Hadoop HDFS负载均衡
Hadoop HDFS负载均衡
转载请注明出处:http://www.cnblogs.com/BYRans/
Hadoop HDFS
Hadoop 分布式文件系统(Hadoop Distributed File System),简称 HDFS,被设计成适合运行在通用硬件上的分布式文件系统。它和现有的分布式文件系统有很多的共同点。HDFS 是一个高容错性的文件系统,提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS副本摆放策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
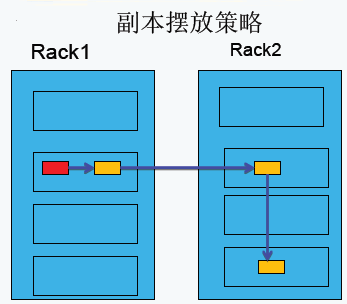
需要注意的是:
- HDFS中存储的文件的副本数由上传文件时设置的副本数决定。无论以后怎么更改系统副本系数,这个文件的副本数都不会改变;
- 在上传文件时优先使用启动命令中指定的副本数,如果启动命令中没有指定则使用hdfs-site.xml中dfs.replication设置的默认值;
HDFS负载均衡
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,例如:当集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值。当数据不平衡时,Map任务可能会分配到没有存储数据的机器,这将导致网络带宽的消耗,也无法很好的进行本地计算。
当HDFS负载不均衡时,需要对HDFS进行数据的负载均衡调整,即对各节点机器上数据的存储分布进行调整。从而,让数据均匀的分布在各个DataNode上,均衡IO性能,防止热点的发生。进行数据的负载均衡调整,必须要满足如下原则:
- 数据平衡不能导致数据块减少,数据块备份丢失
- 管理员可以中止数据平衡进程
- 每次移动的数据量以及占用的网络资源,必须是可控的
- 数据均衡过程,不能影响namenode的正常工作
Hadoop HDFS数据负载均衡原理
数据均衡过程的核心是一个数据均衡算法,该数据均衡算法将不断迭代数据均衡逻辑,直至集群内数据均衡为止。该数据均衡算法每次迭代的逻辑如下:
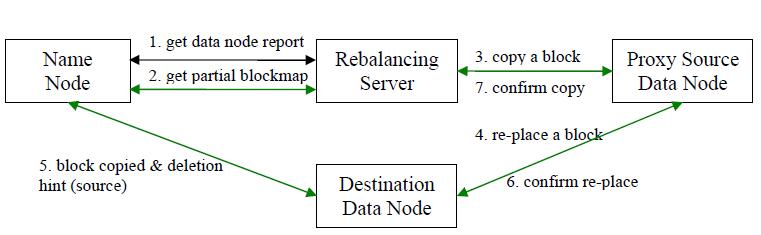
步骤分析如下:
- 数据均衡服务(Rebalancing Server)首先要求 NameNode 生成 DataNode 数据分布分析报告,获取每个DataNode磁盘使用情况
- Rebalancing Server汇总需要移动的数据分布情况,计算具体数据块迁移路线图。数据块迁移路线图,确保网络内最短路径
- 开始数据块迁移任务,Proxy Source Data Node复制一块需要移动数据块
- 将复制的数据块复制到目标DataNode上
- 删除原始数据块
- 目标DataNode向Proxy Source Data Node确认该数据块迁移完成
- Proxy Source Data Node向Rebalancing Server确认本次数据块迁移完成。然后继续执行这个过程,直至集群达到数据均衡标准
**DataNode分组**
在第2步中,HDFS会把当前的DataNode节点,根据阈值的设定情况划分到Over、Above、Below、Under四个组中。在移动数据块的时候,Over组、Above组中的块向Below组、Under组移动。四个组定义如下:
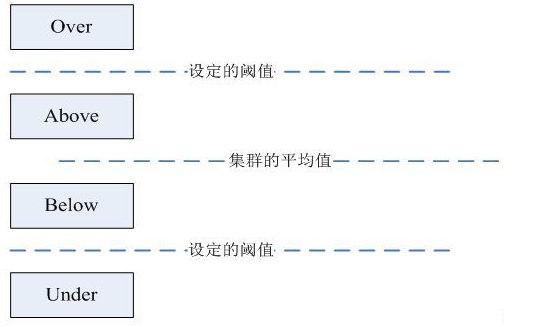
- Over组:此组中的DataNode的均满足
DataNode_usedSpace_percent > Cluster_usedSpace_percent + threshold
- Above组:此组中的DataNode的均满足
Cluster_usedSpace_percent + threshold > DataNode_ usedSpace _percent > Cluster_usedSpace_percent
- Below组:此组中的DataNode的均满足
Cluster_usedSpace_percent > DataNode_ usedSpace_percent > Cluster_ usedSpace_percent – threshold
- Under组:此组中的DataNode的均满足
Cluster_usedSpace_percent – threshold > DataNode_usedSpace_percent
Hadoop HDFS 数据自动平衡脚本使用方法
在Hadoop中,包含一个start-balancer.sh脚本,通过运行这个工具,启动HDFS数据均衡服务。该工具可以做到热插拔,即无须重启计算机和 Hadoop 服务。\(Hadoop_Home/bin 目录下的 start-balancer.sh 脚本就是该任务的启动脚本。
启动命令为:`\)Hadoop_home/bin/start-balancer.sh –threshold`
影响Balancer的几个参数:
- -threshold
- 默认设置:10,参数取值范围:0-100
- 参数含义:判断集群是否平衡的阈值。理论上,该参数设置的越小,整个集群就越平衡
- dfs.balance.bandwidthPerSec
- 默认设置:1048576(1M/S)
- 参数含义:Balancer运行时允许占用的带宽
示例如下:
#启动数据均衡,默认阈值为 10%
$Hadoop_home/bin/start-balancer.sh
#启动数据均衡,阈值 5%
bin/start-balancer.sh –threshold 5
#停止数据均衡
$Hadoop_home/bin/stop-balancer.sh
在hdfs-site.xml文件中可以设置数据均衡占用的网络带宽限制
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description>
</property>
Hadoop HDFS负载均衡的更多相关文章
- HDFS副本机制&负载均衡&机架感知&访问方式&健壮性&删除恢复机制&HDFS缺点
副本机制 1.副本摆放策略 第一副本:放置在上传文件的DataNode上:如果是集群外提交,则随机挑选一台磁盘不太慢.CPU不太忙的节点上:第二副本:放置在于第一个副本不同的机架的节点上:第三副本:与 ...
- HDFS 02 - HDFS 的机制:副本机制、机架感知机制、负载均衡机制
目录 1 - HDFS 的副本机制 2 - HDFS 的机架感知机制 3 - HDFS 的负载均衡机制 参考资料 版权声明 1 - HDFS 的副本机制 HDFS 中的文件,在物理上都是以分块(blo ...
- Hbase负载均衡流程以及源码
hmater负责把region均匀到各个region server .hmaster中有一个线程任务是专门处理负责均衡的,默认每隔5分钟执行一次. 每次负载均衡操作可以分为两步: 生成负载均衡计划表 ...
- Flume负载均衡配置
flume负载均衡配置 集群DNS配置如下: hadoop-maser 192.168.177.162 machine-0192.168.177.158 machine-1191.168.177.16 ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- 大数据高并发系统架构实战方案(LVS负载均衡、Nginx、共享存储、海量数据、队列缓存)
课程简介: 随着互联网的发展,高并发.大数据量的网站要求越来越高.而这些高要求都是基础的技术和细节组合而成的.本课程就从实际案例出发给大家原景重现高并发架构常用技术点及详细演练. 通过该课程的学习,普 ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
- 企业高并发的成熟解决方案(一)----搭建LVS负载均衡
企业整个架构分析 1. App服务器上边部署应用,如果是java的话,一般是tomcat: 2. 负载均衡服务器负责转发请求,这种既有主机又有备机的负载均衡成为高可用(HA): 3. 一般web服务器 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
随机推荐
- HTML特殊符号汇总
较常用的飘黄处理了 ´ ´ © © > > µ µ ® ® & & ° ° ¡ ¡ » » ¦ ¦ ÷ ÷ ¿ ¿ ¬ ¬ § § • • ½ ½ « « ¶ ¶ ¨ ...
- 使用、支持、帮助Moon.Orm
1.关于Moon.Orm的说明 1)任何人和组织都可以免费使用该框架;(赞助者提供长期的技术咨询) 微信微信: 2)5.0之前已经全部开源; 3)5.0标准版本目前对参与者开源(看看下面很简单的), ...
- 【原创】HDFS介绍
一. HDFS简介 1. HDFS全称 Hadoop Distributed FileSystem,Hadoop分布式文件系统. Hadoop有一个抽象文件系统的概念,Ha ...
- node.js操作mysql数据库之增删改查
安装mysql模块 npm install mysql 数据库准备 mysql server所在的机器IP地址是192.168.0.108,登录账户就用root@123456 在mysql中创建tes ...
- Tomcat 8080端口被占用解决方法
使用lsof命令查看端口占用情况 sudo lsof -i:8080 端口占用情况 java 1564 tomcat8 50u IPv6 19336 0t0 TCP *:http-alt (LISTE ...
- [moka同学摘录]SQL内联、外联的简单理解
(源自:http://blog.csdn.net/kkk9127/article/details/1487686) --查询分析器中执行:--建表table1,table2:create table ...
- SOA实践之基于服务总线的设计
在上文中,主要介绍了SOA的概念,什么叫做“服务”,“服务”应该具备哪些特性.本篇中,我将介绍SOA的一种很常见的设计实践--基于服务总线的设计. 基于服务总线的设计 基于总线的设计,借鉴了计算机内部 ...
- 全文检索学习历程目录结构(Lucene、ElasticSearch)
1.目录 (1) Apache Lucene(全文检索引擎)—创建索引:http://www.cnblogs.com/hanyinglong/p/5387816.html (2) Apache Luc ...
- Three.js外部模型加载
1. 首先我们要在官网: https://threejs.org/ 下载我们three.js压缩包,并将其中的build文件夹下的three.js通过script标签对的src属性导入到我们的页面中 ...
- jQuery拖拽改变元素大小
一个非常简单的例子,体验效果:http://keleyi.com/keleyi/phtml/jqtexiao/29.htm 以下是完整代码,保存到HTML文件打开也可以体验效果. <!DOCTY ...