es--es分词的一些分析技巧
查看某个字段的分词结果
POST /index/tyhpe/id/_termvectors?fields=fields_name
例如:http://localhost:9200/prod_membermodel/membermodel/80/_termvectors?fields=nickName
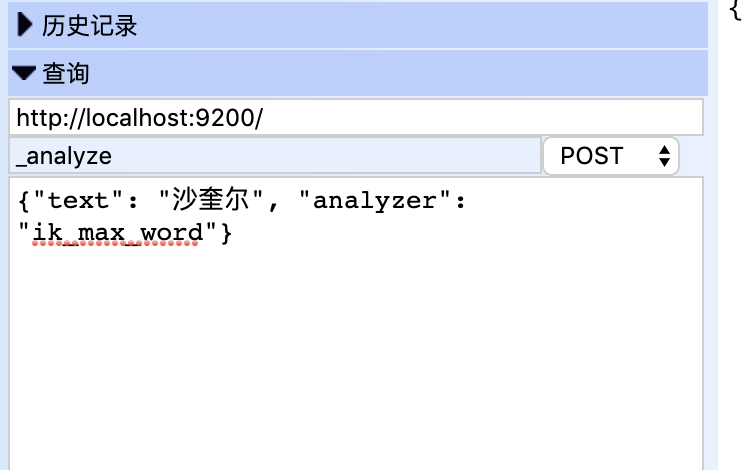
_analyze查看分词结果
前缀搜索
{
"query": {
"bool": {
"should": [
{
"match_phrase_prefix": {
"nickName": {
"query": "10040",
"slop": 5,
"max_expansions": 20
}
}
},
{
"match_phrase_prefix": {
"userId": {
"query": "10040",
"slop": 5,
"max_expansions": 20
}
}
},
{
"match_phrase_prefix": {
"nickName.stand": {
"query": "10040",
"slop": 5,
"max_expansions": 20
}
}
},
{
"multi_match": {
"query": "10040",
"type": "most_fields",
"fields": [
"nickName",
"nickName.stand",
"userId"
]
}
}
]
}
},
"sort": {
"_score": {
"order": "desc"
},
"video": {
"order": "desc"
}
},
"size": 12,
"from": 0
}
通配符搜索
{
"query": {
"bool": {
"should": [
{
"wildcard": {
"nickName":"*kura*"
},
},
{
"wildcard": {
"userId": "*kura*"
},
},
{
"wildcard": {
"nickName.stand": "*kura*"
},
},
{
"multi_match": {
"query": "kura",
"type": "most_fields",
"fields": [
"nickName",
"nickName.stand",
"userId"
]
}
}
]
}
},
"sort": {
"_score": {
"order": "desc"
},
"video": {
"order": "desc"
}
},
"size": 12,
"from": 0
}
es--es分词的一些分析技巧的更多相关文章
- [ES]elasticsearch章5 ES的分词(二)
Elasticsearch 中文搜索时遇到几个问题: 当搜索关键词如:“人民币”时,如果分词将“人民币”分成“人”,“民”,“币”三个单字,那么搜索该关键词会匹配到很多包含该单字的无关内容,但是如果将 ...
- [ES]elasticsearch章5 ES的分词(一)
初次接触 Elasticsearch 的同学经常会遇到分词相关的难题,比如如下这些场景: 1.为什么明明有包含搜索关键词的文档,但结果里面就没有相关文档呢? 2.我存进去的文档到底被分成哪些词(ter ...
- Elasticsearch(ES)分词器的那些事儿
1. 概述 分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引. 今天我们就来聊聊分词器的相关知识. 2. 内置 ...
- ES中文分词器之精确短语匹配(解决了match_phrase匹配不全的问题)
分词器选择 调研了几种分词器,例如IK分词器,ansj分词器,mmseg分词器,发现IK的分词效果最好.举个例子: 词:<<是的>><span>哈<\span ...
- R语言重要数据集分析研究—— 数据集本身的分析技巧
数据集本身的分析技巧 作者:王立敏 文章来源:网络 1.数据集 数据集,又称为资料集.数据集合或资料集合,是一种由数据所组成的集合. Data set(或dat ...
- ES ik分词器使用技巧
match查询会将查询词分词,然后对分词的结果进行term查询. 然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只 ...
- es之分词器和分析器
Elasticsearch这种全文搜索引擎,会用某种算法对建立的文档进行分析,从文档中提取出有效信息(Token) 对于es来说,有内置的分析器(Analyzer)和分词器(Tokenizer) 1: ...
- ES 中文分词
一.大名鼎鼎的中文插件IK的安装配置 1. 在插件目录中建立IK的目录 mkdir $ES_HOME/plugins/analysis-ik 2. 下载IK 的类库jar 文件到IK目录 cd $ES ...
- es ik分词插件安装
1.ik下载(下载es对应版本的ik分词包) https://github.com/medcl/elasticsearch-analysis-ik/releases 2.mac cd /usr/loc ...
随机推荐
- Robotutor Scratch3.0 在线编程平台上线!
终于,Scratch3.0在线编程平台上线了,不容易阿! 欢迎试用 https://scratch.robotutor.cn 欢迎交流,WeChat ID: iamlinweidong
- Gorm 预加载及输出处理(二)- 查询输出处理
上一篇<Gorm 预加载及输出处理(一)- 预加载应用>中留下的三个问题: 如何自定义输出结构,只输出指定字段? 如何自定义字段名,并去掉空值字段? 如何自定义时间格式? 这一篇先解决前两 ...
- Nginx配置Web项目(多页面应用,单页面应用)
目前前端项目 可分两种: 多页面应用,单页面应用. 单页面应用 入口是一个html文件,页面路由由js控制,动态往html页面插入DOM. 多页面应用 是由多个html文件组成,浏览器访问的是对应服务 ...
- Swift 4.0 高级-自定义操作符
在Swift语言中,常见的操作符有+.-.*./.>.<.==.&&.||等等,如果不喜欢,你也可以定义自己喜欢的操作符. 操作符类型 中置运算符(infix operat ...
- swagger 报 i.s.m.parameters.AbstractSerializableParameter - Illegal DefaultValue null for parameter type integer java.lang.NumberFormatException: For input string
解决 方法 添加这两个依赖....别问我有啥子用....我也不知道..能解决问题 <dependency> <groupId>io.swagger</groupId> ...
- 【转】Typora极简教程
Typora极简教程 Typora download ” Markdown 是一种轻量级标记语言,创始人是约翰·格鲁伯(John Gruber).它允许人们 “使用易读易写的纯文本格式编写文档,然后转 ...
- ASP.NET Core去掉HTTPS配置和SSL证书
如果你的项目一不小心配置了https 右击项目=>属性=>调试=>启用SSL=>选择去掉 测试
- android studio 添加 apache.http
- AAAI 2020 | DIoU和CIoU:IoU在目标检测中的正确打开方式
论文提出了IoU-based的DIoU loss和CIoU loss,以及建议使用DIoU-NMS替换经典的NMS方法,充分地利用IoU的特性进行优化.并且方法能够简单地迁移到现有的算法中带来性能的提 ...
- python编写“求最大值”
# 求最大值 def large(*num): # 定义一个large函数,函数的参数为可变参数 ma = num[0] # 初始化最大值 for n in num: if ma < n: # ...