入门大数据---Storm搭建与应用
1.Storm在Linux环境配置
| 主机名 | tuge1 | tuge2 | tuge3 |
|---|---|---|---|
| 部署环境 | Zookeeper/Nimbus | Zookeeper/Supervisor | Zookeeper/Supervisor |
(部署一览图)
1.1 配置Zookeeper环境(三台机器都要配置,可以先配置一台,然后分发)
去官网下载apache-zookeeper-3.5.5-bin.tar.gz,然后上传到Linux的/opt/zookeeper目录下。(如果没有创建下。)
解压
tar -xvf apache-zookeeper-3.5.5-bin.tar.gz
配置环境
vim /etc/profile
export ZK_HOME=/opt/zookeeper/apache-zookeeper-3.5.5-bin export PATH=$ZK_HOME/bin:$PATH
配置Zookeeper日志自动清理
通过配置 autopurge.snapRetainCount 和autopurge.purgeInterval这两个参数能够实现定时清理了。
这两个参数都是在zoo.cfg中配置的,将其前面的注释去掉,根据需要修改日志保留个数:autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
1.2 配置Java环境(三台机器都要配置)
去官网下载jdk-8u221-linux-x64.tar.gz,然后上传到/opt/java目录下。(如果没有创建下,根据官网要下载Java8+版本)
解压
tar -xvf jdk-8u221-linux-x64.tar.gz
配置环境
vim /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$PATH
1.3 配置Storm环境(三台机器都要配置)
配置全局环境
- 去官网下载apache-storm-2.1.0.tar.gz,然后上传到/opt/storm目录下。(没有创建下)
- 解压
tar -xvf apache-storm-2.1.0.tar.gz
- 配置环境
vim /etc/profile
export STORM_HOME=/opt/storm/apache-storm-2.1.0
export PATH=$STORM_HOME/bin:$JAVA_HOME/bin:$ZK_HOME/bin:$PATH
- 重新加载配置文件
source /etc/profile
配置storm.yaml文件
vim /opt/storm/apache-storm-2.1.0/conf/storm.yaml
- 配置Zookeeper服务器:
将
# storm.zookeeper.servers:
# - "server1"
# - "server2"
改为
storm.zookeeper.servers:
- "tuge1"
- "tuge2"
- "tuge3"
- 配置Zookeeper服务器:
创建一个状态目录:
创建 storm-local 目录,并修改权限
mkdir -p /opt/storm/apache-storm-2.1.0/status
storm.local.dir: "/opt/storm/apache-storm-2.1.0/status"
配置主控节点地址
nimbus.seeds: ["tuge1"]
配置Worker计算机数量(实际生产环境根据执行的任务来配置,我这里学习参照官网配置四个先)
添加几个端口,最多就能分配 几个Worker。这里配置四个先。
在storm.yaml里面添加如下配置:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
1.4启动Storm
先启动Zookeeper,三台都启动,具体启动步骤参考之前博客
启动Nimbus和UI,在tuge1上执行
./storm nimbus >./logs/nimbus.out 2>&1 &
./storm ui >>./logs/ui.out 2>&1 &
启动Supervisor,在tuge2,tuge3上运行
./storm supervisor >>./logs/supervisor.out 2>&1 &
PS: >dev>null 2>&1的意思是,将错误输入到标准输出,再将标准输出输入到文件dev和null里面,最后的&意思是后台执行。
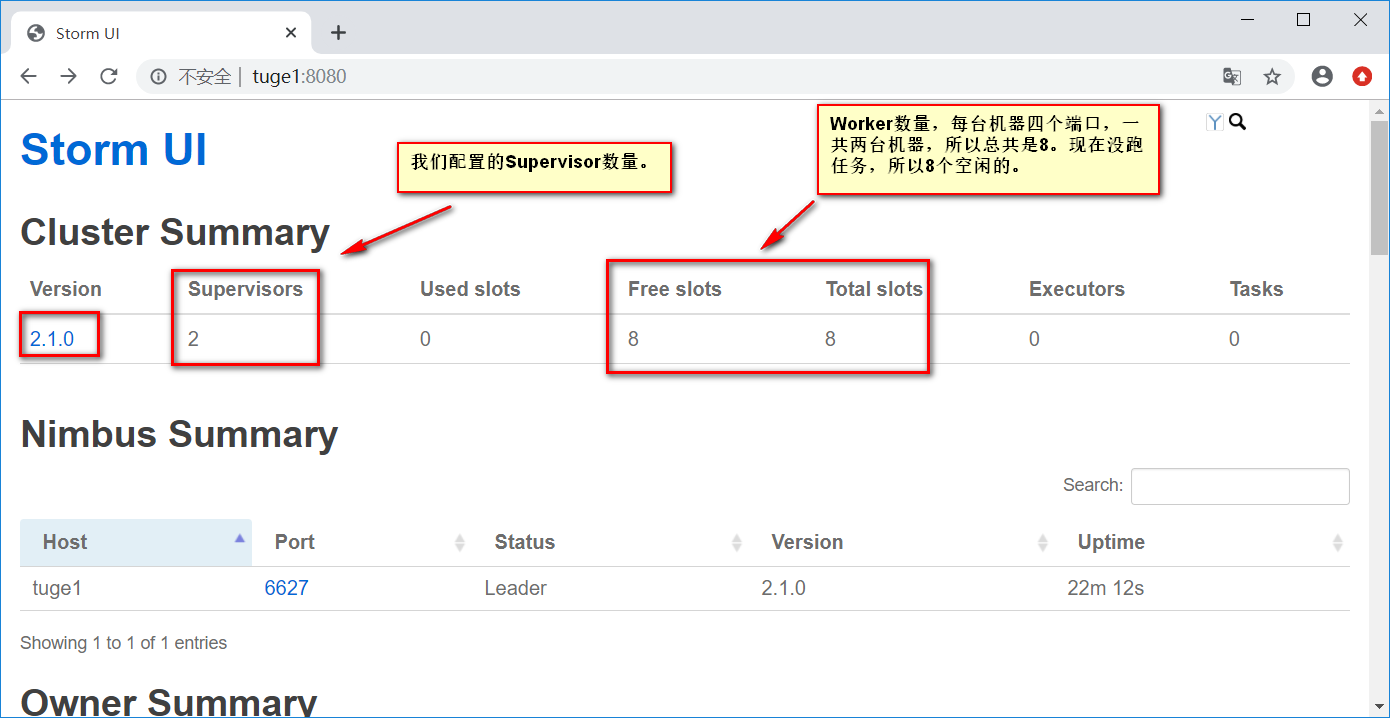
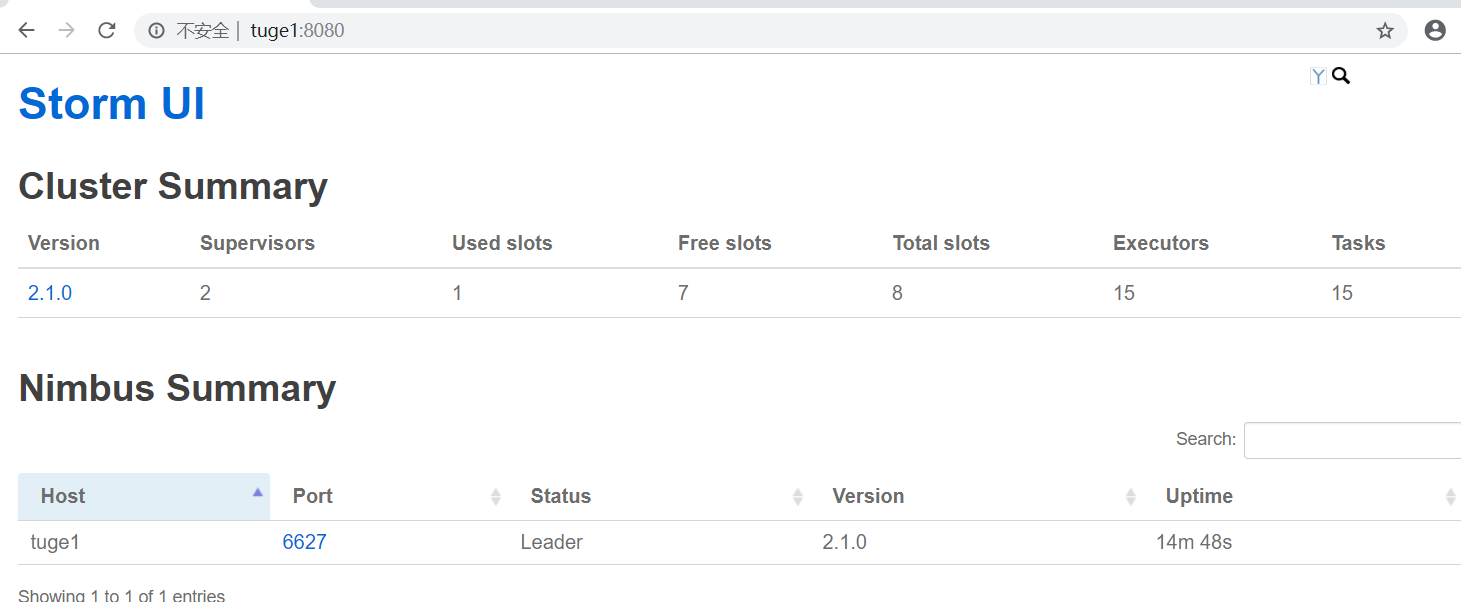
访问ui页面: http://tuge1:8080/
(PS:如果有什么异常的话,看下zookeeper是否启动,另外使用jps看下numbus和supervisor是否启动)
如果报异常:Could not find leader nimbus from seed hosts [tuge1]. Did you specify a valid list of nimbus hosts for config nimbus.seeds?
请进入到zookeeper的bin目录下运行: zkCli.sh,进入到zookeeper控制台,然后删除Storm节点:


注意:delete只能删除不包含子节点的节点,如果要删除的节点包含子节点,使用rmr命令

重启zookeeper节点:
bin/zkServer.sh restart没问题就可以看到如下界面啦~
2.Storm本地运行
下面是一个单词追加内容的小案例:
创建一个Maven项目,然后添加如下类结构:

代码如下(思路可以参考上一篇的架构捋顺):
App.java(入口类):
package Demo.Storm;
import java.util.Map;
import javax.security.auth.login.AppConfigurationEntry;
import javax.security.auth.login.Configuration;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.LocalCluster.LocalTopology;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.thrift.TException;
import org.apache.storm.topology.TopologyBuilder;
import Demo.Storm.TestWordSpout;
/**
* Hello world!
*
*/
public class App {
public static void main(String[] args) {
try {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 6);//6个spout同时运行
builder.setBolt("exclaim1", new ExclamationBolt1(), 2).shuffleGrouping("words");//2个bolt同时运行
builder.setBolt("exclaim2", new ExclamationBolt2(), 2).shuffleGrouping("exclaim1");//2个bolt同时运行
LocalCluster lc = new LocalCluster();//设置本地运行
lc.submitTopology("wordadd", new Config(), builder.createTopology());//提交topology
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
ExclamationBolt1.java(Bolt1):
package Demo.Storm;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class ExclamationBolt1 extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
_collector=collector;
}
public void execute(Tuple input) {
// TODO Auto-generated method stub
String val=input.getStringByField("words")+"!!!";
_collector.emit(input, new Values(val));//input用来标识是哪个bolt
_collector.ack(input);//确认bolt
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("exclaim1"));
}
}
ExclamationBolt2.java(Bolt2):
package Demo.Storm;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
public class ExclamationBolt2 extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this._collector=collector;
}
public void execute(Tuple input) {
// TODO Auto-generated method stub
String str= input.getStringByField("exclaim1")+"~~~";
System.err.println(str);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}
TestWordSpout.java(源源不断传送数据):
package Demo.Storm;
import java.util.Map;
import java.util.Random;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
public class TestWordSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
// TODO Auto-generated method stub
_collector=collector;
}
public void nextTuple() {
// TODO Auto-generated method stub
Utils.sleep(100);
final String[] words = new String[] { "你好啊", "YiMing" };
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];//随机发送字符串
_collector.emit(new Values(word));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("words"));
}
}
pom.xm(maven配置文件,如果问题参考后面介绍):
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Demo</groupId>
<artifactId>Storm</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Storm</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.storm/storm-client -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-client</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.storm/storm-server -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-server</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
</project>
运行效果如下:
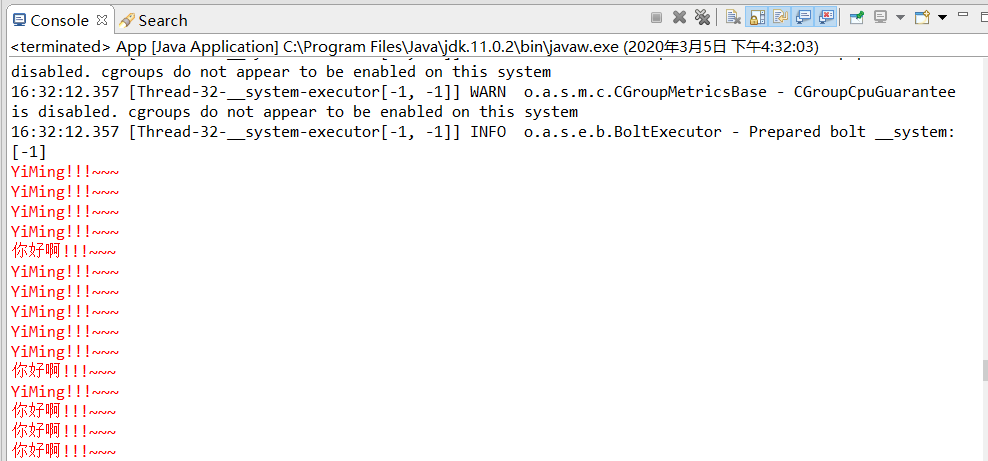
遇到的问题:
问题一:LocalCluster这个类明明存在,却引入不了?
解决: 首先看下和能引入的jar包的区别是,这个jar包是灰色的,一脸懵,估计就是这的事情。然后网上搜了搜为什么有的包是灰色的,果然有答案,原来是pom里面带的 test 导致的,将它删除就OK了,如果还有灰色的,那就干脆一点,将*** 都去掉,要不这是个坑。。。(参考来源)
Storm的八种Grouping策略
1)shuffleGrouping(随机分组)
2)fieldsGrouping(按照字段分组,在这里即是同一个单词只能发送给一个Bolt)
3)allGrouping(广播发送,即每一个Tuple,每一个Bolt都会收到)
4)globalGrouping(全局分组,将Tuple分配到task id值最低的task里面)
5)noneGrouping(随机分派)
6)directGrouping(直接分组,指定Tuple与Bolt的对应发送关系)
7)Local or shuffle Grouping
8)customGrouping (自定义的Grouping)
3.Storm在Linux集群上运行
下面是一个统计单词数量的小案例:
在上面项目基础上继续添加如下类文件,结构如下:

代码如下:
WordCountApp.java(入口类)
package Demo.Storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountApp {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new WordCountSpout(), 8);//8个Spout同时执行
builder.setBolt("wordSplit", new WordCountSplitBolt(), 3).shuffleGrouping("words");//3个Bolt同时执行
builder.setBolt("wordSum", new WordCountSumBolt(), 3).fieldsGrouping("wordSplit", new Fields("word"));//3个Bolt同时执行
if (args.length > 0) {//如果有参数,走集群执行
try {
StormSubmitter.submitTopology(args[0], new Config(), builder.createTopology());
} catch (Exception ex) {
ex.printStackTrace();
}
} else {//没有参数走本机执行
try {
LocalCluster lc = new LocalCluster();
lc.submitTopology("wordCount", new Config(), builder.createTopology());
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
}
WordCountSpout.java(源源不断的提供数据)
package Demo.Storm;
import java.util.Map;
import java.util.Random;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
public class WordCountSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
// TODO Auto-generated method stub
this._collector=collector;
}
public void nextTuple() {
// TODO Auto-generated method stub
Utils.sleep(1000);
String[] words=new String[] {
"hello YiMing",
"nice to meet you"
};
Random r=new Random();
_collector.emit(new Values(words[r.nextInt(words.length)]));//随机传递一个字母
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("words"));
}
}
WordCountSplitBolt.java(分割类)
package Demo.Storm;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class WordCountSplitBolt extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this._collector = collector;
}
//传递分割后的字母
public void execute(Tuple input) {
// TODO Auto-generated method stub
String line=input.getString(0);
String[] lineGroup= line.split(" ");
for(String str:lineGroup) {
List list=new Values(str);
_collector.emit(input, list);
_collector.ack(input);
}
}
//声明传递的字母名称为 word,下一个bolt可以通过此名称获取
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("word"));
}
}
WordCountSumBolt.java(归纳统计类)
package Demo.Storm;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
public class WordCountSumBolt extends BaseRichBolt {
OutputCollector _collector;
Map<String, Integer> map = new HashMap<String, Integer>();
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this._collector = collector;
}
//归纳统计
public void execute(Tuple input) {
// TODO Auto-generated method stub
String word = input.getString(0);
if (map.containsKey(word)) {
map.put(word, (map.get(word) + 1));
} else {
map.put(word, 1);
}
System.err.println("单词:" + word + ",出现:" + map.get(word) + "次");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}
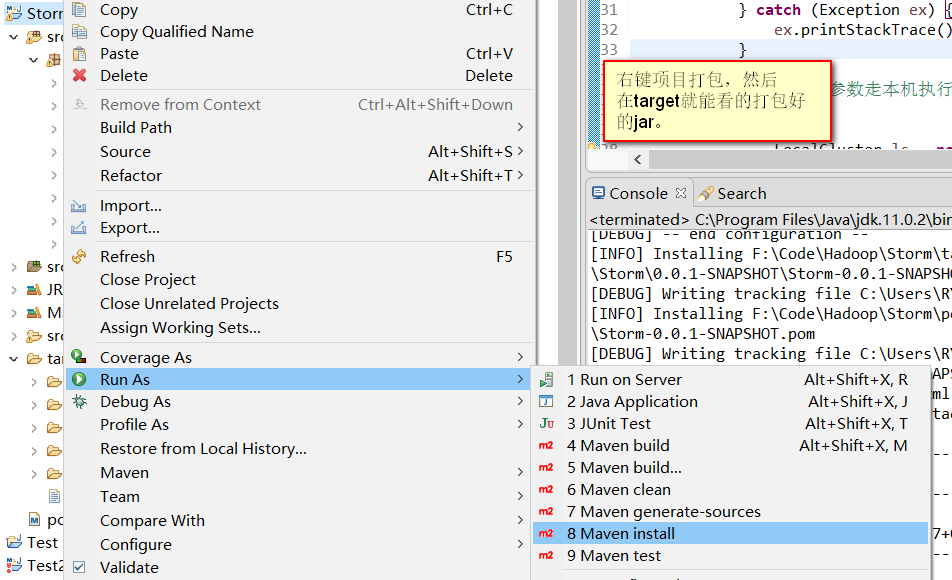
弄好后,编译打包,然后上传到Linux上面。
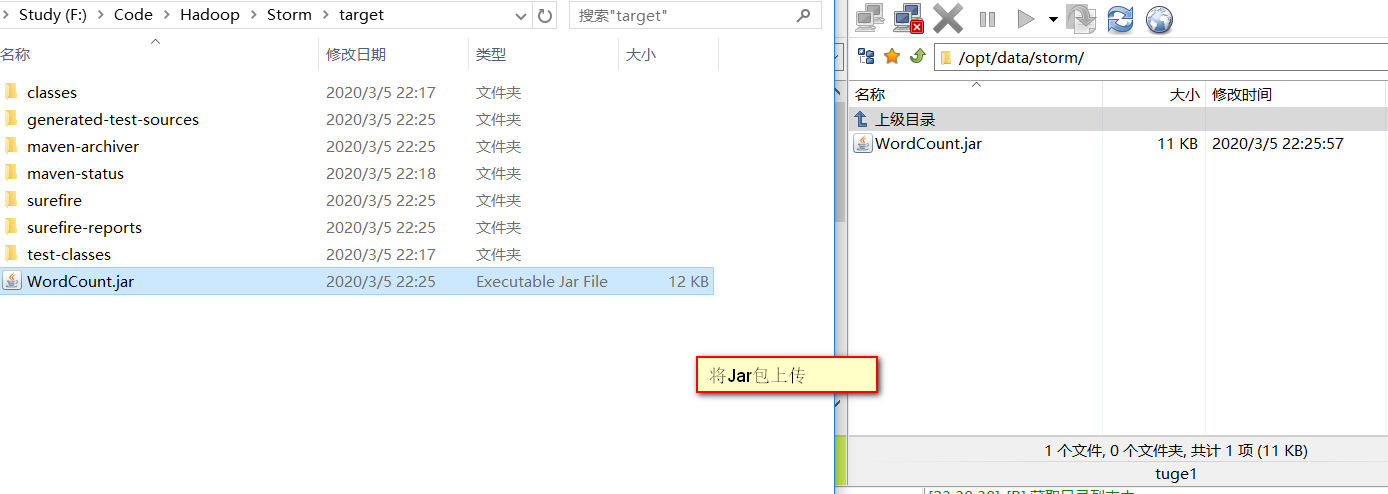
进入到/opt/storm/apache-storm-2.1.0/bin执行
[root@tuge1 bin]# ./storm jar /opt/data/storm/WordCount.jar Demo.Storm.WordCountApp wc
运行官方示例:
storm jar all-my-code.jar org.apache.storm.MyTopology arg1 arg2
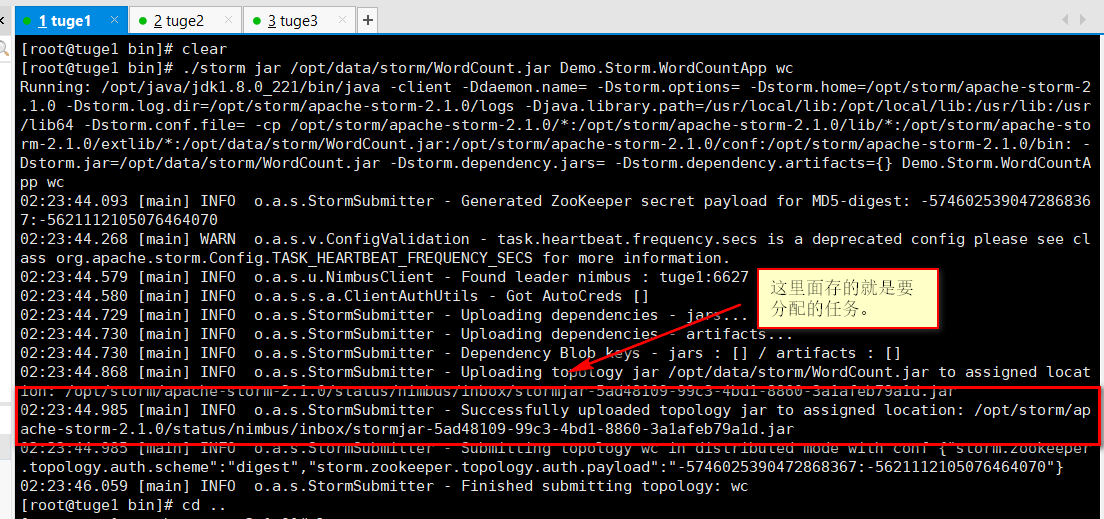
结束任务
storm kill wc(也就是topology名称)
要想获取结果请参考: https://blog.csdn.net/cuihaolong/article/details/52684396
PS:运行过程中,Task不可以改变,但是Worker和Executer可以改变。
zj。。。
入门大数据---Storm搭建与应用的更多相关文章
- 入门大数据---HDFS-HA搭建
一.简述 上一篇了解了Zookeeper和HDFS的一些概念,今天就带大家从头到尾搭建一下,其中遇到的一些坑也顺便记录下. 1.1 搭建的拓扑图如下: 1.2 部署环境:Centos3.1,java1 ...
- 入门大数据---Elasticsearch搭建与应用
项目版本 构建需要: JDK1.7 Elasticsearch2.2.1 junit4.10 log4j1.2.17 spring-context3.2.0.RELEASE spring-core3. ...
- 入门大数据---Hbase搭建
环境介绍 tuge1 tuge2 tuge3 tuge4 NameNode NameNode DataNode DataNode ZooKeeper ZooKeeper ZooKeeper ZooKe ...
- 入门大数据---Kylin搭建与应用
由于Kylin官网已经是中文的了,而且写的很详细,这里就不再重述. 学习右转即可. 这里说个遇到的问题,当在Kylin使用SQL关键字时,要加上双引号,并且里面的内容要大写,这个和MySql有点区别需 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 大数据平台搭建-zookeeper集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- 大数据平台搭建:Hadoop
To construct big data distributed platform based on Hadoop is a common method. Hadoop comes fron Goo ...
随机推荐
- Alpha冲刺 —— 5.4
这个作业属于哪个课程 软件工程 这个作业要求在哪里 团队作业第五次--Alpha冲刺 这个作业的目标 Alpha冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.展 ...
- JVM虚拟机 与 GC 垃圾回收
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.JVM体系结构概述 1.JVM 与系统.硬件 JVM是运行在操作系统之上的,它与硬件没有直接的交 ...
- JAVASE(十六) IO流 :File类、节点流、缓冲流、转换流、编码集、对象流
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.File类型 1.1.File类的理解 File类是在java.io包下 File可以理解成一个文件 ...
- Java实现 LeetCode 面试题13. 机器人的运动范围(DFS)
面试题13. 机器人的运动范围 地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] .一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左.右.上.下移动一格(不能移动 ...
- Java实现 LeetCode 507 完美数
507. 完美数 对于一个 正整数,如果它和除了它自身以外的所有正因子之和相等,我们称它为"完美数". 给定一个 整数 n, 如果他是完美数,返回 True,否则返回 False ...
- Java实现 LeetCode 226 翻转二叉树
226. 翻转二叉树 翻转一棵二叉树. 示例: 输入: 4 / \ 2 7 / \ / \ 1 3 6 9 输出: 4 / \ 7 2 / \ / \ 9 6 3 1 备注: 这个问题是受到 Max ...
- java实现黄金队列
** 黄金队列** 黄金分割数0.618与美学有重要的关系.舞台上报幕员所站的位置大约就是舞台宽度的0.618处,墙上的画像一般也挂在房间高度的0.618处,甚至股票的波动据说也能找到0.618的影子 ...
- Java实现 黑洞数
任意一个5位数,比如:34256,把它的各位数字打乱,重新排列,可以得到一个最大的数:65432,一个最小的数23456.求这两个数字的差,得:41976,把这个数字再次重复上述过程(如果不足5位,则 ...
- Hadoop之hadoop fs和hdfs dfs、hdfs fs三者区别
适用范围 案例 备注 小记 hadoop fs 使用范围最广,对象:可任何对象 hadoop dfs 只HDFS文件系统相关 hdfs fs 只HDFS文件系统相关(包括与 ...
- 滴滴数据驱动利器:AB实验之分组提效
桔妹导读:在各大互联网公司都提倡数据驱动的今天,AB实验是我们进行决策分析的一个重要利器.一次实验过程会包含多个环节,今天主要给大家分享滴滴实验平台在分组环节推出的一种提升分组均匀性的新方法.本文首先 ...