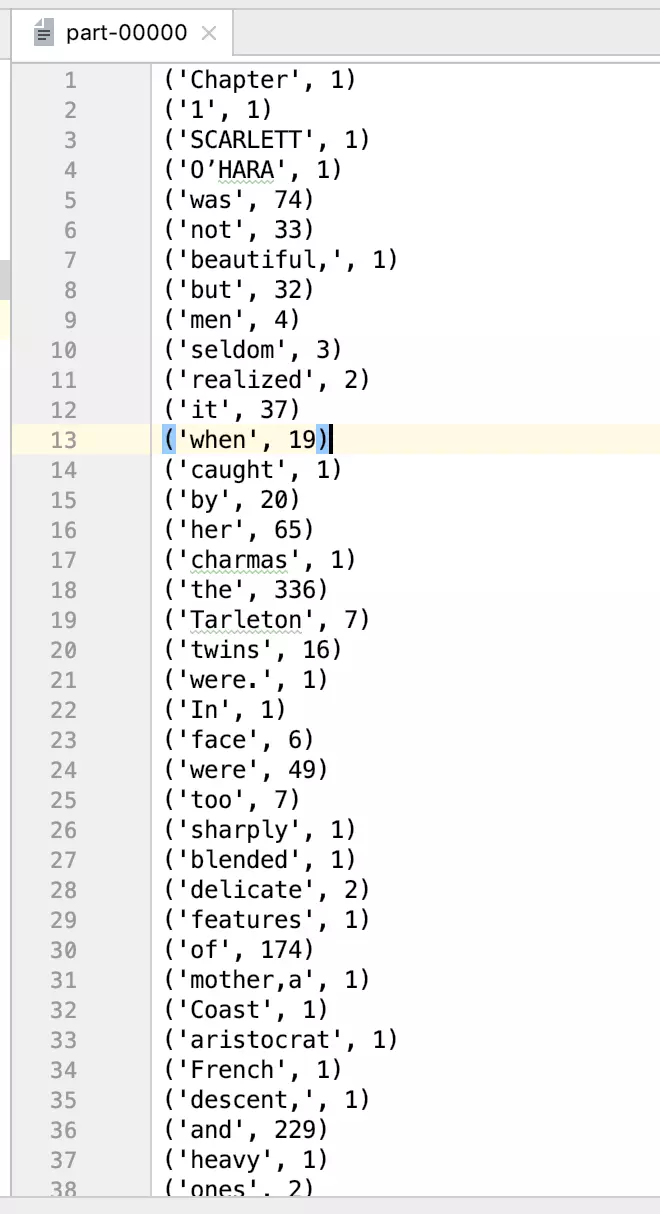
运行后在住目录下得到一个名为result的目录,该目录如下图,SUCCESS表示生成文件成功,文件内容存储在part-00000中

我们可以查看文件的部分内容:
('Chapter', 1)
('1', 1)
('SCARLETT', 1)
('O’HARA', 1)
('was', 74)
('not', 33)
('beautiful,', 1)
('but', 32)
('men', 4)
('seldom', 3)
('realized', 2)
('it', 37)
('when', 19)
('caught', 1)
('by', 20)
('her', 65)
('charmas', 1)
('the', 336)
('Tarleton', 7)
('twins', 16)
('were.', 1)
('In', 1)
('face', 6)
('were', 49)
...
...
...
...
这样就完成了一个spark的真正HelloWorld程序--单词计数。对比三个语言版本的程序,发现一个事实那就是,用scala和python写的代码非常简洁而且易懂,而Java实现的则相对复杂,难懂。当然这个易懂和难懂是相对而言的。如果你只会Java无论如何你都应该从中能看懂java的程序,而简洁的scala和python对你来说根本看不懂。这也无妨,语言只是工具,重点看你怎么用。况且,我们使用java8的特性也可以写出简洁的代码。
java8实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
countJava8(sc);
}
public static void countJava8(JavaSparkContext sc){
sc.textFile("./GoneWithTheWind")
.flatMap(s->Arrays.asList(s.split(" ")).iterator())
.mapToPair(s->new Tuple2<>(s,1))
.reduceByKey((x,y)->x+y)
.saveAsTextFile("./resultJava8");
}
}
spark的优越性在这个小小的程序中已经有所体现,计算一本书的每个单词出现的次数,spark在单机上运行(读取文件、生成临时文件、将结果写到硬盘),加载-运行-结束只花费了2秒时间。
对程序进行优化
程序是否还能再简单高效呢?当然是可以的,我们可以用countByValue这个函数,这个函数正是常用的计数的方法。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
//设置数据路径
val text = sc.textFile("./GoneWithTheWind")
//将文本数据按行处理,每行按空格拆成一个数组
// flatMap会将各个数组中元素合成一个大的集合
val textSplit = text.flatMap(line =>line.split(" "))
println(textSplit.countByValue())
}
}
运行得到结果
Map(Heknew -> 1,   “Ashley -> 1, “Let’s -> 1, anarresting -> 1, of. -> 1, pasture -> 1, war’s -> 1, wall. -> 1, looks -> 2, ain’t -> 7,.......

java实现
public class WordCountJava {
public static void main(String[] args){
SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCountJava");
JavaSparkContext sc = new JavaSparkContext(conf);
countJava(sc);
}
public static void countJava(JavaSparkContext sc){
//设置数据的路径
JavaRDD<String> textRDD = sc.textFile("./GoneWithTheWind");
//将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合
//这里需要注意的是FlatMapFunction中<String, String>,第一个表示输入,第二个表示输出
//与Hadoop中的map-reduce非常相似
JavaRDD<String> splitRDD = textRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
System.out.println(splitRDD.countByValue());
}
}
运行得到结果
{Heknew=1,   “Ashley=1, “Let’s=1, anarresting=1, of.=1, pasture=1, war’s=1, wall.=1, looks=2, ain’t=7, Clayton=1, approval.=1, ideas=1,
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("HelloWorld")
sc = SparkContext(conf=conf)
# 设置数据的路径
textData = sc.textFile("./GoneWithTheWind")
# 将文本数据按行处理,每行按空格拆成一个数组,flatMap会将各个数组中元素合成一个大的集合
splitData = textData.flatMap(lambda line:line.split(" "))
print(splitData.countByValue())
运行得到结果:
defaultdict(<class 'int'>, {'Chapter': 1, '1': 1, 'SCARLETT': 1, 'O’HARA': 1, 'was': 74, 'not': 33, 'beautiful,': 1, 'but': 32, 'men': 4,
spark的优越性在这个小小的程序中已经有所体现,计算一本书的每个单词出现的次数,spark在单机上运行(读取文件、生成临时文件、将结果写到硬盘),加载-运行-结束只花费了2秒时间。如果想要获取源代码以及数据内容,可以前往我的github下载。
转自:https://juejin.im/post/5c768f5b6fb9a049b348a811
Spark入门(三)--Spark经典的单词统计的更多相关文章
- 一、spark入门之spark shell:wordcount
1.安装完spark,进入spark中bin目录: bin/spark-shell scala> val textFile = sc.textFile("/Users/admin/ ...
- spark实验(三)--Spark和Hadoop的安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- 二、spark入门之spark shell:文本中发现5个最常用的word
scala> val textFile = sc.textFile("/Users/admin/spark-1.5.1-bin-hadoop2.4/README.md") s ...
- Spark入门:Spark运行架构(Python版)
此文为个人学习笔记如需系统学习请访问http://dblab.xmu.edu.cn/blog/1709-2/ 基本概念 * RDD:是弹性分布式数据集(Resilient Distributed ...
- Spark入门(四)--Spark的map、flatMap、mapToPair
spark的RDD操作 在上一节Spark经典的单词统计中,了解了几个RDD操作,包括flatMap,map,reduceByKey,以及后面简化的方案,countByValue.那么这一节将介绍更多 ...
- spark复习笔记(3):使用spark实现单词统计
wordcount是spark入门级的demo,不难但是很有趣.接下来我用命令行.scala.Java和python这三种语言来实现单词统计. 一.使用命令行实现单词的统计 1.首先touch一个a. ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- 2、 Spark Streaming方式从socket中获取数据进行简单单词统计
Spark 1.5.2 Spark Streaming 学习笔记和编程练习 Overview 概述 Spark Streaming is an extension of the core Spark ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
随机推荐
- numpy和pandas的基础索引切片
Numpy的索引切片 索引 In [72]: arr = np.array([[[1,1,1],[2,2,2]],[[3,3,3],[4,4,4]]]) In [73]: arr Out[73]: a ...
- XP停止更新不用愁 瑞星XP护盾给你持续保护
4月8日,微软正式结束了Windows XP的支持,所有XP系统将不会再收到来自微软提供的补丁和安全更新等服务,叱咤OS江湖十几年的一代操作系统终于完美谢幕.但谢幕不等于消失,据相关机构统计,虽然微软 ...
- navisworks安装未完成,某些产品无法安装的解决方法
navisworks提示安装未完成,某些产品无法安装该怎样解决呢?,一些朋友在win7或者win10系统下安装navisworks失败提示navisworks安装未完成,某些产品无法安装,也有时候想重 ...
- Inventor 卸载工具,完美彻底卸载清除干净Inventor各种残留注册表和文件
一些同学安装Inventor出错了,也有时候想重新安装Inventor的时候会出现这种本电脑windows系统已安装Inventor,你要是不留意直接安装,只会安装Inventor的附件,Invent ...
- idea常见需求
1.给class加注释模板 /** *@ClassName ${NAME} *@Description TODO *@Author xxx *@Date ${DATE} ${TIME} *@Versi ...
- RE模块(正则)
RE模块和正则表达式 正则表达式 正则就是用来筛选字符串中的特定的内容的(只要是reg...一般情况下都是跟正则有关) re模块与正则表达式之间的关系: 正则表达式不是python独有的 它是一门独立 ...
- 会编程的 AI + 会修 Bug 的 AI,等于什么 ?
2017-02-25 Python开发者 (点击上方公众号,可快速关注) 关于人工智能未来的畅想,除了家庭服务机器人,快递无人机,医用机器人等等,Lucas Carlson 认为人工智能在另外一个领域 ...
- Shell之Here Document
EOF本意是 End Of File,表明到了文件末尾. 使用格式基本是这样的: 命令 << EOF 内容段EOF将“内容段”整个作为命令的输入.你的代码里就是用cat命令读入整段字符串并 ...
- Jenkins+Git+Fastlane+Fir CI集成
上一篇有讲关于fastlane自动化部署,本篇将会着重讲关于fastlane的实际应用. 目标: 利用自动化jenkins打包工具,自动拉取git仓库代码 不需要通过手动检查修改xcode中项目配置修 ...
- Spark中Task数量的分析
本文主要说一下Spark中Task相关概念.RDD计算时Task的数量.Spark Streaming计算时Task的数量. Task作为Spark作业执行的最小单位,Task的数量及运行快慢间接决定 ...