1.String,StringBuffer和StringBuilder有什么区别?
String是字符串常量,不可变对象,每次对String修改都等同于生成了一个新的String象,然后将指针指向新的String对象,经常修改的字符串最好不要用String,因为每次生成的对象都会对系统性能产生影响,特别是当内存中无引用对象多了以后,JVM的GC开始工作,速度会比较慢。
StringBuffer是线程安全的字符串变量,每次修改都是对StringBuffer对象本身进行操作,所以一般推荐使用StringBuffer。在某些特别的情况下。String对象的字符串拼接被JVM解释成了StringBuffer对象的拼接,所以这个时候String对象的速度并不会比StringBuffer慢,就像下面的字符串对象生成
String s1 = "This is only a" + " simple" + " test";
StringBuffer sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
StringBuilder是非线程安全的字符串变量,速度要比StringBuffer更快,在单线程使用情况下,建议优先采用该类。
2.什么是线程安全?
多个线程同时访问某个对象,不管运行时环境采用何种调度方式或者这些线程将如何交替执行,也不需要进行额外的同步,或者在调用方进行任何其他操作,调用这个对象的行文都可以获得正确的结果,那么这个对象就是线程安全的。
3.如何保证线程安全?
Java中提供了synchronized关键字和Lock对象。显式的使用Lock对象相较于synchronized方式代码缺乏优雅,但是对于处理某些问题更加灵活,支持多个相关的Condition对象,在处理异常方面,synchronized如果某些事物失败了,抛出异常,我们没有机会去做任何清理工作。
4.什么是锁、死锁?
锁是多线程中确保共享资源安全的机制。
死锁是指多个任务相互等待,一个任务在等待另一个任务完成,后者又在等在别的任务,一直下去,直到这个链条上的任务又在等待第一个任务释放锁,这样在任务之间相互等待的连续循环,没有哪个线程能够连续。
5.满足死锁的条件是什么?
互斥条件,任务中使用的资源至少有一个是不能共享的。
至少有一个任务持有的一个资源正在等待获取一个当前被别的任务持有的资源。
资源不能被任务抢占,任务必须把资源释放当做普通事件。
有循环等待,任务链相互等待对方释放持有资源。
6.synchronized的实现原理是什么?
当任务要执行被synchronized保护的代码片段的时候,它将检查锁是否可用,然后获取锁、执行代码、释放锁。
7.谈谈volatile关键字
在谈volatile之前,先了解两个东西:原子性和易变性。
“原子操作不需要进行同步控制”这种认知是不正确的。原子操作不能被线程调度机制中断,一但操作开始,那么它一定可以在可能发生上下文切换之前执行完毕。原子性可以应用于long和double之外的所有基本类型之上的简单操作,对于读取和写入除long和double之外的基本类型变量这样的操作,可以保证它们会被当做不可分的操作来操作内存。但是JVM可以将64位(long和double变量)的读取和写入当做两个分离的32位操作来执行,这就产生了一个读物和写入操作中间发生上下文切换,从而导致不同的任务可以看到不正确结果的可能性(这称为字撕裂),但是在定义long和double变量是,使用volatile关键字,就会获得原子性。
在多处理器系统上,可视性的问题要比原子性多得多,一个任务作出的修改,即使在不中断的意义上讲是原子性的,对其他任务也是不可视的,不同任务对应用的状态有着不同的视图。同步机制强制在处理器系统中,一个任务作出的修改必须在应用中是可视的。
如果一个域可能被多个任务同时访问,或者这些任务中至少有一个是写入任务,那么你就应该将这个域设置为volatile。保证原子性,确保应用中的可视性,如果将一个域声明为volatile的,那么只要对这个域产生了写操作,那么所有读操作都可以看到这个修改,即使使用了本地缓存,也是一样的,volatile域会立即被写入到主存中,而读取操作就在主存中。使用volatile替代synchronized的唯一安全的情况是类中只有一个可变的域,其他情况我们的第一选择应该是使用synchronized关键字。
volatile无法工作的情况,一个域的值依赖于它之前的值,或者是某个域的值受到其他域的值的限制。
8.有了synchronized为什么还要使用volatile?
volatile通常被比喻为轻量级的synchronized,通过内存屏障实现保证可见性和有序性。volatile具备了一个synchronized不具备的作用,禁止指令重排序,这一点在双重校验锁实现单例的时候有用,如果不用volatile修饰单例对象,就会存在问题。
9.synchronized怎么进行锁优化?
10.知道JMM吗(原子性,可见性,有序性)?
Java并发采用的是共享内存模型。
Java中的内存模型,隶属于JVM。从抽象角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本。本地内存是一个抽象概念,并不是真实存在。
在JVM内部,Java内存模型把内存分成了两部分:线程栈区和堆区。JVM中运行的每个线程都拥有自己的线程栈,线程栈包含了当前线程执行的方法调用的相关信息,也称为调用栈。
原子性:一个操作过程中不允许其他操作介入,知道该操作完成。在多线程环境下,原子性表现在当前线程执行字节码的过程中不允许切换到其他线程去执行其他的字节码。
可见性:一个线程对主内存的修改可以及时的被其他线程观察到。如果多个线程共享一个对象,没有正确的使用volatile声明或者synchronized同步机制,一个线程更新了共享变量值后,对其他线程来讲是不可见的,这就会导致变量被多次修改。
有序性:在执行过程中,为了提高性能,编译器和处理器常常会对指令做重排序。重排序有几个过程或者说类型
重排序会改变程序的执行结果。Java中的解决办法一个是在指令序列的合适位置插入内存屏障指令来进制特定类型的处理器重排序,让程序按照我们预想的流程去执行。另一种方法就是设置临界区,临界区的代码可以重排序,JMM会在退出临界区和进入临界区这两个关键时间点做特别处理,这种重排序即提高了指向效率,又没有改变程序的执行结果。
11.Java并发包了解吗?
12.什么是fail-fast,什么是fail-safe?
fail-fast:快速失败,在使用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改,就会抛出异常。原理在于迭代器工作期间直接访问集合中的内容,并且在遍历过程中使用一个modCount变量,集合在被遍历器件如果内容发生变化,modCount的值就会被改变,当迭代器使用hashNext()/next()遍历下一个元素时,都会监测modCount变量是否为expectedmodCount值,如果是,返回遍历,否则抛出异常。java.util包下的集合类都是快速失败的,不能再多线程下发生并发修改(迭代过程中被修改)。
fail-safe:安全失败,采用了安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。原理在于遍历是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器监测,不会触发异常。缺点是迭代器并不能访问到修改后的内容。java.util.concurrent包下的容器都是安全失败,可以再多线程下并发使用,并发修改。
13.什么是CopyOnWrite(简称COW)?
加锁之外的保证线程安全的方法
copyonwrite是一种用于程序设计中的优化策略。基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容时,才会真正把内容copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。JDK1.5之后提供了两个使用CopyOnWrite机制实现的并发容器,CopyOnWriteArrayList和CopyOnWriteArraySet。
CopyOnWrite容器:写时复制容器,当我们往一个容器中添加元素时,不直接往当前容器添加,而是现将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,将原容器的引用指向新的容器。这样做的好处就在于可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前的容器并不会添加任何元素,这也是一种读写分离的思想。
CopyOnWrite的应用场景:用于读多写少的并发场景,比如白名单、黑名单、商品类目的访问和更新场景,加入我们有一个搜索网站,用户在这个网站搜索框中,但某些关键字不允许被搜索,这些不能被搜索的关键字会被放在一个黑名单中,黑名单每天晚上更新一次,当用户搜索时,会检查当前关键字在不在黑名单中,如果在,则提示不能搜索。
COW需要注意两件事:一是减少扩容开销,根据实际需要,初始化CopyOnWrite容器的大小,避免写时容器扩容的开销。二是使用批量添加,每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。
缺点:内存占用问题和数据一致性问题。
内存占用问题:因为CopyOnWrite的写时复制机制,所以在进行写操作时,内存中会同时驻扎两个对象的内存,旧的对象和新写入的对象,如果这些对象占用的内存比较大,就会导致系统响应时间变长。可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如将10进制压缩成32或64进制,或者不使用CopyOnWrite,而是其他的并发容器,如ConcurrentHashMap。
数据一致性问题:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。
14.AQS是什么?CAS是什么?
AQS是AbstractQueuedSynchronized的缩写,java.util.concurrent的基础类。提供用于实现阻塞锁和相关依赖先进先出(FIFO)等待队列的同步器(信号灯、事件等)。
CAS是Compare And Swap的缩写,即比较和交换,位于java.util.concurrent.atomic包下,是用于实现多线程同步的原子指令,它将内存位置的内容与给定值进行比较,只有在相同的情况下,将该内存位置的内容修改为新的给定值,视为单个原子操作完成。通过Unsafe类实现,由JVM本地实现。这也是一种比较有名的无锁算法。
15.乐观锁和悲观锁?
乐观锁:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似write_condition机制,其实都是提供的乐观锁,java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿到这个数据就会阻塞知道他拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁、表锁、读锁、写锁等,都是在操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁的缺点:ABA问题,一个变量初次读取是A,在准备赋值的时候检查到它仍然是A值,并不能说明它的值没有被其他线程修改过。循环时间长开销大,自旋CAS(也就是不成功就一直循环执行到成功)如果长时间不成功,会给CPU带来非常大的执行开销。只能保证一个共享变量的原子操作
16.数据库如何实现悲观锁和乐观锁?
16.1 Oracle
悲观锁的实现:使用行级锁,只对想锁定的数据进行锁定,其余的数据不相干,在对oracle表并发插数据的时候基本不会有任何影响。oracle的悲观锁需要利用一条现有的连接,分成两种方式,从SQL语句的区别来看,
select * from test where id = 10 for update;
select * from test where id = 10 for update nowait;
一种是for update,执行了该语句之后,把数据锁住,重新打开一个窗口再执行该语句,会发现第二次执行的没有任何返回结果,如果执行不添加for update的语句就没有问题。
另一种是for update nowait的形式,nowait用于迅速判断当前数据是否被锁中,如果锁定的话,就要采取相应的业务措施进行处理。
oracle的悲观锁就是利用oracle的Connection对数据进行锁定,在oracle中,这种行级锁带来的性能损失是很小的,只要注意程序逻辑,不搞成死锁,而且由于数据的及时锁定,在数据提价时不会出现冲突,可以省去很多恼人的数据冲突处理。缺点是必须要有一条数据库连接,整个锁定到最后放开锁的过程中,我们的数据库连接必须保持。
乐观锁:oracle中有三种做法
第一种是在数据取得的时候把整个数据都copy到应用中,在进行提交的时候比对当前数据库中的数据和开始的时候更新前取得的数据,发现两个数据一模一样以后,就表示没有冲突,可以提交,否则就是并发冲突,需要去用业务逻辑解决。
第二种方法就是版本号机制,这个在Hibernate中得到了使用,采用版本号机制的话,首先需要在有乐观锁的数据库table上建立一个新的column,比如number类型,当数据每更新一次的时候,版本数就网上增加1,。如果有两个session同时操作数据库,两者都取到当前数据的版本号为1,当第一个session进行数据更新后,在提交的时候查到当前数据的版本还为1,和自己一开始取到版本相同,就正式提交,并把版本号加1。
第三种是采用时间戳,方式和第二种差不多。
16.2 Mysql
悲观锁:在我们查询出某条数据之后,就把当前数据锁定,直到我们修改完毕后再解锁,在这个过程中,因为该数据被锁定了,其他的线程不能再对其进行修改。要是用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为mysql默认使用autocommit模式,即执行更新操作之后立马将结果提交,set autocommit=0。同样的可以使用select * from tablename where condition for update;实现悲观锁,condition查出的数据被锁定,其他事务必须等本次事务提交之后才能执行,这样我们可以保证当前数据不会被其他事务修改。
mysql innodb默认row-level lock,只有明确指定主键,才会执行row lock(只锁定被选取的数据),否则mysql将会执行table lock(锁定整个数据表单)。
乐观锁:mysql有两种方式,一种是使用户数据版本机制实现,另一种是通过时间戳比对,和oracle一样。
17.数据库锁又了解吗?行级锁、表级锁、共享锁、排他锁、Record Lock、Gap Lock(间隙锁)、Next-Key Locks?
数据库锁是为了保证数据的一致性。
17.1 表级锁:一次将整个表锁定,好处是 不会出现死锁、开销小、获取锁和释放锁的速度很快。缺点是锁定粒度大,锁冲击概率高,并发度低。使用表级锁的主要是MylSAM、MEMORY、CSV等一些非事务性存储引擎,适用于以查询为主、少量更新的应用。
17.2 页级锁:是mysql中比较独特的一种锁定级别,粒度介于行级锁和表级锁之间,以及开销、并发处理能力也是在两者之间,页级锁和行级锁一样会发生死锁。
17.3 行级锁:锁定指定的数据行,好处是锁定对象的粒度比较小,发生锁冲突的概率低、并发度高。缺点是开销大、加锁慢、容易发生死锁。使用行级锁的主要是InnoDB存储引擎、分布式存储引擎NDBCluster等,使用与对事务完整性要求较高的系统。InnoDB支持行级锁和表级锁,默认为行级锁。
17.4 InnoDB行级锁分为好几种
共享锁:又称为读锁和S锁,简单讲就是多个事务对同一个数据进行共享一把锁,都能访问到数据,但是只能读不能修改。
排他锁:又称为写锁和X锁,排他锁就是不能与其他锁共存,如果一个是事务获取了一个数据行的排他锁,其事务就不能再获取该行的其他锁,只有获取排他锁的事务可以对数据进行读取和修改。
意向锁:是InnoDB自动加的,不需要用户干预,意向锁不会与行级的共享/排他锁互斥。
17.5 其他锁
Record Lock:单挑索引记录上加锁,锁住的仅仅是索引,而非记录本身,即使该表上没有任何索引,InnoDB会在后台创建一个隐藏的聚集主键索引,那么锁住的就是这个隐藏的聚集主键索引,所以说当一条sql没有走任何索引时,那么将会在每一条聚集索引后面家X锁。
Gap Lock:可重复读隔离级别来解决幻读的问题。在索引记录之间的间隙加锁,或者是在某一条所以记录之前或者之后加锁,并不包括该索引记录本身。
Next-Key Locks:默认情况下,mysql的事务隔离级别是可重复度,并且innodb_locks_unsafe_for_binlog参数为0,这是默认曹勇Next-Key Locks。所谓的Next-Key Locks就是Record Lock和Gap Lock的结合,除了锁住记录本身,还锁住索引之间的间隙。
18.数据库锁和隔离级别有什么关系?
18.1 隔离级别
使用select @@tx_isolation;当前数据库的隔离级别。注意mysql8.0之后使用select @@transaction_isolation;或者show variables like 'transaction_isolation';
数据库事务的隔离级别有四个,由低到高依次为Read Uncommitted、Read Committed、Repeatable read、Serializable。
Read Uncommitted:事务最低的隔离级别,他允许另外一个事务可以看到这个事务未提交的数据,这种隔离级别会产生脏读、不可重复读和幻读。
Read Committed:这种隔离级别保证一个事务修改的数据提交后才能被另外一个事务读取,另外的事务不能读取该事务未提交的数据。
Repeatable read:这种隔离级别可以防止脏读、不可重复读,但是可能会产生幻读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免不可重复读的情况。
Serializable:这是代价最高也是最可靠的事务隔离级别,事务被处理为顺序执行,可以防止脏读、不可重复读、幻读。
18.2 锁和隔离级别的关系
事务隔离和锁的关系:事务隔离主要就是对事务的读写之间进行隔离,通过锁实现隔离。
事务隔离级别和锁的关系:通过对事务的读写操作加锁的情况不同,划分不同的事务隔离级别。
19.数据库锁和索引有什么关系?
19.1 索引
索引是对数据库表中一列或者多列的值进行排序的一种结构,使用索引可以快速访问数据表中的特定信息。
19.2 关系
MyISAM操作数据库都是使用表级锁,总是一次性获得所需的全部锁,要么全部满足,要么全部等待,所以不会产生死锁,但是由于每次操作一条记录都要锁定整个表,导致性能低,并发不高。
InnoDB则有很大的不同,一是支持事务,二是才用了行级锁。
在Mysql中,行级锁并不是直接锁定记录,而是锁索引,InnoDB行锁是通过给索引加锁实现的,索引分为主键索引和非主键索引两种,如果一条语句操作了主键索引,Mysql就会锁定这条主键索引,如果一条语句操作了非主键索引,Mysql会先锁定该非主键索引,再锁定相关的主键索引。如果没有索引,InnoDB会通过隐藏的聚簇索引来对记录加锁,即InnoDB将对表中所有的数据加锁,实际效果跟表级锁一样。
19.3 索引失效的情况
单独引用复合索引里非第一位置的索引,对索引进行运算(+、-、*、/、<>、%、like'%_'、or、in、exist等),对索引使用内部函数,类型错误(表中字段类型和sql中的查询条件的类型不一样),索引列没有限制not null。
20.什么是聚簇索引?非聚簇索引?最左前缀是什么?B+树索引?联合索引?回表?
聚簇索引:表中行的物理顺序与键值的逻辑(索引)顺序相同,一个表中只能包含一个聚簇索引。
非聚簇索引:表中记录的物理顺与索引顺序可以不相同,一个表中只能有一个聚簇索引,但是表中的每一列都可以有自己的非聚簇索引,在数据访问速度上要逊色与聚簇索引。
最左前缀:从左向右的顺序建立搜索树
B+树索引:
联合索引:两个或多个列上的索引
回表:在查询中根据索引(非主键)找到了指定的记录所在行后,还需要根据主键再次到数据块里获取数据
21.什么是分布式锁?
是控制分布式系统之间同步访问共享资源的一种方式,通过互斥来保证数据一致性。
22.redis怎么实现分布式锁?
/**Jedis对象中有这样一个方法,可以进行加锁nxxx,expx对象
*NX:只有这个key不存才的时候才会进行操作,if not exists;
*EX:设置key的过期时间为秒,具体时间由第5个参数决定
*/
public String set(final String key, final String value, final String nxxx, final String expx,
final long time) {
checkIsInMultiOrPipeline();
client.set(key, value, nxxx, expx, time);
return client.getStatusCodeReply();
}
23.为什么要用redis?
redis的五种数据结构:String、Hash、List、Set、Sorted Set。
使用redis从两个方面考虑:性能和并发
性能:从缓存中读取要比从mysql或者oracle中更快
并发:在大并发情况下,所有的请求直接访问数据库,数据库会出现连接异常,这个时候需要使用redis做一个缓冲操作
24.redis、mongodb、memcache区别是什么?
性能:都比较高,TPS redis和memcache差不多,要大于mongodb
内存空间的大小和数据量的大小:redis增加了自己的VM特性,突破物理内存的限制,可以对key value设置过期时间;memecache可以修改最大可用内存,采用LRU算法;mongodb适合大数据两的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起。
操作便利性:memcache数据结构单一;redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数;mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富。
可用性:单点问题redis依靠客户端实现分布式读写,主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制,因性能和效率问题,依赖程序设定一直的hash机制,替代方案是使用主动复制;memcache本身没有数据冗余机制,对于故障预防,采用依赖成熟的hash或者环状的算法。
25.Zookeeper怎么实现分布式锁?
26.什么是Zookeeper?
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
27.什么是CAP?
CAP定理又被称为布鲁尔定理
| C |
一致性Consistence |
分布式环境中,一致性指的是多个副本之间是够能够保持一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作之后,应该保证系统数据仍然处于一致的状态。 |
| A |
可用性Availability |
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。 |
| P |
分区容错性Partition tolerance |
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务。除非是整个网络环境都发生故障了。 |
三者不能同时满足
| CA |
如果存在异地DB,保证C需要双写,DB0同步到DB1的过程网络有问题,则一直挂起,P不满足 |
| AP |
异地DB,主从同步完成,AP满足,但是C不满足 |
| CP |
异地DB,必须同步双写,DB0同步到DB1过程网络有问题,则一直挂起,A不满足 |
28.什么是BASE?和CAP有什么区别?
BASE理论是对CAP理论的延伸,思想是即使无法做到强一致性,但可以采用适当的弱一致性,即最终一致性。
| 基本可用Basically Available |
指分布式系统在出现故障时,允许损失部分可用性,例如相应时间、功能上的可用性,允许损失部分可用性。 |
| 软状态Soft State |
指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不用副本同步的延时就是软状态的体现。Mysql replication的一步复制也是一种体现。 |
| 最终一致性Eventual Consistency |
指系统中的所有数据副本经过一定时间后,最终达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。 |
29.CAP如何推导,如何取舍?
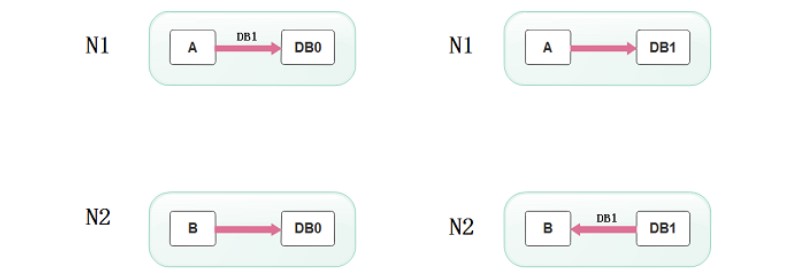
假设有两台服务器,一台放着应用A和数据库V,一台放着应用B和数据库V,他们之间的网络可以互通,也就相当于分布式系统的两个部分。
在满足一致性的时候,两台服务器 N1和N2,一开始两台服务器的数据是一样的,DB0=DB0。在满足可用性的时候,用户不管是请求N1或者N2,都会得到立即响应。在满足分区容错性的情况下,N1和N2有任何一方宕机,或者网络不通的时候,都不会影响N1和N2彼此之间的正常运作。
当用户通过N1中的A应用请求数据更新到服务器DB0后,这时N1中的服务器DB0变为DB1,通过分布式系统的数据同步更新操作,N2服务器中的数据库V0也更新为了DB1,这时,用户通过B向数据库发起请求得到的数据就是即时更新后的数据DB1。
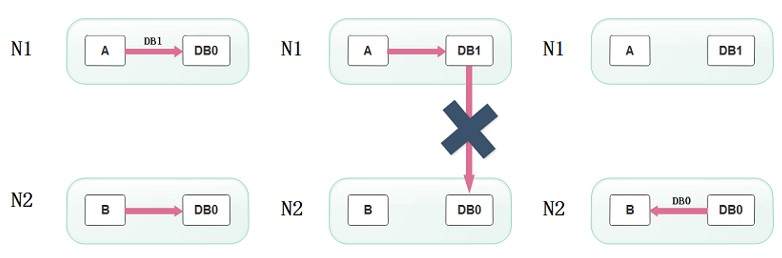
上面是正常运作的情况,但分布式系统中,最大的问题就是网络传输问题,现在假设一种极端情况,N1和N2之间的网络断开了,但我们仍要支持这种网络异常,也就是满足分区容错性,那么这样能不能同时满足一致性和可用性呢?
假设N1和N2之间通信的时候网络突然出现故障,有用户向N1发送数据更新请求,那N1中的数据DB0将被更新为DB1,由于网络是断开的,N2中的数据库仍旧是DB0;
如果这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据DB1,怎么办呢?有二种选择,第一,牺牲数据一致性,响应旧的数据DB0给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作完成之后,再给用户响应最新的数据DB1。
取舍策略:
| CP |
放弃P,不允许分区,也意味着放弃了系统的扩展性,分布式节点首先,这违背了分布式系统设计的初衷 |
| CP |
放弃A,不要求可用,每个请求都需要在服务器之间保持强一致,而P会导致同步时间无限延长,一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,必须等待所有数据全部一致之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。 |
| AP |
放弃C,不要求一致性,要求高可用和允许分区。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,这样会导致全局数据的不一致性。 |
30.分布式系统如何保证数据一致性?
31.啥是分布事务?分布式事务方案?
分布式事务:指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点上。简单点说就是一次大操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上,分布式事务就是为了保证不同数据库的数据一致性。
分布式解决方案:
| 2PC |
数据库中分布式事务中的XA Transactions,事务管理器要求每个涉及到事务的数据库预提交,反映是否可以提交,然后事务协调器要求每个数据库提交数据或者回滚数据 |
| TCC |
|
| 本地消息表 |
|
| MQ事务 |
|
| Saga事务 |
|
- 金九银十,史上最强 Java 面试题整理。
以下会重新整理所有 Java 系列面试题答案.及各大互联网公司的面试经验,会从以下几个方面汇总,本文会长期更新. Java 面试篇 史上最全 Java 面试题,带全部答案 史上最全 69 道 Spri ...
- 2020最常见的200+Java面试题汇总(含答案解析)
前言 2020年快要结束了,很多朋友问题,有没有整理今年的一些面试题,最近抽时间整理了一份Java面试题.或许这份面试题还不足以囊括所有 Java 问题,但有了它,我相信足以应对目前市面上绝大部分的 ...
- 509道Java面试题解析:2020年最新Java面试题
<Java面试全解析>是我在 GitChat 发布的一门电子书,全书总共有 15 万字和 505 道 Java 面试题解析,目前来说应该是最实用和最全的 Java 面试题解析了. 我本人是 ...
- 2020年大厂Java面试题(基础+框架+系统架构+分布式+实战)
前言 作为一个Java开发者,Java架构师应该是大家的一个职业目标了吧. 要成为Java架构师,首先你要是一个高级Java工程师,熟练使用各种框架,并知道它们实现的原理.jvm虚拟机原理.调优,懂得 ...
- 新鲜出炉!2020年最新java面试题大全,面试突击必备!
前言 发现网上很多Java面试题都没有答案,所以花了很长时间搜集整理出来了一套Java面试题,希望对大家有帮助哈~ 打算这几天每天更新15~20题.(这样有助于你们阅读和理解!)我们先从简单的开始 1 ...
- java面试题及答案(转载)
JAVA相关基础知识1.面向对象的特征有哪些方面 1.抽象:抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面.抽象并不打算了解全部问题,而只是选择其中的一部分,暂时 ...
- Java笔试题解答和部分面试题
面试类 银行类的问题 问题一:在多线程环境中使用HashMap会有什么问题?在什么情况下使用get()方法会产生无限循环? HashMap本身没有什么问题,有没有问题取决于你是如何使用它的.比如,你 ...
- 2016最新Java笔试题集锦
更新时间:2015-08-13 来源:网络 投诉删除 [看准网(Kanzhun.com)]笔试题目频道小编搜集的范文“2016最新Java笔试题集锦”,供大家阅读参考, ...
- 来自投资银行的20个Java面试题
问题一:在多线程环境中使用HashMap会有什么问题?在什么情况下使用get()方法会产生无限循环? HashMap本身没有什么问题,有没有问题取决于你是如何使用它的.比如,你在一个线程里初始化了一个 ...
随机推荐
- ACM-ICPC 2019 山东省省赛D Game on a Graph
Game on a Graph Time Limit: 1 Second Memory Limit: 65536 KB There are people playing a game on a con ...
- 数学--数论--HDU 2674 沙雕题
WhereIsHeroFrom: Zty, what are you doing ? Zty: I want to calculate N!.. WhereIsHeroFrom: So easy! H ...
- 谷歌浏览器的F12用处及问题筛查笔记
在前端测试功能的时候,经常有些莫名其妙的错误,这个时候开发会说打开F12看一下吧,所以感觉这个开发者功能很有用,研究一下,做如下记录: Elements:左栏以DOM树形式查看网页源代码(HTML), ...
- swupdate 之 readback handler
背景 使用 swupdate 作为 OTA 方案 ,有项目要求在写入数据到分区之后需要再次读出校验. 初步实现:readout-verify attribute 初步分析有两种方式 方案一 在每一笔数 ...
- 报错:Maven创建An internal error occurred during: "Retrieving archetypes:". Java heap space
在Eclipse中创建Maven的Web项目时出现错误:An internal error occurred during: "Retrieving archetypes:". J ...
- 王颖奇 20171010129《面向对象程序设计(java)》第十五周学习总结
实验十五 GUI编程练习与应用程序部署 实验时间 2018-12-6 学习总结: 理论部分: ◼ JAR文件◼ 应用程序首选项存储◼ Java Web Start JAR文件: 1.Java程序的打 ...
- Excel+Python:分组求和
Excel选中区域,排除序号.姓名等列,复制Ctrl+C. Python,import pandas as pd,读取剪切板并赋值给变量df,df.groupby('部门').sum().若要避免部门 ...
- [NBUT 1458 Teemo]区间第k大问题,划分树
裸的区间第k大问题,划分树搞起. #pragma comment(linker, "/STACK:10240000") #include <map> #include ...
- [CodeForces 300C Beautiful Numbers]组合计数
题意:十进制的每一位仅由a和b组成的数是“X数”,求长度为n,各数位上的数的和是X数的X数的个数 思路:由于总的位数为n,每一位只能是a或b,令a有p个,则b有(n-p)个,如果 a*p+b*(n-p ...
- js移动端复制到剪贴板
// 复制到剪切板 function copy(str){ var save = function (e){ e.clipboardData.setData('text/plain',str);//c ...