新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。 在处理大规模数据集时,速度是非常重要的。速度快就意味着我们可以进行交互式的数据操作, 否则我们每次操作就需要等待数分钟甚至数小时。
Spark 的一个主要特点就是能够在内存中进行计算, 因而更快。不过即使是必须在磁盘上进行的复杂计算, Spark 依然比 MapReduce 更加高效。
2.Spark生态系统
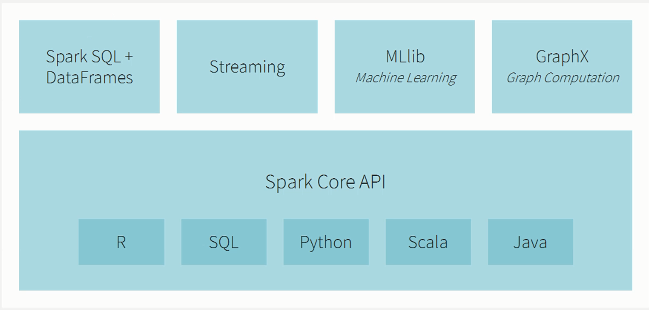
3.Spark学网站
1)databricks 网站
2)spark 官网
3)github 网站
4.Spark2.x源码下载及编译生成版本
1)Spark2.2源码下载到bigdata-pro02.kfk.com节点的/opt/softwares/目录下。
解压
tar -zxf spark-2.2.0.tgz -C /opt/modules/
2)spark2.2编译所需要的环境:Maven3.3.9和Java8
3)Spark源码编译的方式:Maven编译、SBT编译(暂无)和打包编译make-distribution.sh
a)下载Jdk8并安装
tar -zxf jdk8u11-linux-x64.tar.gz -C /opt/modules/
b)JAVA_HOME配置/etc/profile
vi /etc/profile
export JAVA_HOME=/opt/modules/jdk1.8.0_11
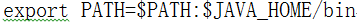
编辑退出之后,使之生效
source /etc/profile
c)如果遇到不能加载当前版本的问题
rpm -qa|grep jdk
rpm -e --nodeps jdk版本
which java 删除/usr/bin/java
d)下载并解压Maven
下载Maven
解压maven
tar -zxf apache-maven-3.3.9-bin.tar.gz -C /opt/modules/
配置MAVEN_HOME
vi /etc/profile
export MAVEN_HOME=/opt/modules/apache-maven-3.3.9
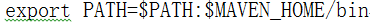
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=1024M -XX:ReservedCodeCacheSize=1024M"
编辑退出之后,使之生效
source /etc/profile
查看maven版本
mvn -version
e)编辑make-distribution.sh内容,可以让编译速度更快
VERSION=2.2.0
SCALA_VERSION=2.11.8
SPARK_HADOOP_VERSION=2.5.0
#支持spark on hive
SPARK_HIVE=1
4)通过make-distribution.sh源码编译spark
./dev/make-distribution.sh --name custom-spark --tgz -Phadoop-2.5 -Phive -Phive-thriftserver -Pyarn
#编译完成之后解压
tar -zxf spark-2.2.0-bin-custom-spark.tgz -C /opt/modules/
5.scala安装及环境变量设置
1)下载
2)解压
tar -zxf scala-2.11.8.tgz -C /opt/modules/
3)配置环境变量
vi /etc/profile
export SCALA_HOME=/opt/modules/scala-2.11.8
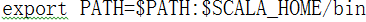
4)编辑退出之后,使之生效
source /etc/profile
6.spark2.0本地模式运行测试
1)启动spark-shell测试
./bin/spark-shell
scala> val textFile = spark.read.textFile("README.md")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 126
scala> textFile.first()
res1: String = # Apache Spark
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.filter(line => line.contains("Spark")).count() // How many lines contain "Spark"?
res3: Long = 15
2)词频统计
a)创建一个本地文件stu.txt
vi /opt/datas/stu.txt
hadoop storm spark
hbase spark flume
spark dajiangtai spark
hdfs mapreduce spark
hive hdfs solr
spark flink storm
hbase storm es
solr dajiangtai scala
linux java scala
python spark mlib
kafka spark mysql
spark es scala
azkaban oozie mysql
storm storm storm
scala mysql es
spark spark spark
b)spark-shell 词频统计
./bin/spark-shell
scala> val rdd = spark.read.textFile("/opt/datas/stu.txt")
#词频统计
scala> val lines = rdd.flatmap(x => x.split(" ")).map(x => (x,1)).rdd.reduceBykey((a,b) => (a+b)).collect
#对词频进行排序
scala> val lines = rdd.flatmap(x => x.split(" ")).map(x => (x,1)).rdd.reduceBykey((a,b) => (a+b)).map(x =>(x._2,x._1)).sortBykey().map(x => (x._2,x._1)).collect
7.spark 服务web监控页面
通过web页面查看spark服务情况
bigdata-pro01.kfk.com:4040
新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtable 的开源实现,与 ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
随机推荐
- 动态规划: 最大m子段和问题的详细解题思路(JAVA实现)
这道最大m子段问题我是在课本<计算机算法分析与设计>上看到,课本也给出了相应的算法,也有解这题的算法的逻辑.但是,看完之后,我知道这样做可以解出正确答案,但是我如何能想到要这样做呢? 课本 ...
- 使用SQL计算宝宝每次吃奶的时间间隔(数据保障篇)
目前程序从功能上其实已经完全满足客户(当然我这里的客户都是指媳妇儿^_^)需求,具体可参考: 使用SQL计算宝宝每次吃奶的时间间隔 使用SQL计算宝宝每次吃奶的时间间隔(续) 那么本篇 使用SQL计算 ...
- XC1263 签到题(哇 ,写得我怀疑人生啊!!!@!@)
1263: 签到题 时间限制: 1 Sec 内存限制: 128 MB提交: 174 解决: 17 标签提交统计讨论版 题目描述 大家刚过完寒假,肯定还没有进入状态,特意出了一道签到题给各位dala ...
- 大盘及策略收益率的公式推导与Python代码
一.模型前提与假设 设策略总天数为\(n\).第\(t\)日大盘的收盘价为\(P_t\).第\(t\)日的单日收益率为\(r_t\).\(n\)天的累积收益率为\(r_{cum}\) 假设策略仅买卖大 ...
- Codeforces Global Round 6 - D. Decreasing Debts(思维)
题意:有$n$个人,$m$个债务关系,$u_{i}$,$v_{i}$,$d_{i}$表示第$u_{i}个人$欠第$v_{i}$个人$d_{i}$块钱,现在你需要简化债务关系,使得债务总额最小.比如,$ ...
- 【Android多线程】Thread和线程池
https://www.bilibili.com/video/av65170691?p=3 (本文为此视频听课笔记) 一.为什么要使用多线程 二.Thread 2.1 通过继承Thread类 2.2 ...
- Weka算法算法翻译(部分)
目录 Weka算法翻译(部分) 1. 属性选择算法(select attributes) 1.1 属性评估方法 1.2 搜索方法 2. 分类算法 2.1 贝叶斯算法 2.2 Functions 2.3 ...
- android 支持上拉加载,下拉刷新的列表控件SwipeRefreshLayout的二次封装
上拉加载,下拉刷新的列表控件,大家一定都封装过,或者使用过 源代码,我会在最后贴出来 这篇代码主要是为了解决两个问题 1.滑动冲突得问题 2.listview无数据时,无数据布局的展示问题 下方列出的 ...
- springmvc_ajax异步上传文件(基于ajaxfileupload.js)
引入js <script th:src="@{/js/ajaxfileupload.js}"></script> html <tr> <t ...
- 微信小程序 列表倒计时
最近要实现一个列表倒计时的功能,写了个demo 展示图 <view class="center colu"> <view class="time&quo ...